




 本文探讨了在BI前端如何处理大计算量SQL进行多维分析,通过缓存结果集提高响应速度。介绍了对大结果集SQL的缓存优化,包括使用二进制格式代替txt格式以减少加载时间,并展示了在大报表中展示大结果集明细的解决方案,以避免内存溢出问题。
本文探讨了在BI前端如何处理大计算量SQL进行多维分析,通过缓存结果集提高响应速度。介绍了对大结果集SQL的缓存优化,包括使用二进制格式代替txt格式以减少加载时间,并展示了在大报表中展示大结果集明细的解决方案,以避免内存溢出问题。
实践目标
体验较大计算量和较大结果集SQL在多维分析中的响应表现,用缓存方式提高响应速度;多维分析的报表中展示大量明细数据时,用大报表技术避免耗用过多内存、甚至内存溢出。
大计算量SQL做多维分析
下面这个SQL查询出平均工资最高的五万员工,需要大表employees(30万条)、salaries(284万条)关联、做分组汇总、最后按平均工资排序:
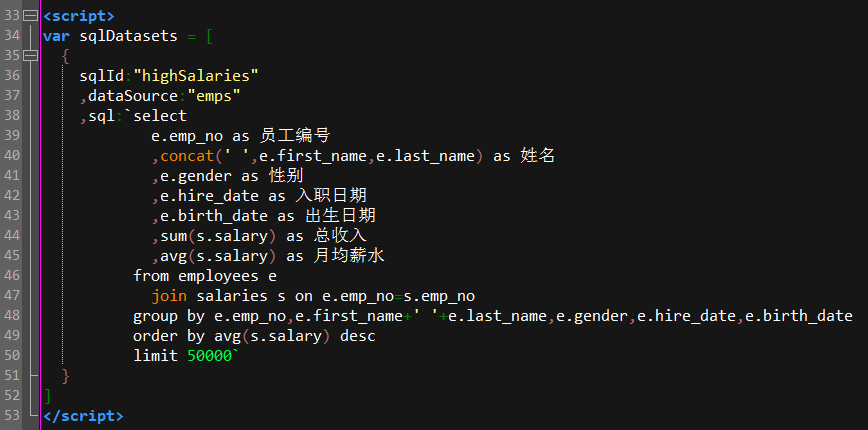
页面在60秒之后才显示出结果:
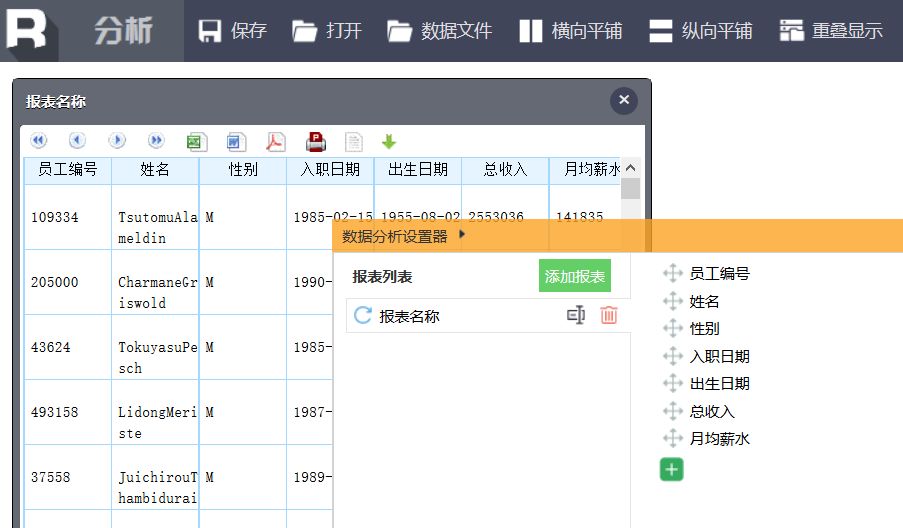
把性别拖到左表头上,统计这五万人中男、女性员工各有多少,这个动作仍然需要等待60秒才会显示结果,原因是每次分析动作,都会基于原始SQL拼一个更大的嵌套SQL去数据库执行,原始SQL慢就决定了每个分析动作都会慢。
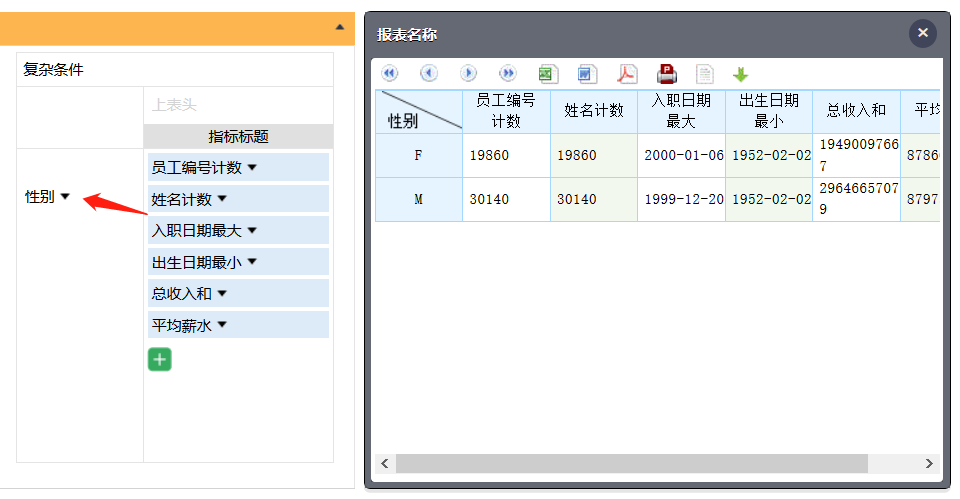
对大计算量SQL结果缓存,避免频繁执行
把上面这个大计算量的SQL,换成Tablib属性方式设置,就会对SQL结果集进行缓存,第一次展示页面时,因为要去数据库查询仍然会慢,但之后再做各种多维分析动作,就立即响应,达到了对SQL结果集缓存、复用的效果:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









