



 本文介绍了如何使用英特尔®ONEAPIAI分析工具包,通过数据探索、预处理和机器学习(如支持向量机、集成学习)预测淡水质量和生态系统依赖情况。作者还探讨了模型性能优化、特征工程和模型集成的方法,以提升预测准确性并增强模型解释性。
本文介绍了如何使用英特尔®ONEAPIAI分析工具包,通过数据探索、预处理和机器学习(如支持向量机、集成学习)预测淡水质量和生态系统依赖情况。作者还探讨了模型性能优化、特征工程和模型集成的方法,以提升预测准确性并增强模型解释性。
淡水质量预测
目录
问题描述
淡水是我们最重要和最稀缺的自然资源之一,仅占地球总水量的 3%。它几乎触及我们日常生活的方方面面,从饮用、游泳和沐浴到生产食物、电力和我们每天使用的产品。获得安全卫生的供水不仅对人类生活至关重要,而且对正在遭受干旱、污染和气温升高影响的周边生态系统的生存也至关重要。
预期解决方案
通过参考英特尔的类似实现方案,预测淡水是否可以安全饮用和被依赖淡水的生态系统所使用,从而可以帮助全球水安全和环境可持续性发展。这里分类准确度和推理时间将作为评分的主要依据。
要求
需要使用 英特尔® ONEAPI AI分析工具包。
数据集
项目简介
通过提供的淡水质量数据集,对数据首先进行数据探索、数据预处理、利用机器学习建立模型,并进行欺诈数据的检测。
1、数据探索:查看数据集规模、数据类型、缺失值情况以及统计性描述。
2、数据预处理:处理缺失值、平衡数据样本
3、利用机器学习建立模型:支持向量机分类、集成学习
数据探索
import modin.pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
import warnings
warnings.filterwarnings('ignore')
os.environ["MODIN_ENGINE"] = "dask"
from modin.config import Engine
Engine.put("dask")
当处理大规模数据时,传统的Python库(如Pandas)可能会遇到性能瓶颈,因为它们通常只能利用单个核心进行计算,并且受到内存的限制。为了解决这些问题,出现了一些并行处理和分布式计算的库,这里使用到的是Modin和Dask。
Modin是一个用于数据处理的高性能库,它可以替代标准的Pandas库。Modin的设计目标是使得在大规模数据集上的数据操作变得更快,并且更容易地利用多核心和分布式计算资源。主要特点包括:
-
并行化和加速: Modin利用了并行计算和分布式计算的技术,可以在多个核心或多台机器上并行处理数据,从而加速数据处理过程。
-
无需修改代码: 使用Modin可以无缝替换掉原来的Pandas代码,因为它提供了与Pandas API 兼容的接口,这意味着你可以直接将Modin导入为Pandas,并且使用相同的代码来处理数据。
-
支持多种计算引擎: Modin可以配置使用不同的后端计算引擎,包括Dask、Ray等,以适应不同的数据规模和计算需求。
Dask是一个灵活的并行计算库,它提供了一种并行执行Python代码的方式,可以用于处理比内存更大的数据集。Dask的主要特点包括:
-
并行化: Dask能够自动将任务分解成小的块,并行执行这些任务,利用了多核心和分布式计算资源来加速计算过程。
-
延迟执行: Dask使用了一种称为"延迟执行"的机制,它会构建一个任务图来表示计算过程,然后在需要结果时才实际执行计算,这样可以最大程度地减少计算的开销。
-
可扩展性: Dask可以扩展到大规模的数据集和计算集群上,可以在单机、多机、甚至云计算环境中运行。
查看数据集
data = pd.read_csv('./data/dataset.csv')
print('数据规模:{}\n'.format(data.shape))
display(data.head())

data=data.infer_objects()
data.info()
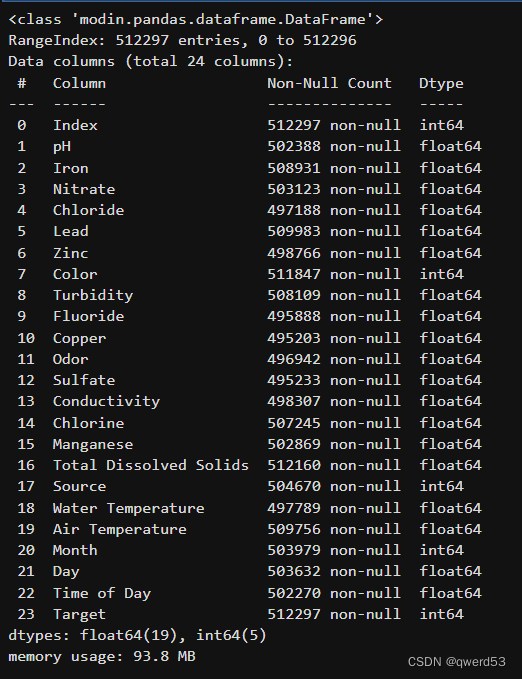
可以看到数据规模大小为512297行24列,每个样本包含上图24个特征。所有数据的类型都为float64,并且仅有极少部分属性存在缺失。
# 统计二分类标签的数量
label_counts = data['Target'].value_counts()
# 计算正负样本比例
positive_count = label_counts[1]
negative_count = label_counts[0]
total_count = len(data)
positive_percentage = (positive_count / total_count) * 100
negative_percentage = (negative_count / total_count) * 100
print("正样本数量:", positive_count)
print("负样本数量:", negative_count)
print("正样本比例: {:.2f}%".format(positive_percentage))
print("负样本比例: {:.2f}%".format(negative_percentage))数据集中,标签Target特征数量比例如下:
正样本数量: 120331 负样本数量: 391966 正样本比例: 23.49% 负样本比例: 76.51%
查看数据统计性描述
# 显示数据的统计性描述
description = data.describe()
display(description)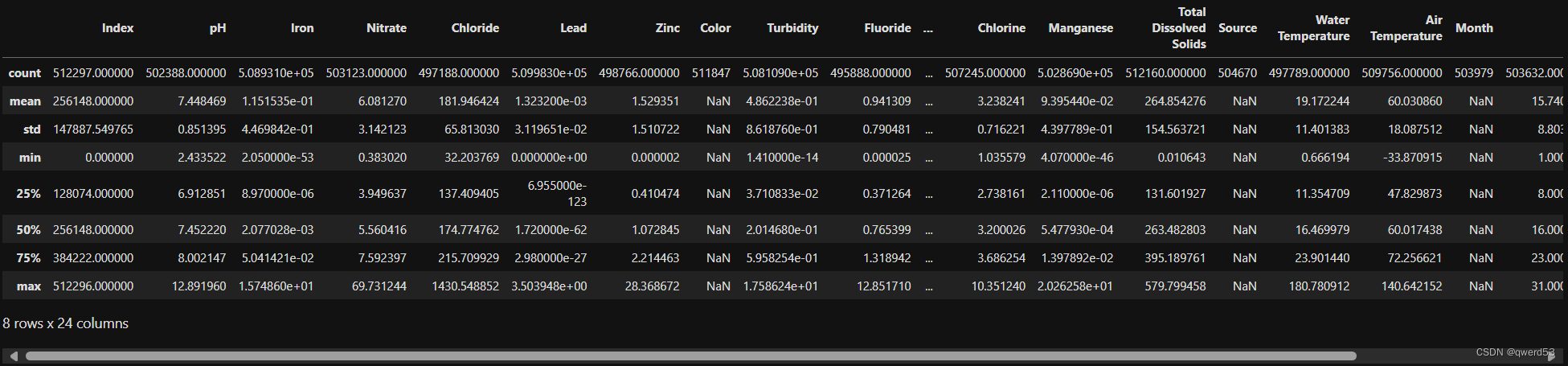
数据可视化
查看数据类别
#数据可视化
#通过饼状图直观反映数量对比。
import matplotlib.pyplot as plt
def plot_target(target_col):
tmp=data[target_col].value_counts(normalize=True)
target = tmp.rename(index={1:'Target 1',0:'Target 0'})
wedgeprops = {'width':0.5, 'linewidth':10}
plt.figure(figsize=(6,6))
plt.pie(list(tmp), labels=target.index,
startangle=90, autopct='%1.1f%%',wedgeprops=wedgeprops)
plt.title('Label Distribution', fontsize=16)
plt.show()
plot_target(target_col='Target')
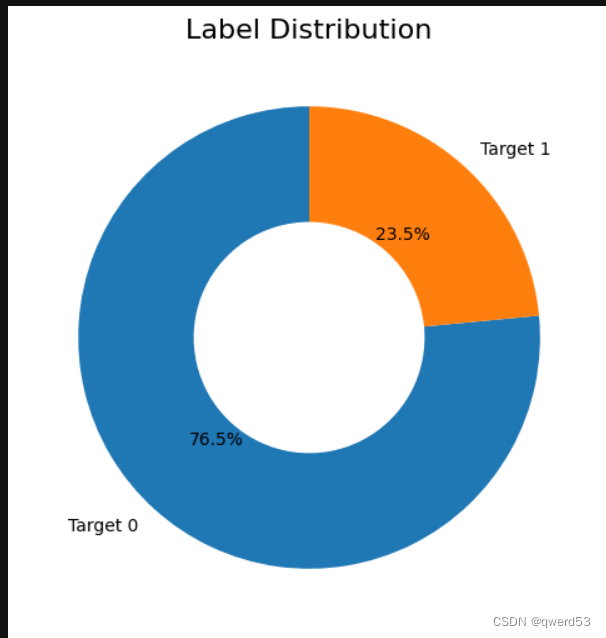
通过饼状图直观看出数据类别比例。
箱形图
#通过箱形图查看各个属性分散情况。
import matplotlib.pyplot as plt
import seaborn as sns
# 选择数值型列,并排除 "Index" 和 "Target" 列
numeric_columns = data.select_dtypes(include=['float64', 'int64']).drop(columns=["Index", "Target"])
# 创建画布
fig = plt.figure(figsize=(80, 60), dpi=75)
# 绘制箱形图
for i, column in enumerate(numeric_columns.columns):
plt.subplot(7, 8, i + 1) # 7行8列的第i个子图
sns.boxplot(x=numeric_columns[column], orient="h", width=0.5) # 箱式图
plt.ylabel(column, fontsize=36)
# 调整布局
plt.tight_layout()
# 显示图形
plt.show()
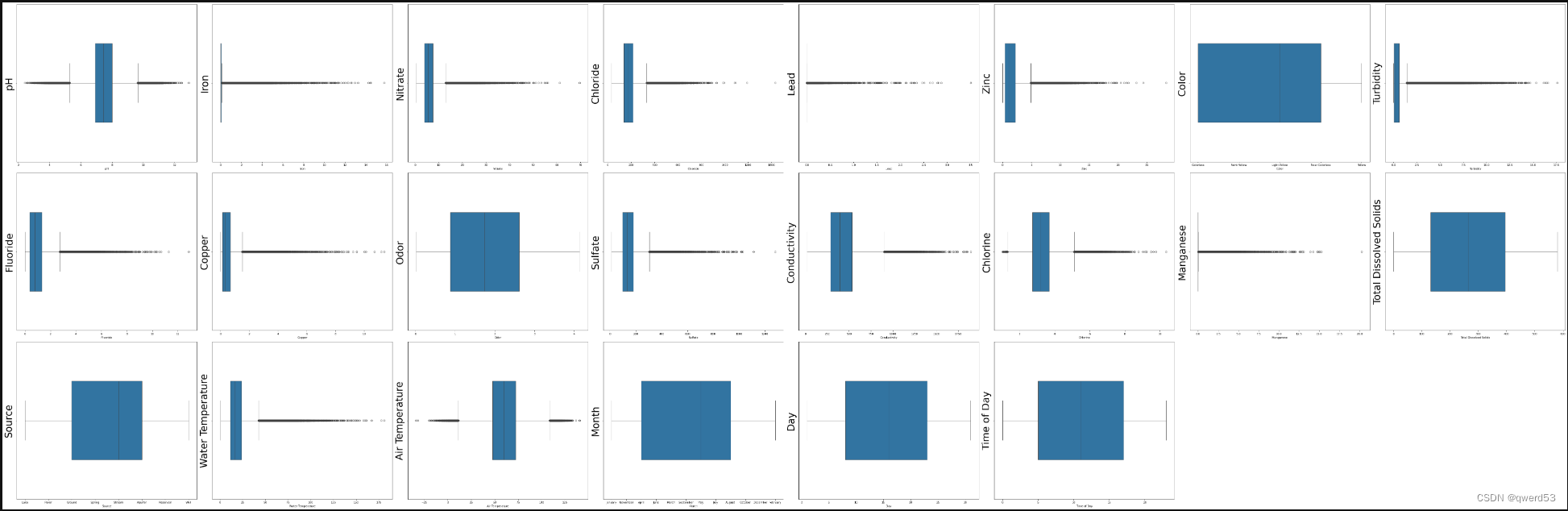
箱型图是一种用于可视化数据分布情况的统计图表。它能够展示数据的中位数、上下四分位数、最大值、最小值以及异常值等统计信息,有助于直观地了解数据的分布形态、离散程度以及异常值情况。
二元分布图
热力图
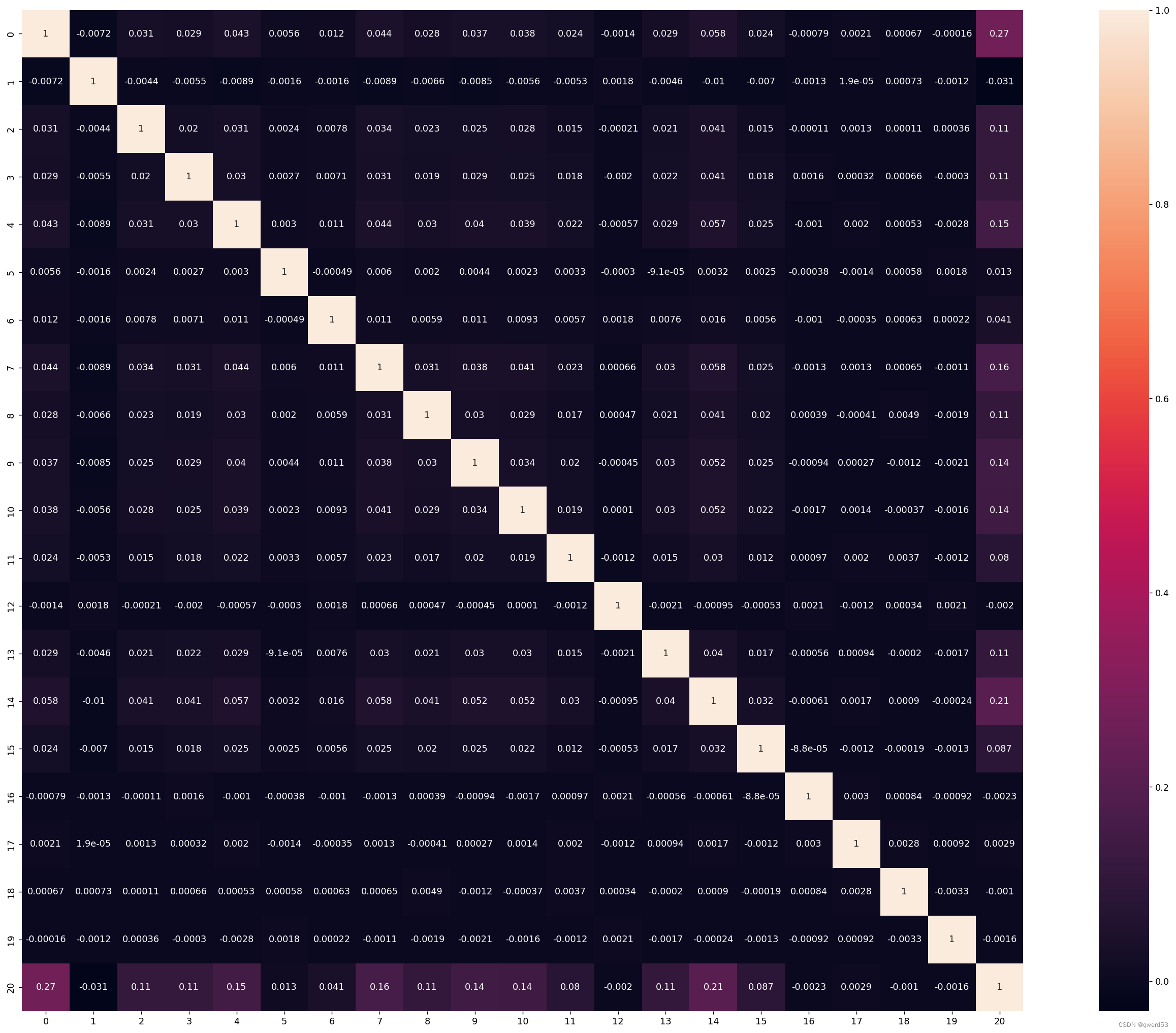
热力图用于呈现矩形数据集的值,其中每个值通过颜色编码来表示。热力图通常用于显示二维数据集中各个元素之间的相关性、关联性或密度分布等信息。
# 选择数值型特征
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# 计算相关系数
corr = plt.subplots(figsize=(30, 20), dpi=128)
corr = sns.heatmap(numeric_data.corr(method='spearman'), annot=True, square=True)
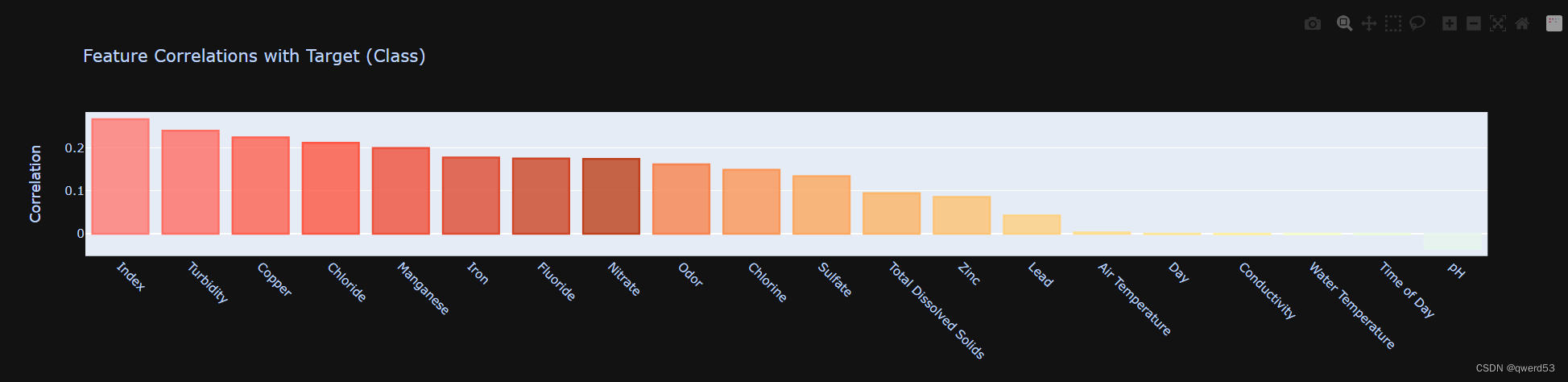
查看各属性与类别相关性
import plotly.graph_objects as go
import matplotlib.colors
def plot_target_corr(corr, target_col):
corr = corr[target_col].sort_values(ascending=False)[1:]
pal = sns.color_palette("RdYlBu", 37).as_hex()
pal = [j for i, j in enumerate(pal) if i not in (17, 18)]
rgb = ['rgba' + str(matplotlib.colors.to_rgba(i, 0.8)) for i in pal]
fig = go.Figure()
fig.add_trace(go.Bar(x=corr.index, y=corr, marker_color=rgb,
marker_line=dict(color=pal, width=2),
hovertemplate='%{x} correlation with Target = %{y}',
showlegend=False, name=''))
fig.update_layout(title='Feature Correlations with Target (Class)',
yaxis_title='Correlation', xaxis_tickangle=45)
fig.show()
# 选择数值型特征
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# 计算相关系数
corr = numeric_data.corr()
# 绘制相关性图
plot_target_corr(corr=corr, target_col='Target')
数据预处理
后续的特征数据的相关性都比较差,所以这里采取的做法为删除相关特征以及对应的列数据

查看重复值和缺失值
# 查看重复值
duplicate_rows = data[data.duplicated()]
print("重复行数:", duplicate_rows.shape[0])
if duplicate_rows.shape[0] > 0:
print("重复行:")
print(duplicate_rows)
# 查看缺失值
missing_values = data.isnull().sum()
print("\n缺失值统计:")
print(missing_values)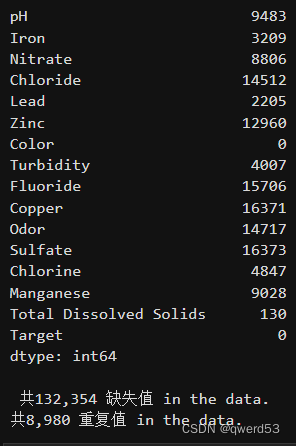
可以看到数据中存在缺失值与重复值,本项目采用填充上下值的平均值的方法进行处理缺失值,并删除重复值。
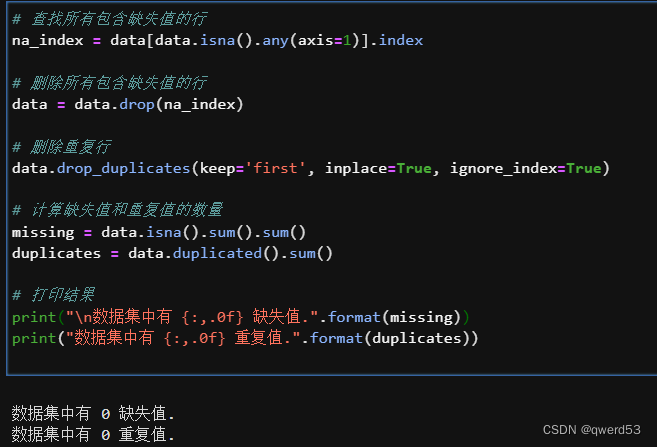
处理重复值与缺失值
# 查找所有包含缺失值的行
na_index = data[data.isna().any(axis=1)].index
# 删除所有包含缺失值的行
data = data.drop(na_index)
# 删除重复行
data.drop_duplicates(keep='first', inplace=True, ignore_index=True)
# 计算缺失值和重复值的数量
missing = data.isna().sum().sum()
duplicates = data.duplicated().sum()
# 打印结果
print("\n数据集中有 {:,.0f} 缺失值.".format(missing))
print("数据集中有 {:,.0f} 重复值.".format(duplicates))
处理以后结果如下:
偏差值处理:
通过以下代码对偏差值进行处理,通过检查皮尔逊相关系数与缺失值比例是否大于20%,数值型特征方差是否小于0.1来进行删除特征操作。
from scipy.stats import pearsonr
variables = data.columns
data = data
var = data.var()
numeric = data.columns
data = data.fillna(data.interpolate())
for i in range(0, len(var) - 1):
if var[i] <= 0.1: # 方差大于10%
print(variables[i])
data = data.drop(numeric[i],axis=1)
variables = data.columns
for i in range(0, len(variables)):
x = data[variables[i]]
y = data[variables[-1]]
if pearsonr(x, y)[1] > 0.05:
print(variables[i])
data = data.drop(variables[i],axis=1)
variables = data.columns
print(variables)
print(len(variables))结果如下: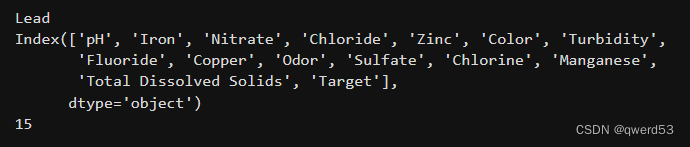
然后删除Lead所对应的列数据。
数据转换:
通过直方图的形式查看连续性数据的分布,只有类似于正态分布的数据分布才是符合现实规律的数据,并且这有利于模型的训练。

既有符合正态分布的,也有比较不符合的,然后对不符合正态分布的特征数据进行数据转换:
针对不规则分布的变量进行非线性变换,一般进行log
import numpy as np
log_col = ['Iron', 'Zinc', 'Turbidity', 'Copper', 'Manganese']
show_col = []
for col in log_col:
data[col + '_log'] = np.log(data[col])
show_col.append(col + '_log')
data[show_col].hist(bins=50,figsize=(16,12))
结果如下:
模型训练

在网格搜索过程中,模型采用 f1_score 作为评价指标,基于 StratifiedKFold 将数据分为3份,尝试之前定义的参数列表,使用 fit 方法对模型进行训练。训练完成后,使用测试集(X_test)进行验证,并将结果输出,代码如下:
import datetime
from sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import f1_score
refit_score = "f1_score"
start_time = datetime.datetime.now()
print(start_time)
rd_search = RandomizedSearchCV(xgb, param_grid, n_iter=10, cv=3, refit=refit_score, scoring=sklearn.metrics.make_scorer(f1_score), verbose=10, return_train_score=True)
rd_search.fit(X_train, y_train)
print(rd_search.best_params_)
print(rd_search.best_score_)
print(rd_search.best_estimator_)
print(datetime.datetime.now() - start_time)
搜索后的最优参数:
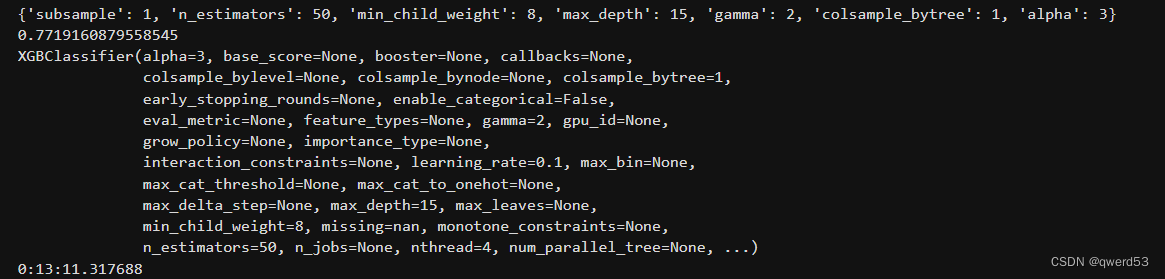
模型训练结果:
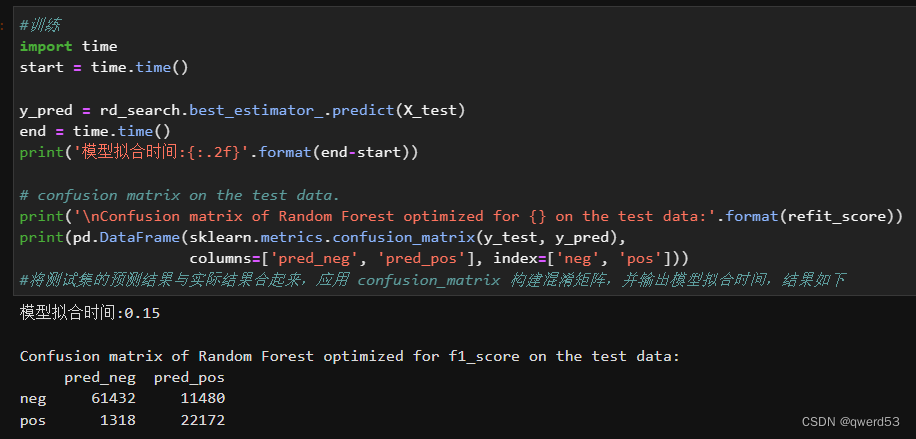
f1分数如下:

可视化结果:
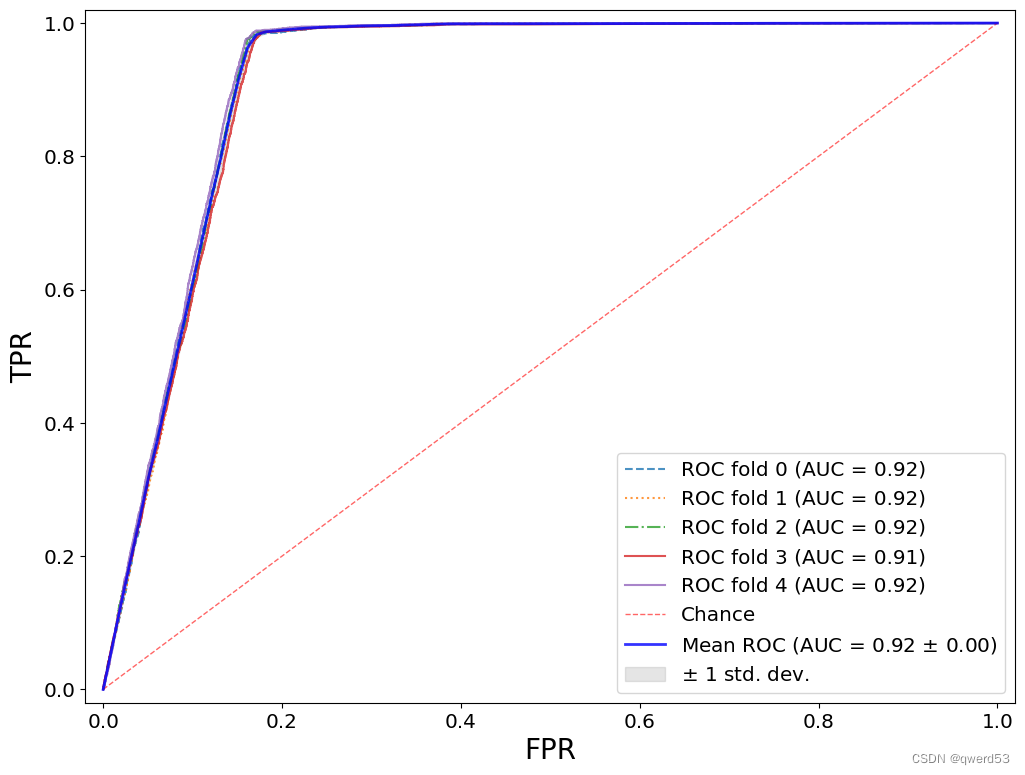
进一步工作
-
模型性能调优: 尝试使用其他机器学习算法,如随机森林、逻辑回归等,与当前的支持向量机分类器进行比较。调整模型参数并进行交叉验证,以提高模型的性能和泛化能力。
-
特征工程: 探索更多的特征工程方法,例如特征选择、特征组合、特征转换等,以提取更具信息量的特征,从而改善模型的预测能力。
-
模型集成: 考虑使用集成学习方法,如随机森林、梯度提升树等,将多个模型的预测结果进行组合,以进一步提高预测性能。
-
模型评估与解释: 使用更多的评价指标来评估模型性能,如精确度、召回率、F1分数等。此外,尝试使用SHAP、LIME等工具来解释模型的预测结果,以增强模型的可解释性。
学习心得
在完成这个项目的过程中,我学到了很多关于淡水质量预测和机器学习的知识。在开始建模之前,进行数据探索是至关重要的。通过查看数据的统计性描述、可视化分析等方法,可以帮助我理解数据的特征和分布情况,从而为后续的数据预处理和建模工作提供指导。在本项目中,我学会了处理缺失值、重复值、数据平衡等技巧,这些技巧对于提高模型的性能和鲁棒性非常重要。模型选择与评估: 在选择模型时,需要根据具体的问题和数据情况来进行选择。在完成本次作业的过程中,我亲身体验到了Intel AI Analytics Toolkit工具对问题解决的显著帮助,例如modin/sklearnex。在第一阶段的学习中我曾经对oneAPI在深度学习领域的应用有所了解。而在这次作业中,我再次感受到了oneAPI在实际应用中的易用性和加速效果。

















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









