




![]()
上篇链接如下:
在 GitHub 上创建一个 Pull Request&创建并提交一个项目
今天的内容链接:
Tutorial/docs/L0/maas/readme.md at camp4 · InternLM/Tutorial![]() https://github.com/InternLM/Tutorial/blob/camp4/docs/L0/maas/readme.md使用Hugging Face平台下载模型
https://github.com/InternLM/Tutorial/blob/camp4/docs/L0/maas/readme.md使用Hugging Face平台下载模型
1.打开github页面,进入codespace,选择jupyter Notebook 界面。Sign in to GitHub · GitHubGitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects.![]() https://github.com/codespaces
https://github.com/codespaces
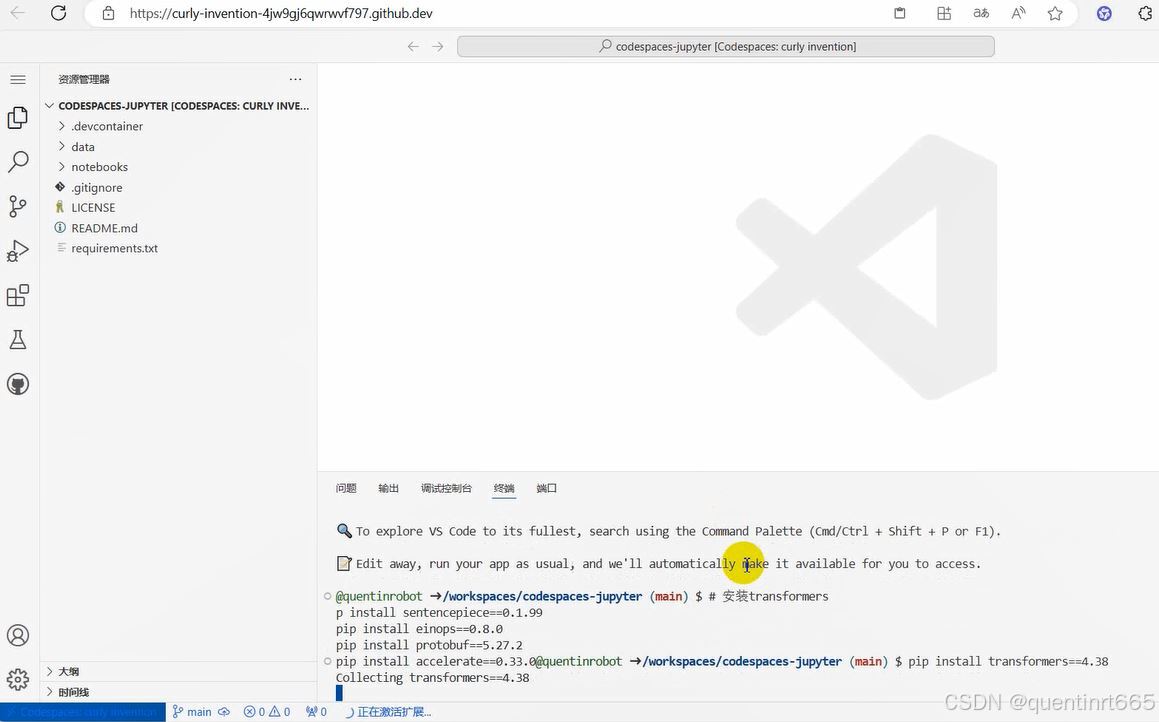
2.在终端安装transformers
# 安装transformers
pip install transformers==4.38
pip install sentencepiece==0.1.99
pip install einops==0.8.0
pip install protobuf==5.27.2
pip install accelerate==0.33.0
3.下载internlm2_5-7b-chat的配置文件
以下载模型的配置文件为例,先新建一个hf_download_josn.py 文件
touch hf_download_josn.py
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2836
2836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









