






 本文探讨了OpenCompass2.0在评估语言和多模态大模型时面临的挑战,包括全面性要求、高评测成本、数据污染以及模型鲁棒性问题。文章还介绍了不同类型的模型(基座模型和对话模型)以及评测方式(主观和客观评测)。
本文探讨了OpenCompass2.0在评估语言和多模态大模型时面临的挑战,包括全面性要求、高评测成本、数据污染以及模型鲁棒性问题。文章还介绍了不同类型的模型(基座模型和对话模型)以及评测方式(主观和客观评测)。
大模型评测(OpenCompass)
大模型评测中的挑战:
1. 全面性要求
2. 评测成本高,例如人工主观评测成本极高
3. 数据污染
4. 鲁棒性,例如大模型对提示词非常敏感
OpenCompass 2.0

本算法库的主要评测对象为语言大模型与多模态大模型。我们以语言大模型为例介绍评测的具体模型类型。
- 基座模型:一般是经过海量的文本数据以自监督学习的方式进行训练获得的模型(如OpenAI的GPT-3,Meta的LLaMA),往往具有强大的文字续写能力。
- 对话模型:一般是在的基座模型的基础上,经过指令微调或人类偏好对齐获得的模型(如OpenAI的ChatGPT、上海人工智能实验室的书生·浦语),能理解人类指令,具有较强的对话能力。
如何评测大模型
模型类别:基座模型;对话模型;公开权重的开源模型;API模型
评测方式:主观评测;客观评测

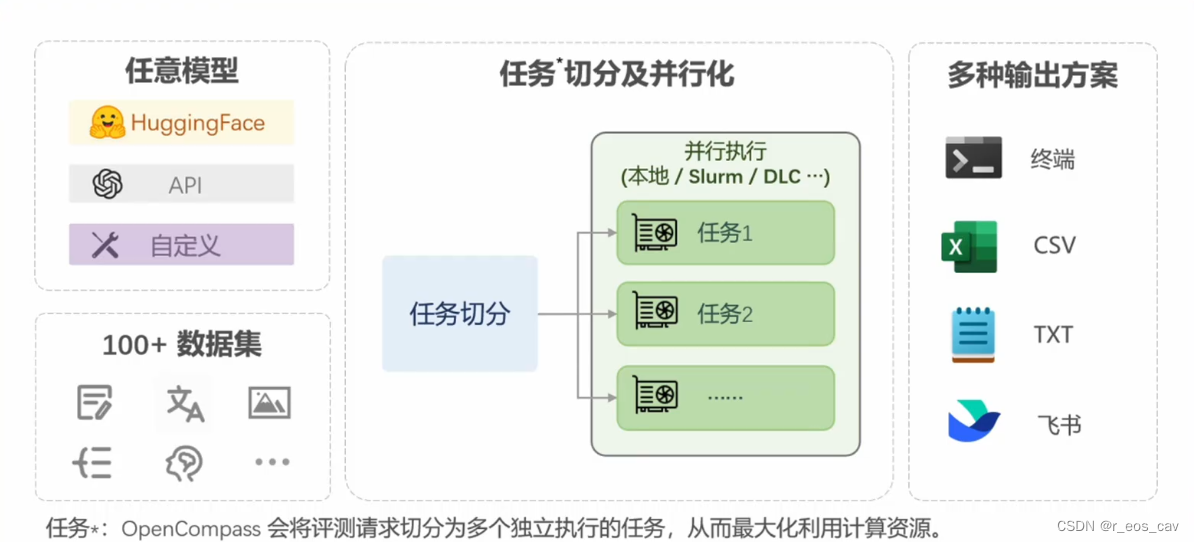
OpenCompass评测流水线

















 2056
2056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









