







 本文深入解析机器学习中ROC曲线、AUC、PR曲线、mAP等关键评估指标的计算方法与优缺点,对比ROC与PR曲线适用场景,探讨多标签分类问题的评价指标,适合初学者及进阶者阅读。
本文深入解析机器学习中ROC曲线、AUC、PR曲线、mAP等关键评估指标的计算方法与优缺点,对比ROC与PR曲线适用场景,探讨多标签分类问题的评价指标,适合初学者及进阶者阅读。
目录
ROC曲线是怎么画的?
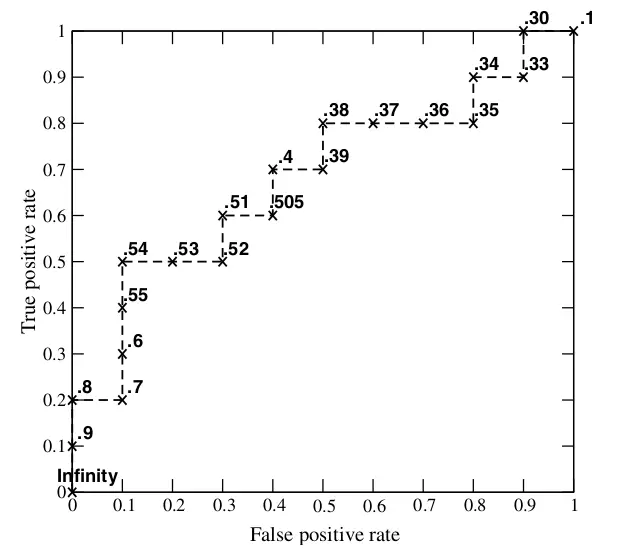
ROC曲线:
1. 评价二分类重要手段,横轴为FPR,纵轴为TPR。

FPR:错误预测为正的比例 = 错误预测为正 / 所有应该预测为负
TPR:正确预测为正的比例 = 正确预测为正 / 所有应该预测为正
所有应该预测为负(所有负样本)包含:正确预测为负(TN),错误预测为正(FP)
所有应该预测为正(所有正样本)包含:正确预测为正(TP),错误预测为负(FN)
2. 曲线越接近左上角,分类器性能越好。对角线对应的是随机猜测,ROC曲线一般都处于对角线上方,如果不是的话,将模型预测概率p反转为1-p就可以得到更好的分类器。
左上角:TPR=1,FPR=0,所有应该预测为正的都预测为正了(错误预测为负FN的为0,即所有预测为负的都是正确预测为负,都是TN),所有不应该预测为正的都没有预测为正(错误预测为正的FP为0,即所有预测为正的都是正确预测为正,都是TP)。
AUC
3. 曲线下方的面积(AUC):
对角线:预测为正和预测为负的概率相等,无论实际类别是正还是负。
AUC在0.5-1之间
AUC的物理意义:反映分类器对样本的排序能力,曲线一般在对角线上方,所以TPR>FPR,正确预测为正的概率 大于 错误预测为正的 概率,AUC越大表明:分类器越可能把真正的正样本排在前面(预测概率越大),分类性能越好
4. ROC曲线是怎么绘制的?
1)指定一个概率阈值,大于(或大于等于)阈值的被判定为正,小于等于(或小于)的被判定为负;
2)每个阈值对应一个TPR和一个FPR,即对应ROC曲线上的一个点,阈值从小到大(0->1)的过程就对应着曲线从右上角(全分为正,TPR=FPR=1) 到 左下角 (全分为负,TPR=FPR=0)的绘制过程
5. ROC曲线的作用和优点
作用:量化地反映基于ROC曲线衡量的二分类模型性能
优点:AUC同时考虑了模型对于正负样本的分类能力;正负样本分布发生变化时,ROC曲线形状基本不变(PR曲线会剧烈变化);能尽量降低不同测试集带来的干扰,更加客观地衡量模型的性能。样本不均衡的测试集通常用AUC来评价分类器性能
补充:
FNR:
TNR:
PR曲线
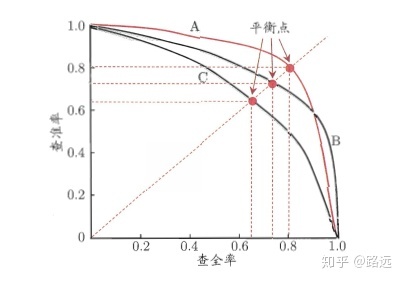
横轴 Recall, 纵轴 Precision
P(Precision):TP/(TP+FP),分母为所有预测为正的样本
R(Recall):TP/(TP+FN),分母为所有正样本
P和R相互矛盾,为了找到平衡点,引入了f1 score,取平衡,让两者同时最高。两个模型的PR曲线相交时,常用 f1 score来比较 二者性能
- F1分数 (f1 score) :P和R的调和平均值
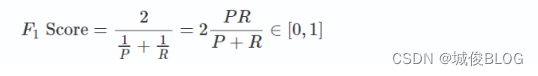
优点:同时考虑P和R,取一个平衡
缺点:P高R低 和 P低R高 的两个模型,f1 score差不多,无法区分
mAP是怎么计算得到的?
AP:PR曲线下的面积,分类器越好,AP越高
mAP:多个类别AP的平均值,即所有类别的AP求和 / 类别总数。mAP的大小一定在[0,1]区间,越大越好。
Recall, Precision, AP, mAP的计算方法(看一次就懂系列)_recall计算_#苦行僧的博客-优快云博客
CV基础MX recall map_mxdet map_城俊BLOG的博客-优快云博客
多标签分类问题评价指标
综合 准确率 和 平衡准确率的 度量:
- 准确率:预测正确的结果所占的比例
accuracy = (TP+TN) / ALL,从公式上能看出precision 和 accuracy的区别
优点:能衡量分对的结果占比
缺点:样本不均衡情况下,不能作为很好的衡量指标。例如测试集正样本较多,全部预测为正样本就能得到比较高的准确率。
- Balanced Accuracy
优点:多标签分类评价指标(metric):BAcc:1/2 * (tp/Np+tn/Nn),使用BAcc,相比于Acc,能缓解分布不平衡带来的评价不准确,减轻过拟合结果对评价的影响。
缺点:在某些数据分布情况下,BAcc指标可能超过Acc,更不能反映模型的实际预测偏差。甚至预测偏差越大,Bacc越高:
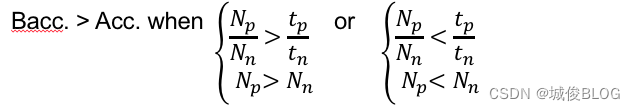
例如:
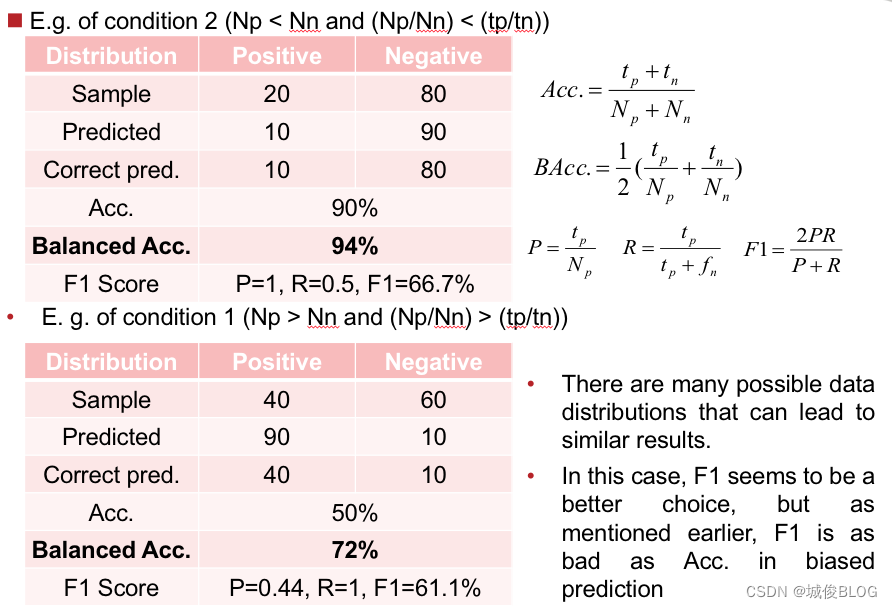
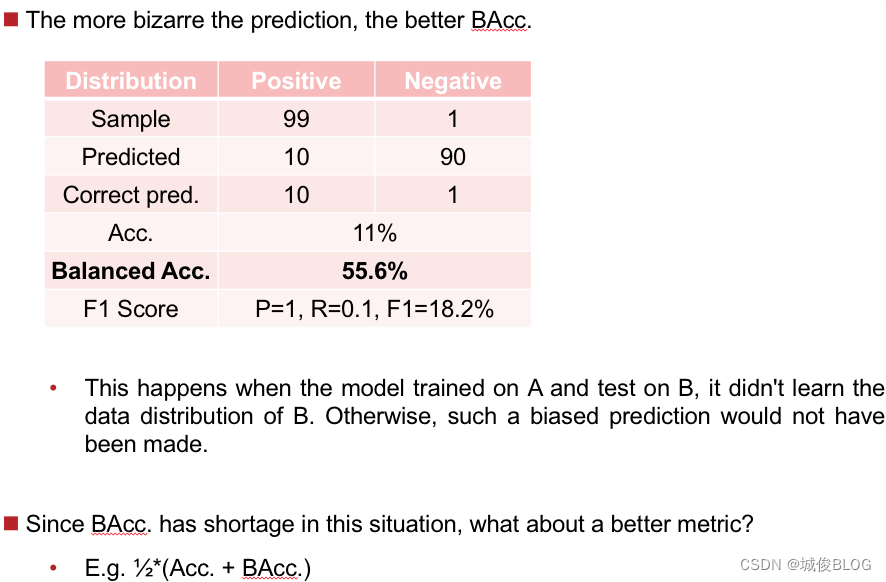
此时 acc. / Bacc. 都不是很好的衡量手段,是否可以考虑 Acc. 和 BAcc. 的算数平均?
PR曲线和ROC曲线优缺点对比和适用场景
两种曲线优缺点和适用场景:
ROC曲线
优点:兼顾正样本(TPR)和负样本(FPR),不容易受到正负样本分布变化的影响。TPR中的TP和FN同属于P,FPR中的FP和TN同属于N,所以P或N的整体数量变化不会影响另一个坐标轴,即P和N的比例发生大的变化时,曲线不会变化很大,具有鲁棒性,同一个模型在不同测试集上能得到相似的ROC曲线
缺点:优点也是缺点,负样本增加很多,曲线没有变,等于产生了大量的FP,如果目标是重点关注正样本的准确性,则不可接受。负样本增多至远大于正样本时,FPR增长不明显,此时大量负样本被判为正样本但在曲线上无法直观看出来,曲线估计效果过于乐观。对于非常看重accuracy的任务影响很大
PR曲线:
优点:P和R都关注正样本,当类别不平衡问题中主要关心正样本时,PR曲线优于ROC曲线
缺点:当类别不平衡问题中主要关注分类器性能时,ROC曲线优于PR曲线,PR曲线会因为测试集样本分布变化而变化较大,同一个模型在不同测试集上PR曲线相差较大
适用场景:
1. 如果要衡量分类器整体性能(兼顾正负样本),选择ROC;如果聚焦正样本,选择PR
2. 如果有多个测试集且分布不同,选择ROC;如果测试不同测试集分布对分类器性能影响,选择PR
3. 类别不平衡问题中,ROC估计过于乐观,常用PR
评估指标Accuracy、ROC曲线和PR曲线的优缺点 - 知乎(含PR、ROC实现代码)
PR曲线、ROC曲线、AUC、AP简单梳理_pr曲线的面积_吾宁的博客-优快云博客
引用:https://blog.youkuaiyun.com/wwangfabei1989/article/details/80656668
Adjusted R square: 调整后的r2,是对r2进行惩罚,也是越大越好。(但不限于0-1之间?)
适用于多元回归,当样本属性个数增加的时候。用r2不适合评价回归效果了。
R-squared(值范围0-1)描述的 输入变量对输出变量的解释程度。在单变量线性回归中R-squared 越大,说明拟合程度越好。
然而只要曾加了更多的变量,无论增加的变量是否和输出变量存在关系,则R-squared 要么保持不变,要么增加。
So, 需要adjusted R-squared ,它会对那些增加的且不会改善模型效果的变量增加一个惩罚向。
结论,如果单变量线性回归,则使用 R-squared评估,多变量,则使用adjusted R-squared。
在单变量线性回归中,R-squared和adjusted R-squared是一致的。
另外,如果增加更多无意义的变量,则R-squared 和adjusted R-squared之间的差距会越来越大,Adjusted R-squared会下降。但是如果加入的特征值是显著的,则adjusted R-squared也会上升

















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









