



项目地址:
github地址:https://github.com/hwua-hi168/quantanexus
gitee地址:https://gitee.com/hwua_1/quantanexus-docs
公有云版地址: https://www.hi168.com

如果是添加主机和GPU, 请从第3步开始看。
如果是想看怎么用, 请看最后一步。
1. 系统预检查 (precheck)
# 移除系统关键文件的安全属性标志,允许修改这些文件
chattr -i /etc/passwd
chattr -i /etc/shadow
chattr -i /etc/group
chattr -i /etc/gshadow
# 检测系统中是否安装了NVIDIA显卡设备
lspci -nn | grep -i nvidia
# 检查CPU是否支持虚拟化技术(vmx/svm)和DMA保护(iommu/dmar)
grep -E "vmx|svm|dmar|iommu" /proc/cpuinfo
# 验证IOMMU组设备的配置状态,检查IOMMU是否启用
ls -l /sys/kernel/iommu_groups/*/devices/*
# 显示NVIDIA GPU的详细信息和驱动状态
nvidia-smi
# 卸载主机上的NVIDIA驱动及相关组件
sudo systemctl stop nvidia-persistenced # 停止NVIDIA持久化守护进程
sudo apt-get purge *nvidia* *cuda* *cudnn* -y # 卸载NVIDIA相关软件包
sudo apt-get purge "*nvidia*" -y # 强制卸载所有NVIDIA相关包
dpkg -l|grep nvidia # 检查是否还有NVIDIA包残留
dpkg -l|grep cuda # 检查是否还有CUDA包残留
sudo apt-get purge "*cuda*" -y # 强制卸载所有CUDA相关包2. GPU Operator 升级操作
# 设置要升级到的版本标签
export RELEASE_TAG=v25.3.2
# 更新NVIDIA Helm仓库
helm repo update nvidia
# 获取指定版本的GPU Operator配置模板并保存到本地文件
helm show values nvidia/gpu-operator --version=$RELEASE_TAG > values-$RELEASE_TAG.yaml
# 执行GPU Operator升级操作
helm upgrade gpu-operator nvidia/gpu-operator -n gpu-operator \
--disable-openapi-validation \
-f values-$RELEASE_TAG.yaml \
--version $RELEASE_TAG
配置文件修改说明:
# 启用沙箱工作负载支持,用于虚拟机透传场景
sandboxWorkloads:
enabled: true # 启用沙箱工作负载功能
defaultWorkload: "container" # 设置默认工作负载类型为容器小伙伴们 可 以 注 & 册 https://www.hi168.com 白 & 飘 算 & 力哦。
3. 节点标签配置
# 为节点添加GPU驱动部署标签,允许在该节点部署GPU驱动
kubectl label node hi168-node1 nvidia.com/gpu.deploy.driver=true
# 为节点配置GPU工作负载模式,设置为VM透传模式
kubectl label node hi168-node1 --overwrite nvidia.com/gpu.workload.config=vm-passthrough4. 安装正确的内核版本
# 列出系统中可用的Linux内核镜像包
apt list linux-image-*generic
# 需要检查NVIDIA官方文档中的内核版本兼容性标签
# https://catalog.ngc.nvidia.com/orgs/nvidia/containers/driver/tags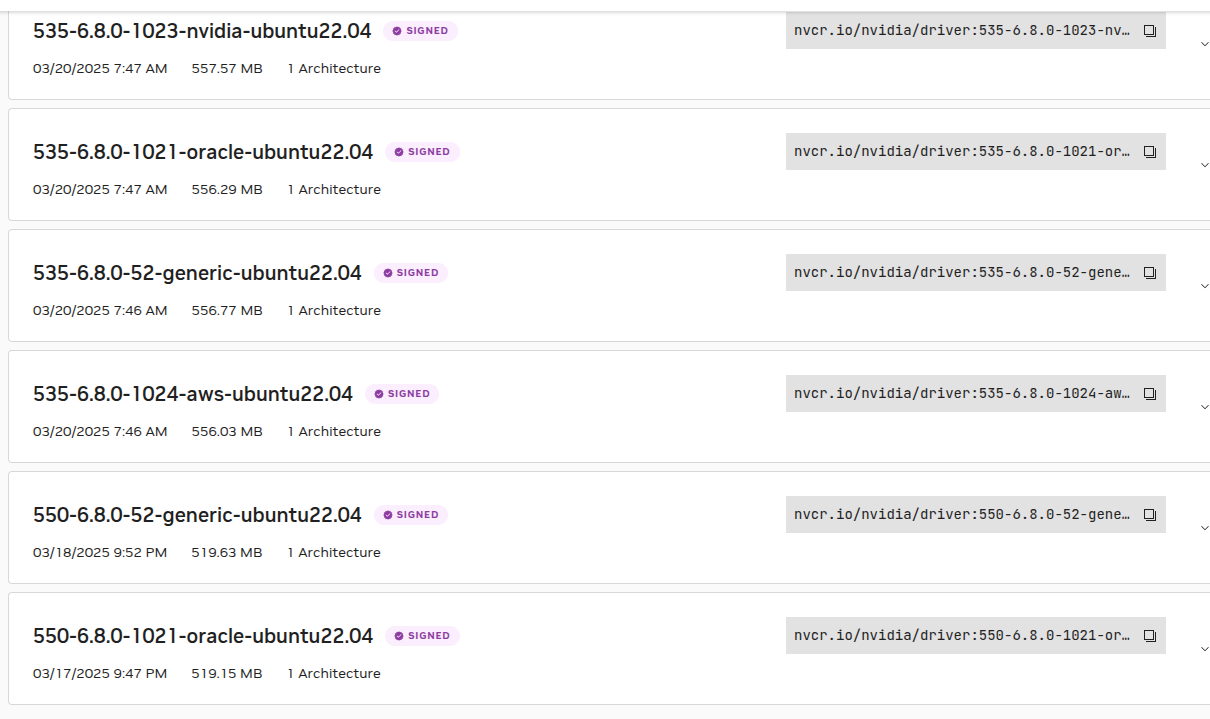
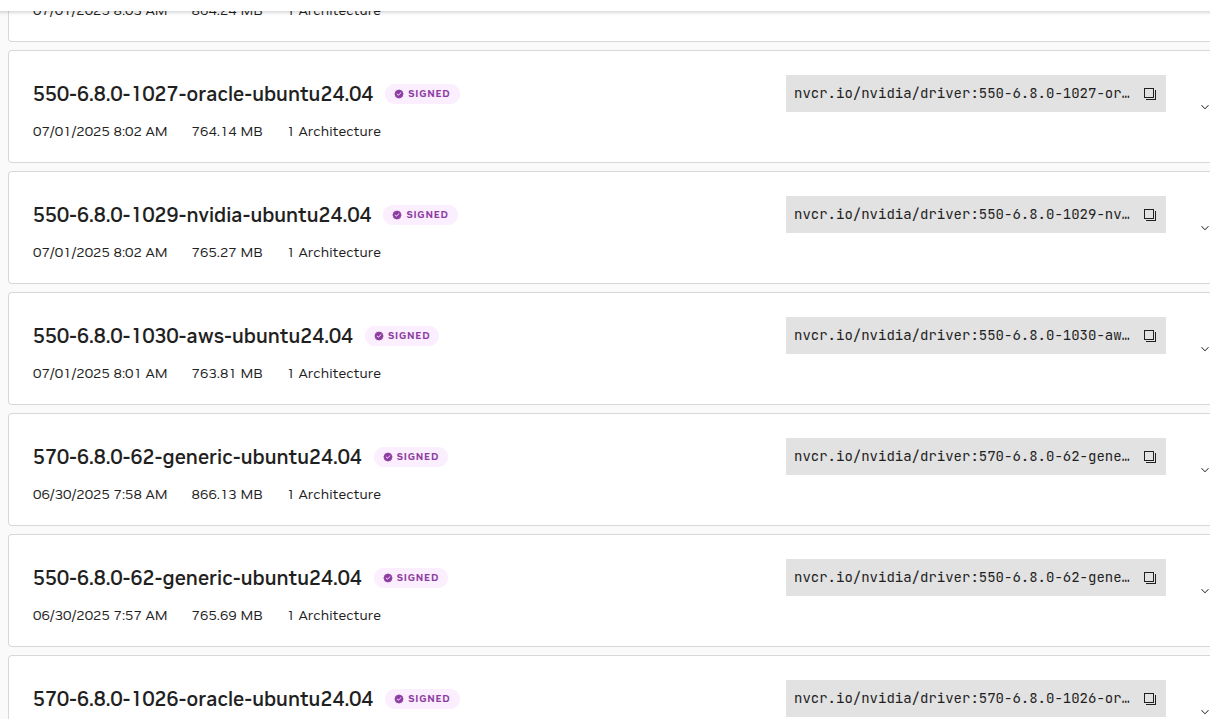
Ubuntu24, ubuntu22 都有支持。
# 安装指定版本的内核及其相关组件
sudo apt-get install -y \
linux-image-6.8.0-52-generic \ # 安装指定版本的Linux内核镜像
linux-headers-6.8.0-52-generic \ # 安装指定版本的内核头文件
linux-modules-extra-6.8.0-52-generic # 安装额外的内核模块
# 锁定内核版本,防止自动更新导致兼容性问题
sudo apt-mark hold linux-image-6.8.0-52-generic linux-headers-6.8.0-52-generic
# 查看GRUB引导菜单中的内核启动项
grep menuentry /boot/grub/grub.cfg
# 编辑GRUB默认配置文件,手动设置启动项
vi /etc/default/grub
# 使用sed命令自动修改GRUB默认启动项为指定内核版本
sudo sed -i 's/GRUB_DEFAULT=.*/GRUB_DEFAULT="Advanced options for Ubuntu>Ubuntu, with Linux 6.8.0-52-generic"/g' /etc/default/grub
# 更新GRUB引导配置并重启系统
sudo update-grub && sudo reboot
# 验证当前运行的内核版本
uname -r
# 检查是否已加载NVIDIA内核模块
lsmod | grep nvidia
# 重启GPU Operator部署以适配新的内核环境
kubectl rollout restart deployment gpu-operator -n gpu-operator5. 配置KubeVirt允许GPU设备透传
# 列出系统中的NVIDIA GPU设备及其PCI ID信息
lspci -nn | grep -i nvidia
# 导出当前KubeVirt自定义资源配置到本地文件
kubectl get kubevirt kubevirt -n kubevirt -o yaml > kubevirt.yaml
# 使用patch命令更新KubeVirt配置,添加允许的GPU设备列表
kubectl patch kubevirt kubevirt -n kubevirt --type merge -p '
{
"spec": {
"configuration": {
"permittedHostDevices": {
"pciHostDevices": [
{
"pciVendorSelector": "10de:1eb8",
"resourceName": "nvidia.com/TU104GL_TESLA_T4",
"externalResourceProvider": true
}
]
}
}
}
}'“pciVendorSelector”: “10de:1eb8”, # NVIDIA GPU的PCI厂商ID和设备ID “resourceName”: “nvidia.com/TU104GL_TESLA_T4”, # 在Kubernetes中显示的资源名称 “externalResourceProvider”: true # 表示资源由外部提供者管理
重要说明:
- 用户必须手动将直通GPU和vGPU资源添加到KubeVirt CR的permittedDevices列表中
- pciVendorSelector需要根据实际GPU设备的PCI ID进行配置
- resourceName可以根据实际GPU型号自定义命名
- externalResourceProvider设置为true表示由GPU Operator等外部组件管理资源
6. 在虚拟机中应用配置
# 应用配置到Kubernetes集群,创建带有GPU支持的虚拟机
kubectl apply -f poc-with-nvidia.yaml虚拟机配置文件解析 (poc-with-nvidia.yaml):
| ```yaml apiVersion: kubevirt.io/v1 kind: VirtualMachine metadata: name: tian-vm2 # 虚拟机名称 namespace: default # 所在命名空间 labels: app: tian-vm2 # 标签,用于标识应用 spec: running: true # 创建后立即启动虚拟机
template: metadata: labels: app: tian-vm2 # 模板标签 spec: # 节点亲和性配置,确保虚拟机调度到指定节点 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname # 匹配节点主机名 operator: In # 操作符:在列表中 values: - hi168-node1 # 目标节点名称
domain: cpu: cores: 2 # 分配2个CPU核心 resources: requests: memory: 1Gi # 请求1GB内存 devices: interfaces: - name: default masquerade: {} # 网络接口使用masquerade模式
# GPU设备透传配置 gpus: - deviceName: nvidia.com/TU104GL_TESLA_T4 # GPU资源名称(需与KubeVirt配置一致) name: gpu1 # GPU设备在虚拟机中的名称
# 磁盘设备配置 disks: - name: containerdisk1 disk: bus: virtio # 第一个磁盘使用virtio总线 - name: cloudinitdisk disk: bus: virtio # cloud-init磁盘使用virtio总线
# 网络配置 networks: - name: default pod: {} # 使用Pod网络
# 存储卷配置 volumes: - name: containerdisk1 persistentVolumeClaim: claimName: "tian-rbd-dv001" # 使用已有的PVC作为系统盘
- name: cloudinitdisk cloudInitNoCloud: userData: |- #cloud-config user: ubuntu # 默认用户名 password: ubuntu # 默认密码 chpasswd: { expire: False } # 密码永不过期 ``` |
关键配置说明:
- 节点亲和性: 确保虚拟机调度到预先配置好GPU环境的hi168-node1节点
- GPU透传: 通过gpus字段将物理GPU设备透传给虚拟机
- 资源分配: 为虚拟机分配2核CPU和1GB内存
- 存储配置: 使用现有的PVC作为系统盘,并配置cloud-init用于初始化系统
- 网络配置: 使用Pod网络并采用masquerade模式实现网络访问
验证命令:
# 查看虚拟机状态
kubectl get vm tian-vm2
# 查看虚拟机实例状态
kubectl get vmi tian-vm2
# 进入虚拟机控制台
kubectl virt console tian-vm2
lspci |grep -i nvidia参考文档
- [Upgrading the NVIDIA GPU Operator](https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/upgrade.html)
- [GPU Operator with KubeVirt](https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/gpu-operator-kubevirt.html)
- [NVIDIA GPU Driver](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/driver/tags)

















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









