







 本文探讨了通过英特尔的解决方案,利用XGBoost模型和数据预处理技术预测淡水质量和环境可持续性的方法。文章详细描述了数据集探索、不平衡数据处理、模型训练过程以及如何利用Intel加速工具提高效率。
本文探讨了通过英特尔的解决方案,利用XGBoost模型和数据预处理技术预测淡水质量和环境可持续性的方法。文章详细描述了数据集探索、不平衡数据处理、模型训练过程以及如何利用Intel加速工具提高效率。
1 选题:预测淡水质量
1.1 问题描述
淡水是我们最重要和最稀缺的自然资源之一,仅占地球总水量的 3%。它几乎触及我们日常生活的方方面面,从饮用、游泳和沐浴到生产食物、电力和我们每天使用的产品。获得安全卫生的供水不仅对人类生活至关重要,而且对正在遭受干旱、污染和气温升高影响的周边生态系统的生存也至关重要。
1.2 预期解决方案
通过参考英特尔的类似实现方案,预测淡水是否可以安全饮用和被依赖淡水的生态系统所使用,从而可以帮助全球水安全和环境可持续性发展。这里分类准确度和推理时间将作为评分的主要依据。
1.3 数据集
https://filerepo.idzcn.com/hack2023/datasetab75fb3.zip
1.4 问题需求
需要使用 英特尔® ONEAPI AI分析工具包
1.5 参考资料
欢迎参考英特尔提供的类似实现方案。
也可以参考课程实践案例。
2 项目设计与实现
2.1 数据初探索
2.1.1 解压缩数据集
首先将压缩包上传至Intel云平台,并将下载的数据集压缩包解压至云平台。
import os
import zipfile
folder_path = './data/'
with zipfile.ZipFile(folder_path + 'dataset.zip', 'r') as zip_train:
zip_train.extractall(folder_path) # 解压训练集
print("解压完成")得到如下文件:

2.1.2 查看数据集并初步分析
首先查看数据集。
import modin.pandas as pd
import os
os.environ["MODIN_ENGINE"] = "dask"
from modin.config import Engine
Engine.put("dask")
data = pd.read_csv('./data/dataset.csv')
print('数据规模:{}\n'.format(data.shape))
display(data.head())通过pd的read_csv方法读取csv文件,查看数据集前五项数据。
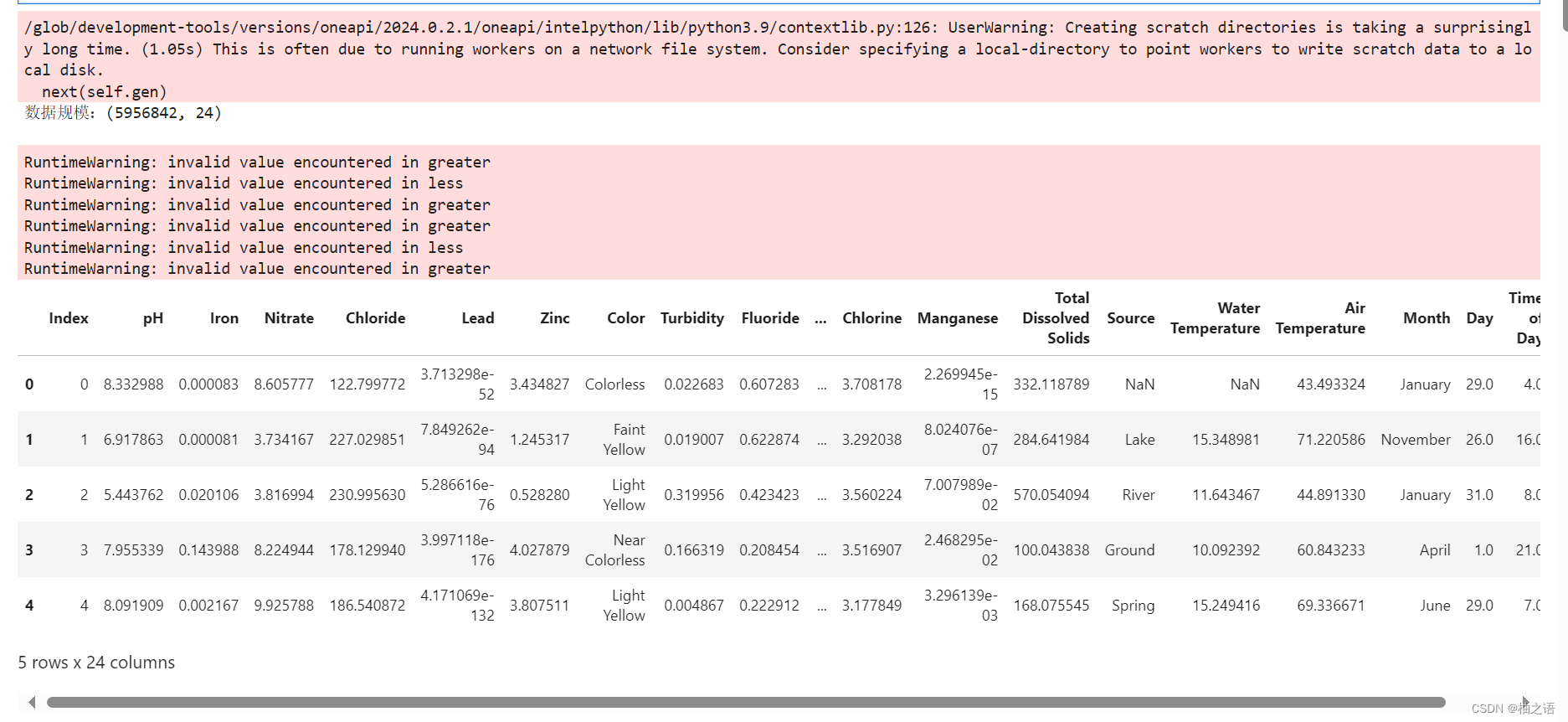
同时获取data的简要摘要。
data.info()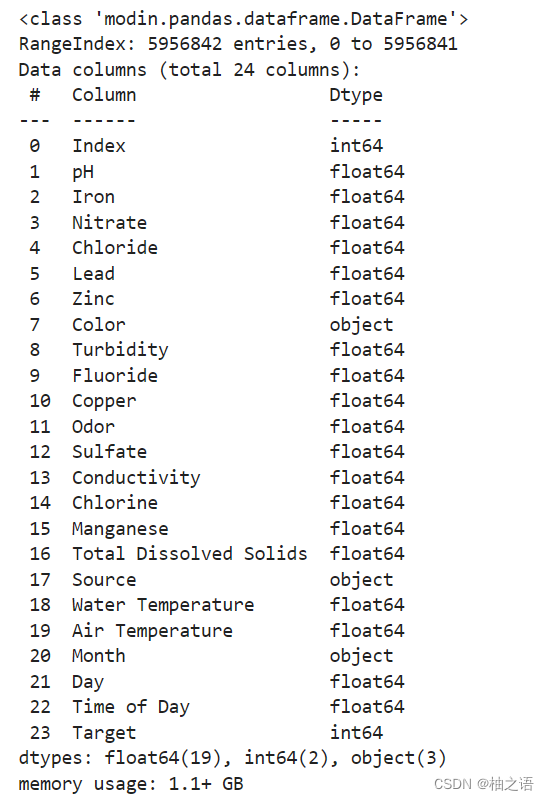
由此可知整个数据集有22个特征和1个Target标签, 并且Color, Source, Month为字符串。再次检查data。
# 检查每列的数据类型
for col in data.columns:
if check_data[col].dtype == object:
print(f"Column '{col}' contains string data.")得到的结果相同。

后续将去掉这些类型为字符串的列,只保存数值列。
2.2 数据可视化
2.2.1 标签饼图
通过饼图显示标签分布。
import matplotlib.pyplot as plt
def plot_target(target_col):
tmp=data[target_col].value_counts(normalize=True)
target = tmp.rename(index={1:'Target 1',0:'Target 0'})
wedgeprops = {'width':0.5, 'linewidth':10}
plt.figure(figsize=(6,6))
plt.pie(list(tmp), labels=target.index,
startangle=90, autopct='%1.1f%%',wedgeprops=wedgeprops)
plt.title('Label Distribution', fontsize=16)
plt.show()
plot_target(target_col='Target')标签分布:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











