




 本文详细介绍了Pandas库的基础使用方法,包括数据框创建、数据筛选、数据排序、数据值设置及缺失值处理等核心功能,是进行数据分析与处理的必备技能。
本文详细介绍了Pandas库的基础使用方法,包括数据框创建、数据筛选、数据排序、数据值设置及缺失值处理等核心功能,是进行数据分析与处理的必备技能。
目录
pandas的基础用法:
| s = pd.Series([1,3,6,np.NaN,44,1]) print(s) | 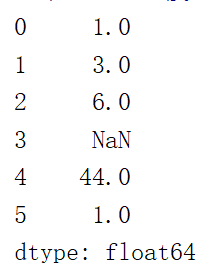 |
dates = pd.date_range('20181203',periods=6)
print(dates) |  |
dates = pd.date_range('20181203',periods=7)
date_df = pd.DataFrame(np.random.randn(7,4),index=dates,columns=['a','b','c','d'])
print(date_df) | 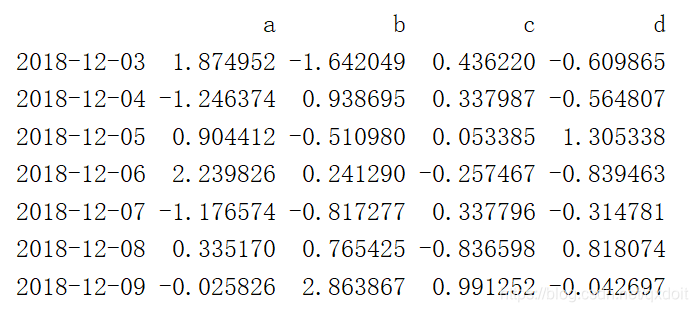 |
df1 = pd.DataFrame(np.arange(12).reshape(3,4)) print(df1) |  |
df = pd.DataFrame({'A':1,
'B':[1,2,3],
'C':'hello'})
print(df)
|  |
df = pd.DataFrame({'A':1,
'B':[1,2,3],
'C':'hello'})
print(df.dtypes)
print(df.index)
print(df.columns)
print(df.values) |  |
df = pd.DataFrame({'A':1,
'B':[1,2,3],
'C':'hello'})
print(df)
df = df.sort_index(axis=1,ascending=False)
print(df) |  |
df = pd.DataFrame({'A':1,
'B':[1,2,3],
'C':'hello'})
print(df)
df = df.sort_values(by='B',ascending=False)
print(df) |  |
pandas 选择数据
dates = pd.date_range('20180101',periods=6)
print(dates)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
print(df) | 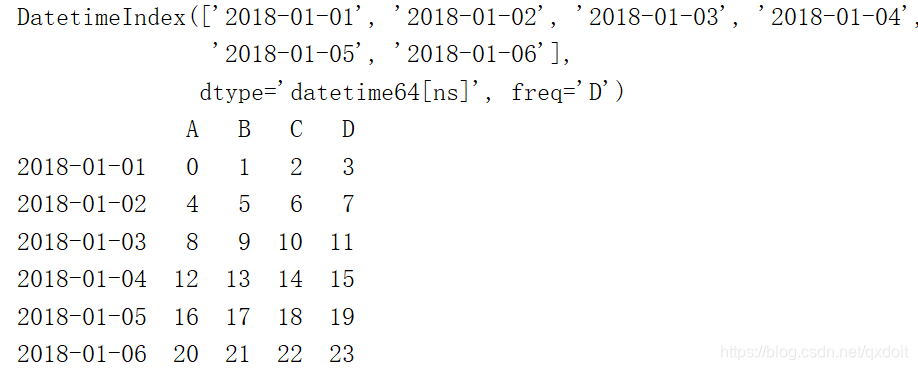 |
#按列选择元素 print(df.A,df['A']) | 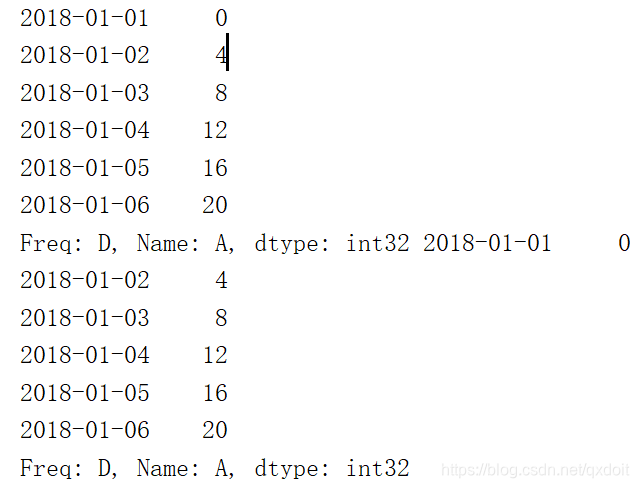 |
| #按行选择元素 print(df[0:3],df['20180103':'20180105']) |  |
#按照lable 选择元素,既可以按照index又可以按照列属性 print(df.loc['20180102']) print(df.loc[:,['B']]) | 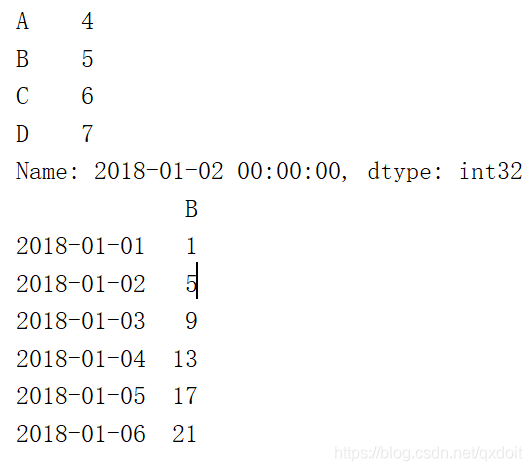 |
#select by position print(df.iloc[1]) print(df.iloc[:,1]) print(df.iloc[1:3,1:3]) | 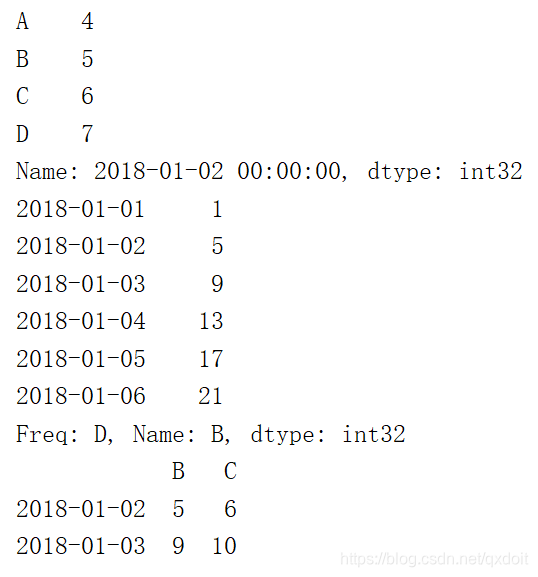 |
#mixed selection,既可以按照标签,又可以按照position print(df.ix[:,'B']) |  |
#boolean indexing print(df.A>8) print(df[df.A>8]) print(df.loc[df.A>8]) | 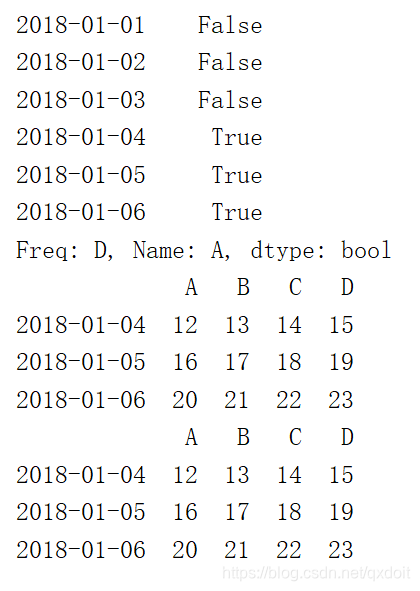 |
pandas 设置值和处理丢失值
dates = pd.date_range('20180101',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
df.A[df.A>12] = 5
print(df) | 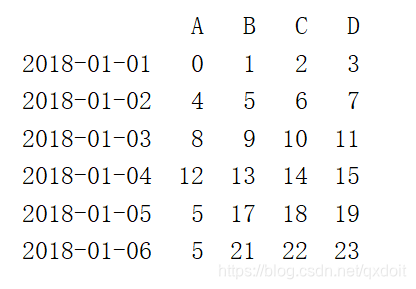 |
dates = pd.date_range('20180101',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
df[df.A>12] = 5
print(df) | 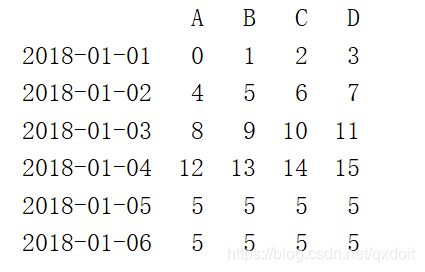 |
dates = pd.date_range('20180101',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
df.iloc[0,1] = np.NaN
df.iloc[1,2] = np.NaN
print(df)
#按行丢掉,how={'any','all'} 'all' 为只有该行全部为nan才丢掉该行
print(df.dropna(axis=0,how='any')) | 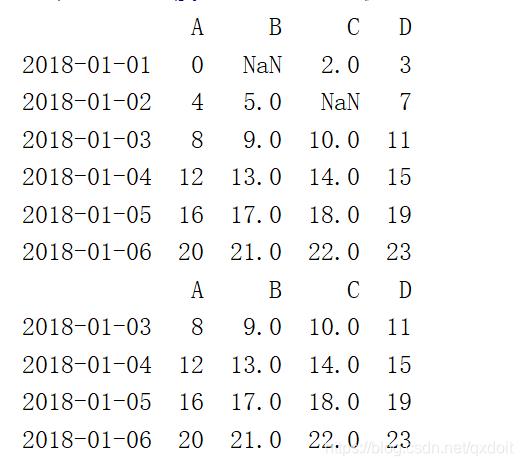 |
dates = pd.date_range('20180101',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
df.iloc[0,1] = np.NaN
df.iloc[1,2] = np.NaN
print(df)
col_mean = df.mean()
#mean 为:该列的和/该列不为nan的总数
print(col_mean)
print(df.fillna(value=col_mean))
| 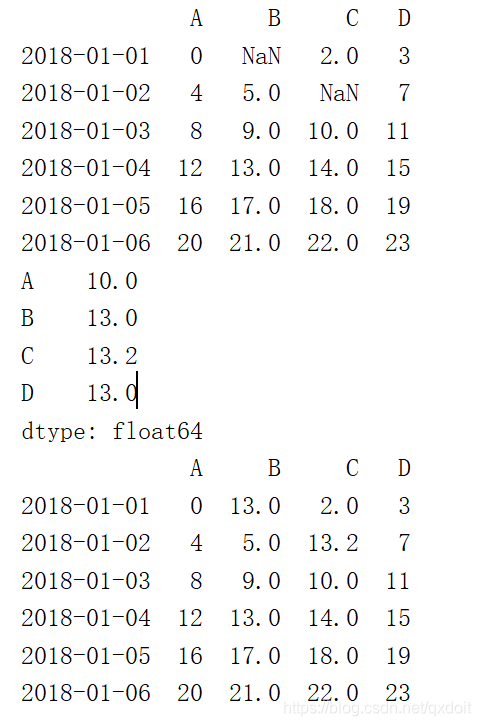 |
print(np.any(df.isnull())==True) | 如果df 里面没有NAN值了,输出为false,只要有一个NAN,输出就是True |
| df 在fillna 后一定要重新赋值 df = df.fillna(value=col_mean) | |

















 1089
1089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









