







1. 假设现在 一个输入有 n 帧, 每一帧有 k 个可能 softmax 是 将这个问题看作一个 n 个 k 分类问题
crf 则将这个问题看作是一个 k**n 问题
从 k**n 条路径中选择一条最佳路径
具体来说 ,在 CRF 序列标注问题中,为了得到从输入到每个预测标签的最大预测概率,为了得到这个概率的估计
CRF 做了两个假设
假设1, 该分布是指数分布

其中 Z 是归一化因子,和 输入 x 有关,f 函数可以看作是一个打分函数,打分函数取指数并归一化后就得到概率分布
假设2,输出之间的关联,仅发生在相邻位置,并且关联是指数加性的
这意味着 f(y1,...,yn;x) 可以进一步简化为:
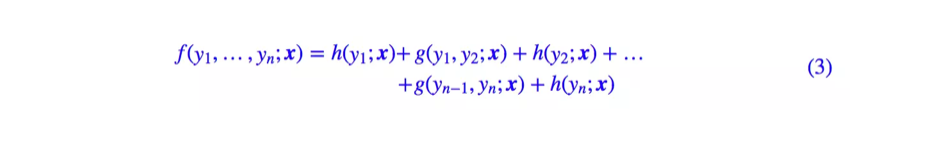
也就是说,我们只需要对每一个标签和每一个相邻标签进行分别打分,然后将所有打分结果求和得到总分
线性链 CRF
尽管已经做了大量的简化,但是3 公式,所表示的概率模型还是过于复杂,难于求解,考虑到当前深度学习模型中,RNN 或者 层叠 CNN 等模型已经能够比较充分捕捉各个 y 与 输出 x 的联系,因此,我们不妨考虑函数 g 和 x 无关
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2642
2642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









