







一、计算图结构
1.1 节点之间
节点之间有两种不同的边:
- 实线:
刻画了数据传输,边上箭头方向表达了数据传输的方向,边上标注了张量的维度信息:比如?x784表明batch大小不固定。效果图上边的粗细表示传输的标量维度总大小,而不是传输的标量个数,当维度无法确定,使用最细的边来表示。 - 虚线:
虚边表达了计算之间的依赖关系。
1.2 主图、辅图
TensorBoard 会智能调整可视效果图上节点,TensorFlow 部分计算节点会有比较多的依赖关系,如果全部画在一张图上会使可视化得到的效果图非常拥挤。于是TensorBoard将Tensorflow计算图分成了主图( Main Graph)和辅助图 (Auxiliary nodes)
二、节点信息
使用TensorBoard可以非常直观地展现所有Tensorflow计算节点在某一次运行时消耗的时间和内存。
三、监控指标可视化
监控指标见下图:
3.1 tf.summary.histogram
查看张量的分布情况。
3.1.1 示例代码
import tensorflow as tf
import numpy as np
class Model:
def __init__(self):
with tf.variable_scope("input"):
self.input = tf.placeholder(shape=[None, 128], dtype=tf.float32)
self.output = tf.placeholder(shape=[None], dtype=tf.int32)
self.global_step = tf.train.get_or_create_global_step()
with tf.variable_scope("fc_layers"):
mid_out = tf.layers.dense(inputs=self.input, units=64, activation=tf.nn.sigmoid)
tf.summary.histogram("dense1_output", mid_out)
final_out = tf.layers.dense(inputs=mid_out, units=10)
tf.summary.histogram("dense2_output", final_out)
with tf.variable_scope("train_op"):
self.loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=self.output, logits=final_out)
self.op = tf.train.AdamOptimizer().minimize(self.loss)
with tf.variable_scope("summary_mertic"):
self.merged = tf.summary.merge_all()
if __name__ == "__main__":
X = np.random.normal(size=[32, 128])
y = np.random.randint(low=0, high=10, size=[32])
model = Model()
summary_writer = tf.summary.FileWriter("./", tf.get_default_graph())
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(10000):
_, loss, summary_node, global_step = sess.run([model.op, model.loss, model.merged, model.global_step],
feed_dict={model.input: X, model.output: y})
summary_writer.add_summary(summary_node, global_step)
3.1.2 对应图片
先看下图-HISTOGRAMS
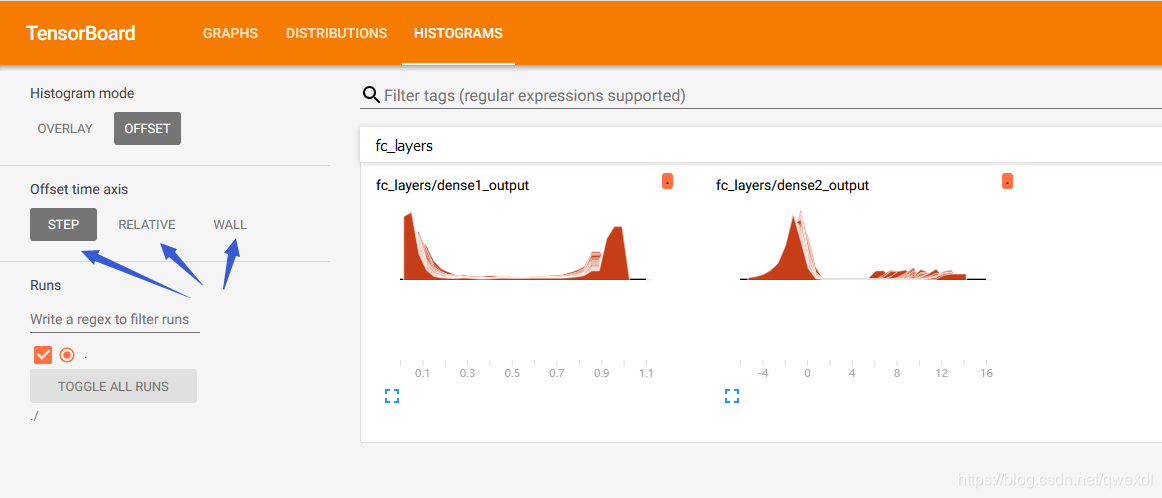
颜色越深的代表step越小,相对时间(程序运行时间)越短, 绝对时间(电脑时间)越小。
Offset time axis有三个选项,分别代表:
- STEP:
运行步数 - RELATIVE:
程序运行时间 - WALL:
电脑时间
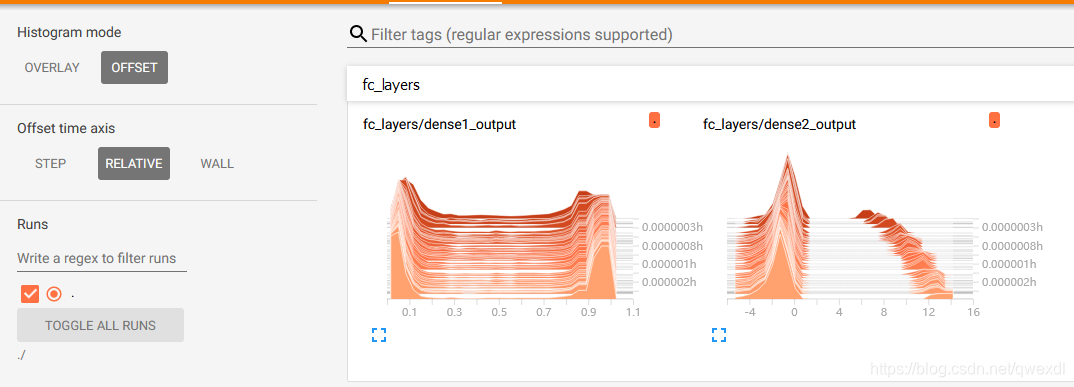
改变Offset time axis可以使图片看起来更明显:
再看下图-DISTRIBUTIONS
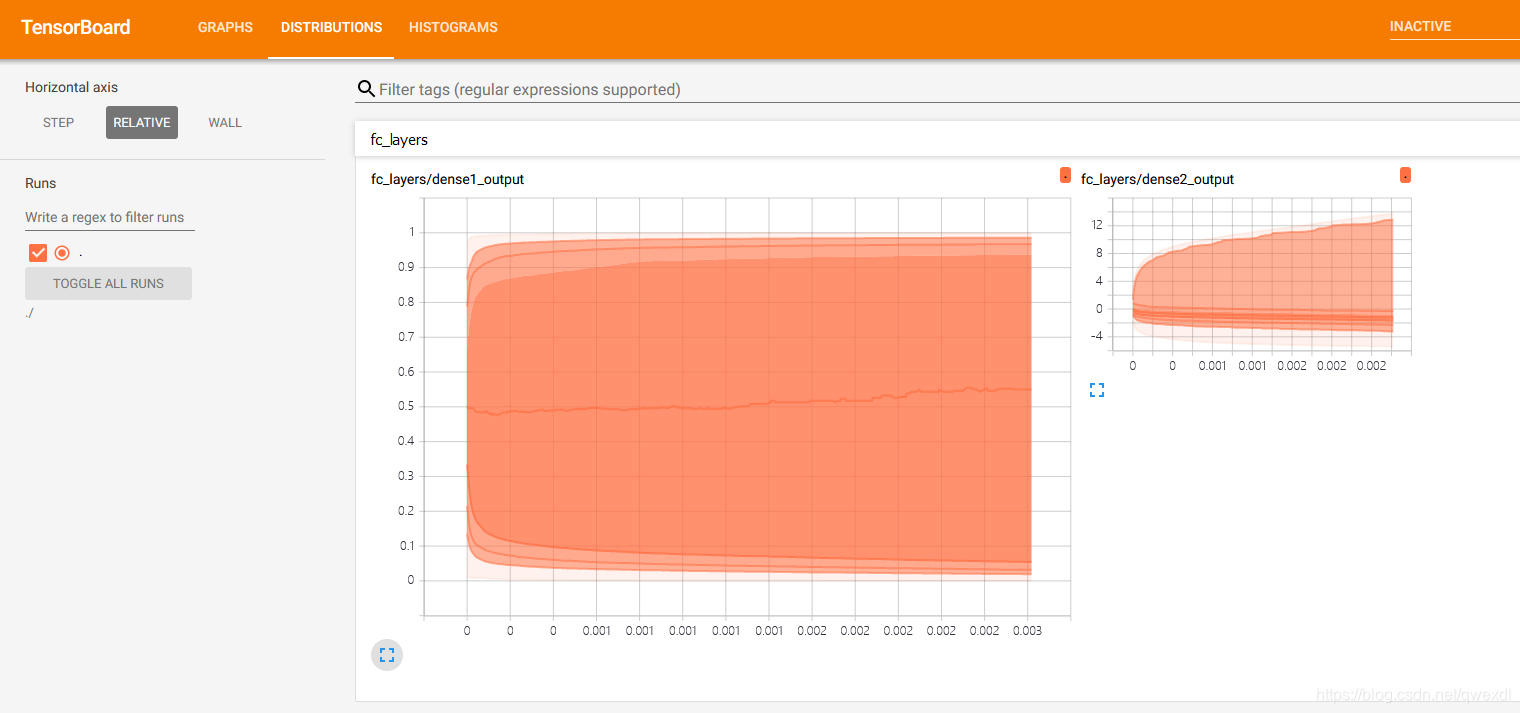
同样看RELATIVE 比看 STEP要清楚得多。
四、高维向量可视化
TensorBoard提供了PROJECTOR界面来可视化高维向量之间的关系。PROJECTOR界面可以非常方便地可视化多个高维向量之间的关系。
如果语义相近的单词所对应的向量在空间中的距离也比较接近的话,那么自然语言模型的效果也有可能会更好。
通过可视化可以很好地查看效果。
4.1 可视化Embedding
五、参考资料
- 《TensorFlow :实战 Google 深度学习框架(第2版)》
- https://zhuanlan.zhihu.com/p/37022051
这个也很不错。

















 2421
2421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









