




![]()
上一篇链接:
1.环境模型准备。
1.1 配置基础环境
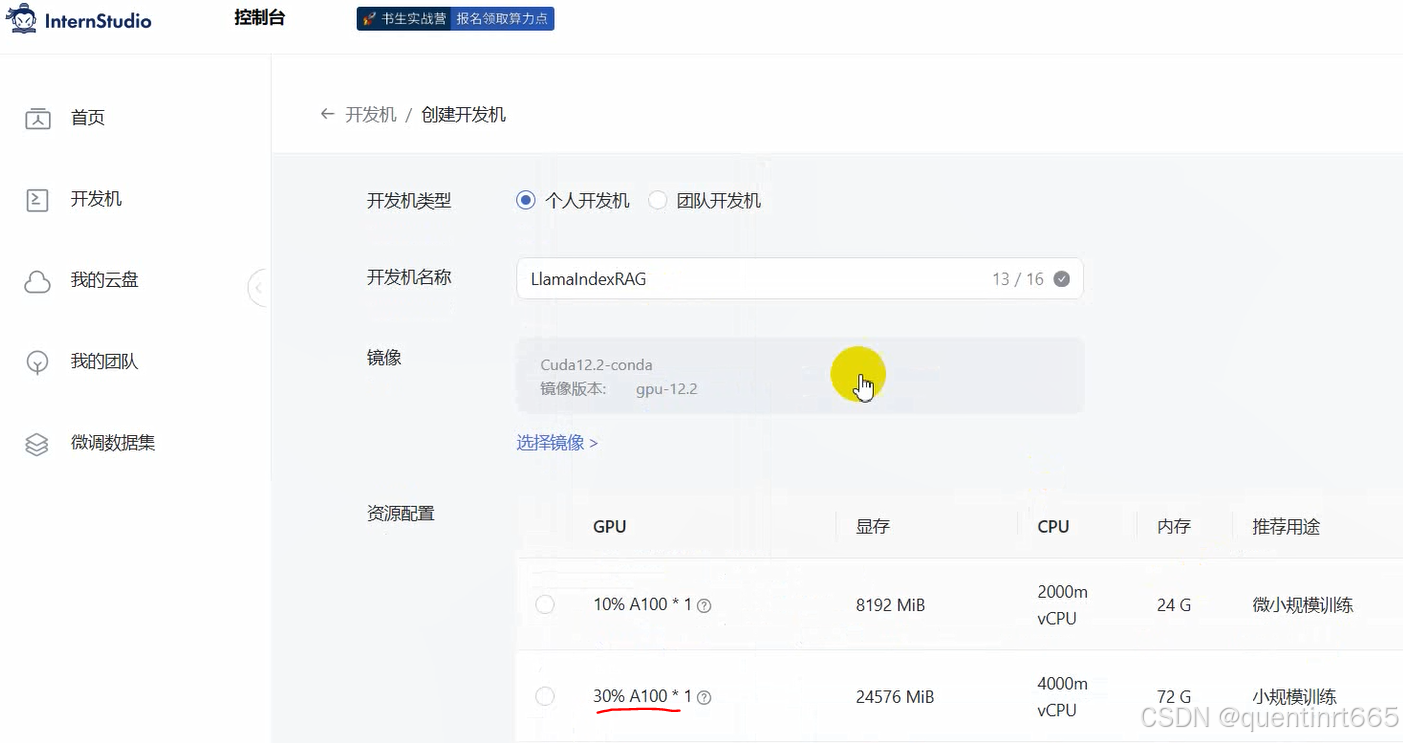
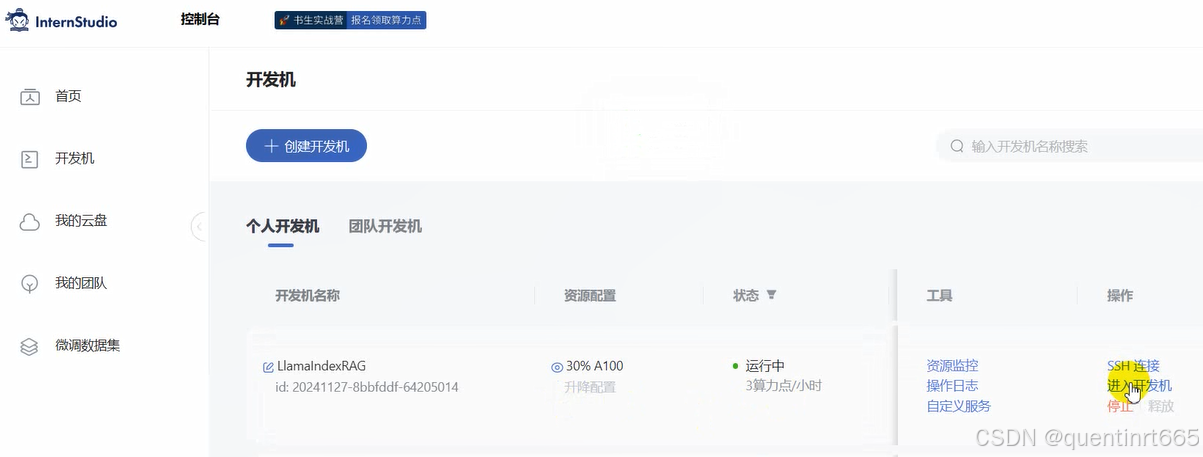
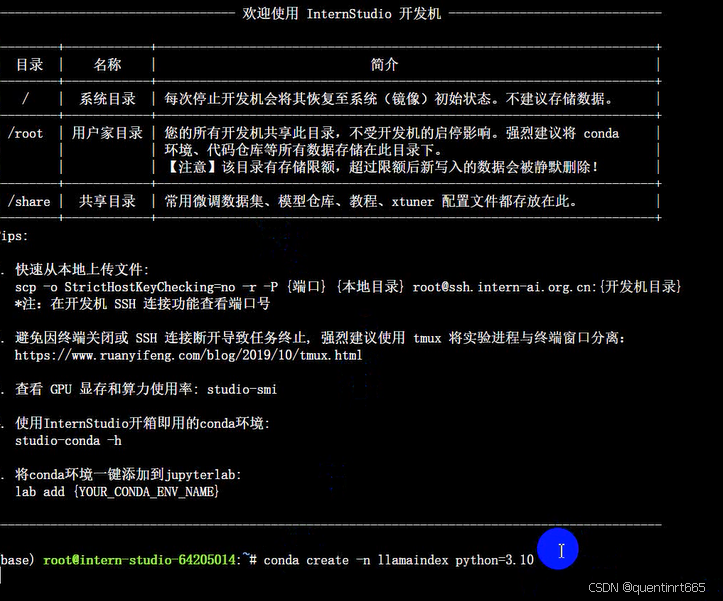
点击进入开发机后,创建新的conda环境,命名为 llamaindex,在命令行模式下运行:
conda create -n llamaindex python=3.10
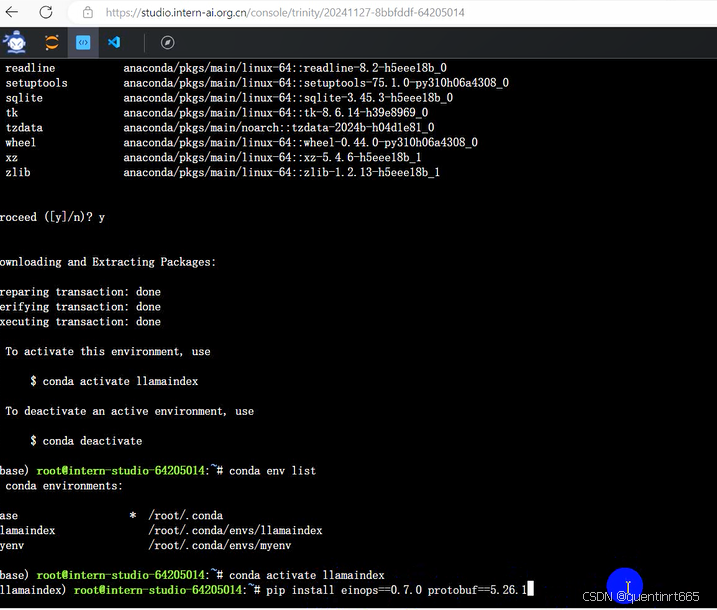
可以用 conda env list 查看本地环境
运行 conda 命令,激活 llamaindex 然后安装相关基础依赖 python 虚拟环境:
conda activate llamaindex
安装python 依赖包
pip install einops==0.7.0 protobuf==5.26.1
1.2 安装 Llamaindex
安装 Llamaindex和相关的包
conda activate llamaindex
pip install llama-index==0.11.20
pip install llama-index-llms-replicate==0.3.0
pip install llama-index-llms-openai-like==0.2.0
pip install llama-index-embeddings-huggingface==0.3.1
pip install llama-index-embeddings-instructor==0.2.1
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu121
1.3下载 Sentence Transformer 模型
cd ~
mkdir llamaindex_demo
mkdir model
cd ~/llamaindex_demo
touch download_hf.py

打开download_hf.py 贴入以下代码
import os
# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/model/sentence-transformer')
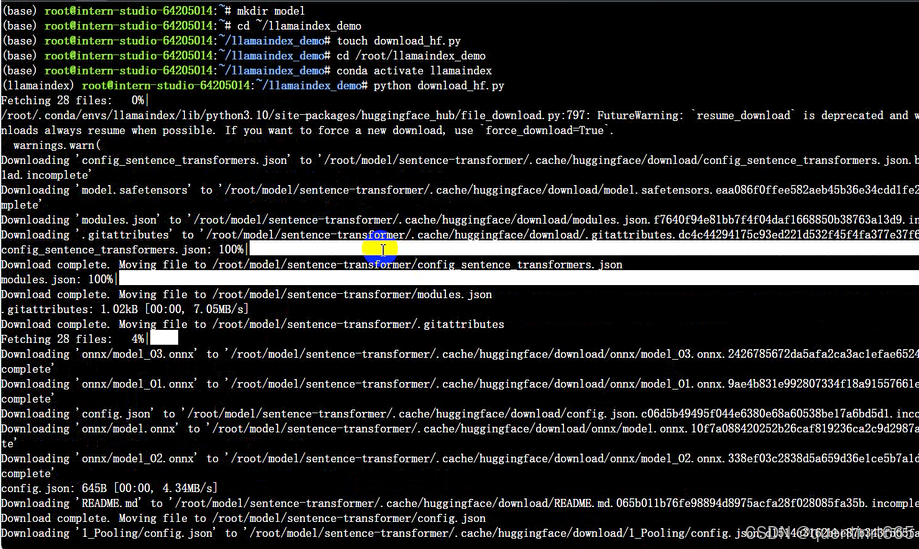
然后,在 /root/llamaindex_demo 目录下执行该脚本即可自动开始下载:
cd /root/llamaindex_demo
conda activate llamaindex
python download_hf.py
1.4 下载 NLTK 相关资源
我们在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。正常情况下,其会自动从互联网上下载,但可能由于网络原因会导致下载中断,此处我们可以从国内仓库镜像地址下载相关资源,保存到服务器上。 我们用以下命令下载 nltk 资源并解压到服务器上:
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip
2. 是否使用 LlamaIndex 前后对比
2.1 不使用 LlamaIndex RAG(仅API)
浦语官网和硅基流动都提供了InternLM的类OpenAI接口格式的免费的 API,可以访问以下两个了解两个 API 的使用方法和 Key。
浦语官方 API:书生·浦语![]() https://internlm.intern-ai.org.cn/api/document
https://internlm.intern-ai.org.cn/api/document
硅基流动:硅基流动统一登录硅基流动统一登录 硅基流动用户系统,统一登录 SSO![]() https://cloud.siliconflow.cn/models?mfs=internlm
https://cloud.siliconflow.cn/models?mfs=internlm
运行以下指令,新建一个python文件
cd ~/llamaindex_demo
touch test_internlm.py
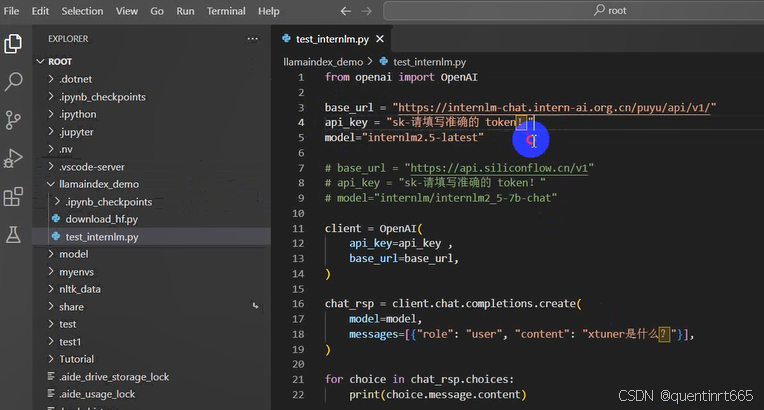
打开test_internlm.py 贴入以下代码
from openai import OpenAI
base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
api_key = "sk-请填写准确的 token!"
model="internlm2.5-latest"
# base_url = "https://api.siliconflow.cn/v1"
# api_key = "sk-请填写准确的 token!"
# model="internlm/internlm2_5-7b-chat"
client = OpenAI(
api_key=api_key ,
base_url=base_url,
)
chat_rsp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "xtuner是什么?"}],
)
for choice in chat_rsp.choices:
print(choice.message.content)
修改apikey 后运行:

结果为:

2.2 使用 API+LlamaIndex
conda activate llamaindex
运行以下命令,获取知识库
cd ~/llamaindex_demo
mkdir data
cd data
git clone https://github.com/InternLM/xtuner.git
mv xtuner/README_zh-CN.md ./
运行以下指令,新建一个python文件
cd ~/llamaindex_demo
touch llamaindex_RAG.py
打开llamaindex_RAG.py贴入以下代码
import os
os.environ['NLTK_DATA'] = '/root/nltk_data'
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core.settings import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.legacy.callbacks import CallbackManager
from llama_index.llms.openai_like import OpenAILike
# Create an instance of CallbackManager
callback_manager = CallbackManager()
api_base_url = "https://internlm-chat.intern-ai.org.cn/puyu/api/v1/"
model = "internlm2.5-latest"
api_key = "请填写 API Key"
# api_base_url = "https://api.siliconflow.cn/v1"
# model = "internlm/internlm2_5-7b-chat"
# api_key = "请填写 API Key"
llm =OpenAILike(model=model, api_base=api_base_url, api_key=api_key, is_chat_model=True,callback_manager=callback_manager)
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/model/sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_model
#初始化llm
Settings.llm = llm
#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
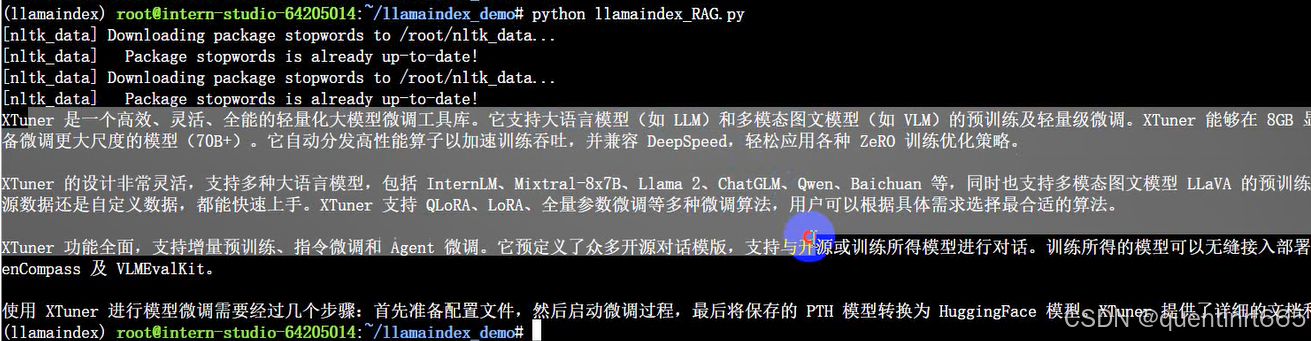
response = query_engine.query("xtuner是什么?")
print(response)
修改apikey 后运行:
conda activate llamaindex
cd ~/llamaindex_demo/
python llamaindex_RAG.py
建议严格按上述操作执行,这些过程中如果遇到问题,比如pytorch问题等,请注意版本匹配问题,以下链接供参考
3.将 Streamlit+LlamaIndex+浦语API的 Space 部署到 Hugging Face
在Hugging Face创建新的space,
https://huggingface.co/spaces/quentinrobot/llamaindex_rag
启动github-codespace,执行下面命令将space仓库克隆下来.
git clone https://huggingface.co/spaces/quentinrobot/llamaindex_rag
进入llamaindex_rag文件夹,新建data文件夹,执行下列命令,获取知识库
cd llamaindex_rag
mkdir data
cd data
git clone https://github.com/InternLM/xtuner.git
mv xtuner/README_zh-CN.md ./添加并设置,requirements.txt文件,添加下面内容
einops==0.7.0
protobuf==5.26.1
llama-index==0.11.20
llama-index-llms-replicate==0.3.0
llama-index-llms-openai-like==0.2.0
llama-index-embeddings-huggingface==0.3.1
llama-index-embeddings-instructor==0.2.1
torch==2.5.0
torchvision==0.20.0
torchaudio==2.5.0
streamlit==1.39.0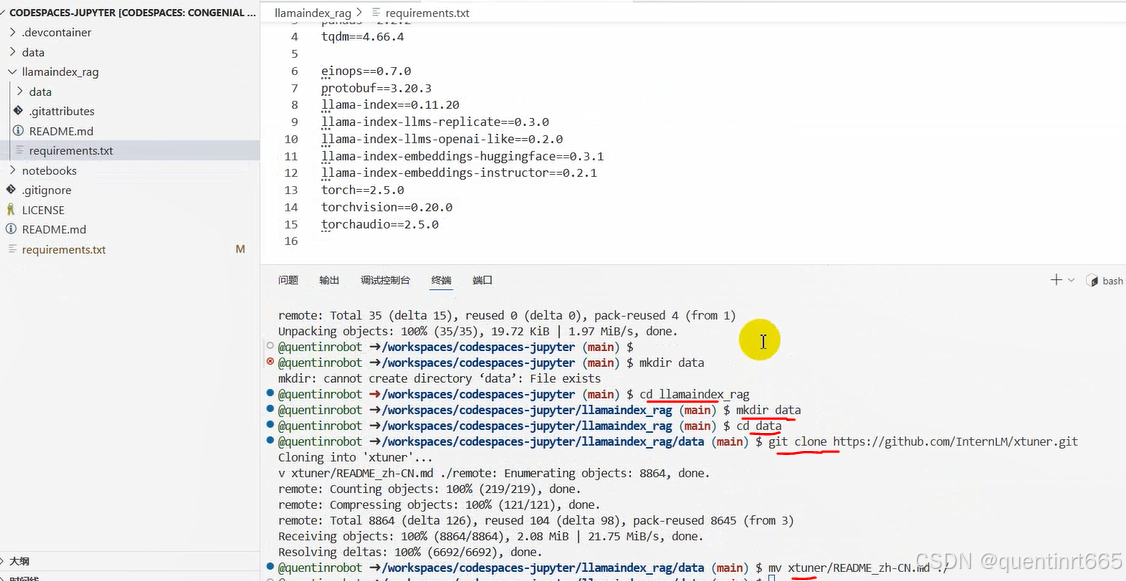
进入HF的space 的setting界面

设置API_KEY, 这里的名字与程序中的名字需要一致,否则会报错.
密钥的内容就是你调用的模型申请的,书生模型或者硅基流动.我这里用的是硅基流动.
怎样生成密钥,可以前往官网或者网上查询.
浦语官方 API:书生·浦语![]() https://internlm.intern-ai.org.cn/api/document
https://internlm.intern-ai.org.cn/api/document
硅基流动:硅基流动统一登录硅基流动统一登录 硅基流动用户系统,统一登录 SSO![]() https://cloud.siliconflow.cn/models?mfs=internlm
https://cloud.siliconflow.cn/models?mfs=internlm

完成后使用git命令将模型上传.
git add .
git commit -m "sentfile"
git push 如出现文件没有被跟踪,比如app.py,equirements.txt文件,则手动添加
git add ../app.py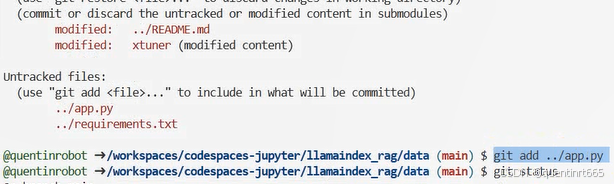
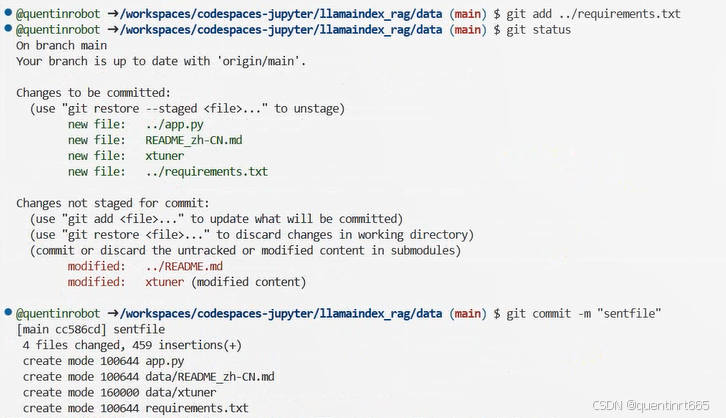
再使用下面操作进行推送:
git push发现报错,原因是未输入HF的账号密码

添加后继续使用
git push完成推送

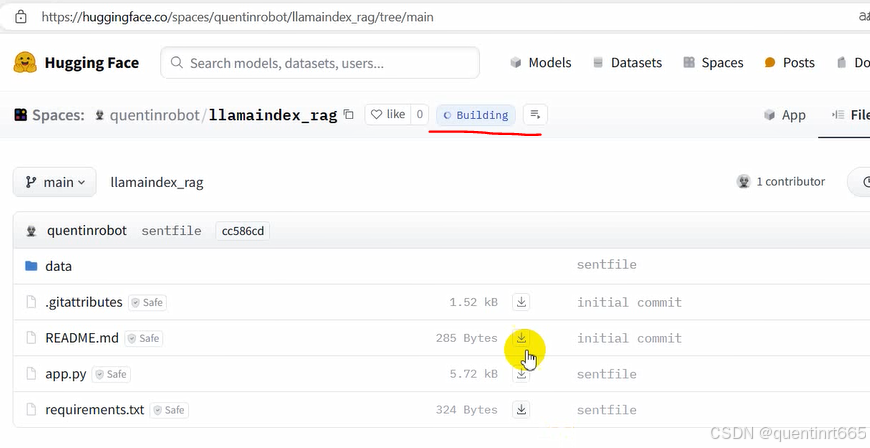
转到HF-space页面中来,可以看见模型正在创建
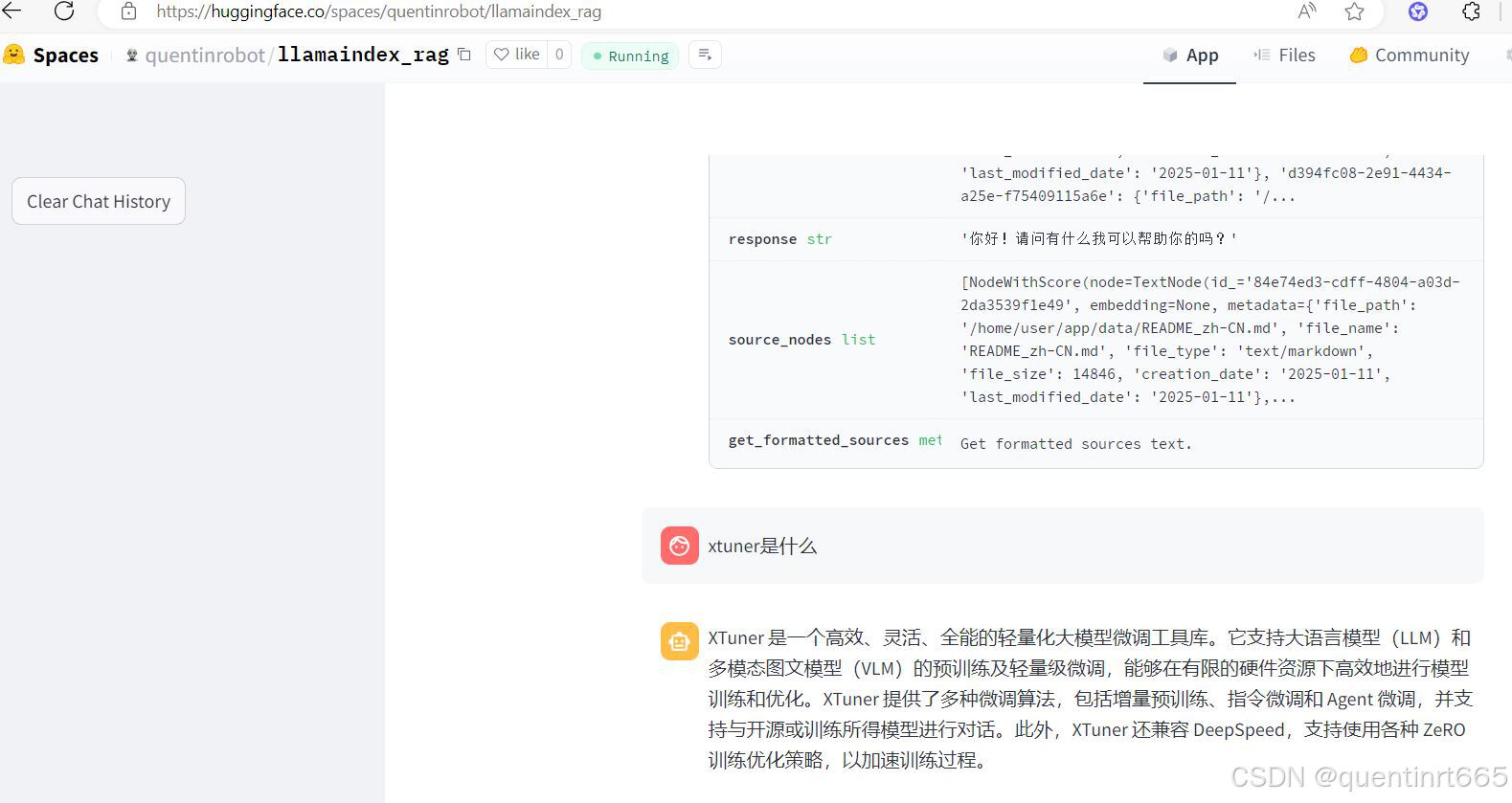
显示running后,询问xtuner是什么,并给出回答.
至此完成模型部署,感谢!

















 7254
7254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









