



很多小伙伴在学习人工智能的时候,都会遇到训练模型时,自己电脑算力不够的问题。网上有很多优秀的云服务器提供算力。百度飞浆就是一个挺不错的选择,不多说,直接介绍怎么做,很容易,包看懂。(创建账号这些流程我就不写了)
目录
1、在飞浆创建项目
1.1、准备源代码和数据集
首先呢,你得准备好你自己的训练模型的源代码,然后压缩到一个压缩包内。
数据集也是一样的,把数据集划分好之后,压缩。注意,数据集必须小于50个G。
1.2、在飞浆创建一个项目
按顺序来,创建一个Notebook

然后取一个项目名,IDE选择JupyterLab就行,在项目运行的时候可以切换,这个无关紧要。

创建好之后会跳转到新的页面,点击右上角的启动环境,选择基础版环境,点击确定进入环境。
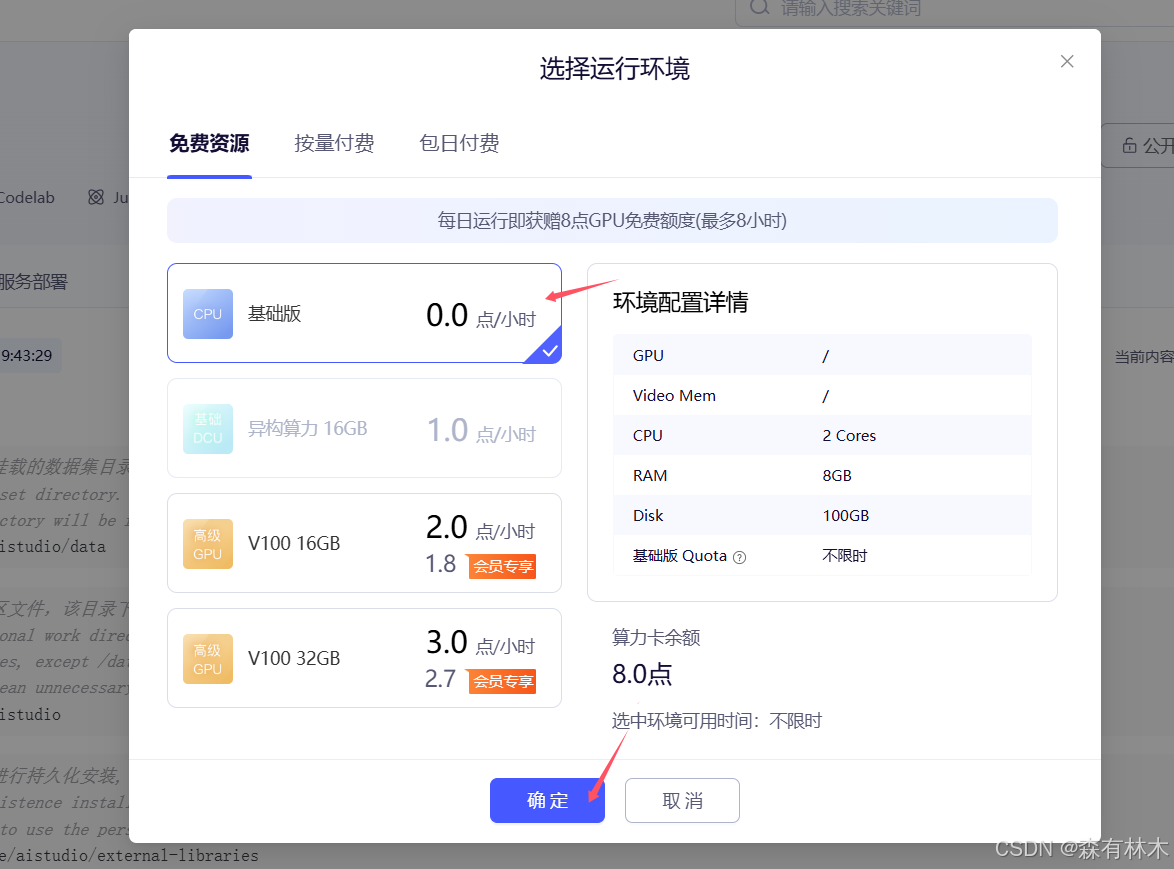
进入环境之后,点击图示图标,上传自己的源代码(压缩包文件),上传成功后,右击压缩包解压,之后可删除原压缩包。除data目录外,其他目录都会持久保存,尽可能小启动会快一点。之后可按照main.ipynb内的方法搭建持久化运行环境。没记错的话,官方的pip配置好了镜像源。
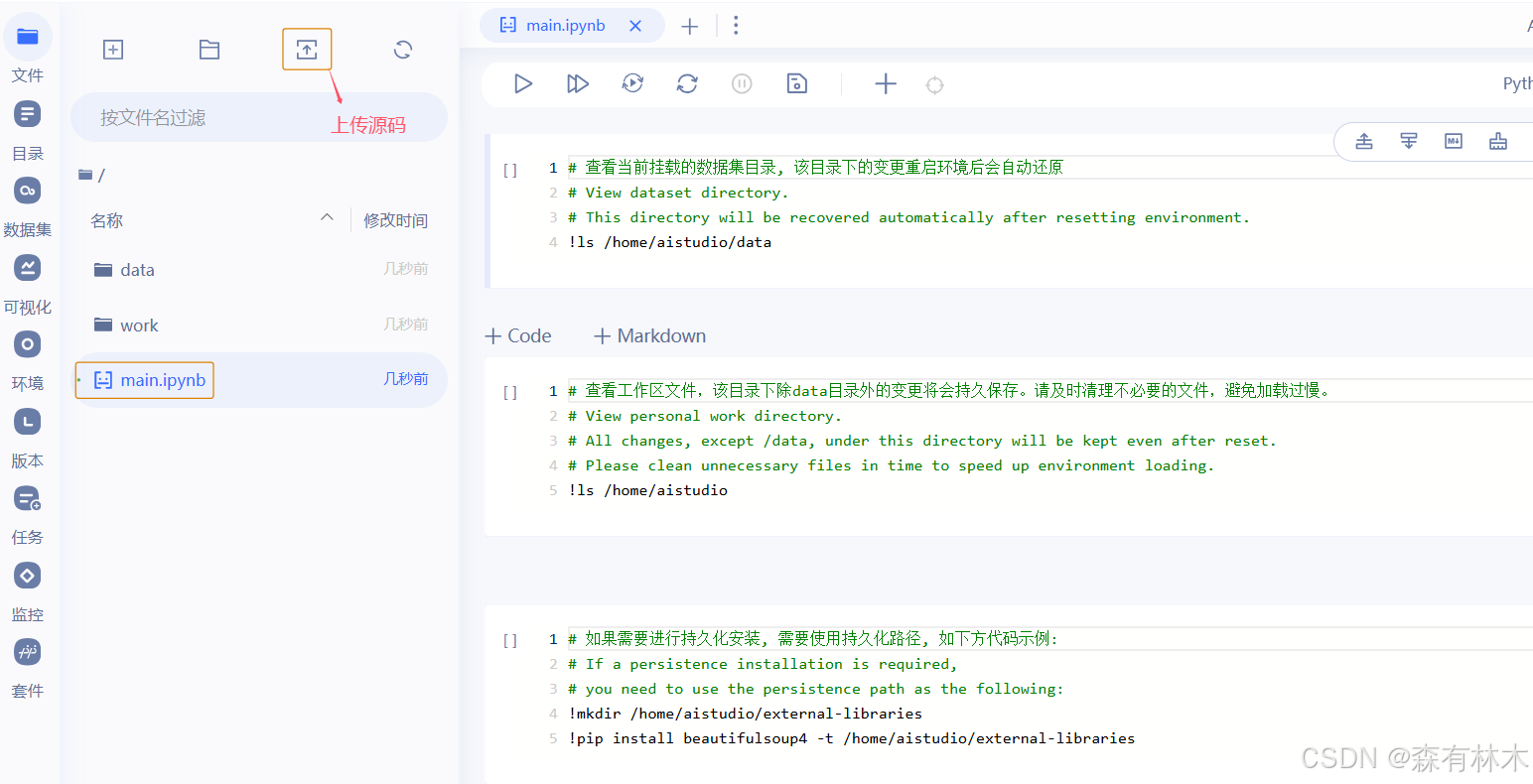
弄好之后,源代码和环境就都搭建好了。下次运行的时候就根据自己的需求,选择使用什么样的显卡。新用户会送100小时的V卡。用来学习还是很不错的。
1.3、上传数据集
依次点击 数据-创建数据集
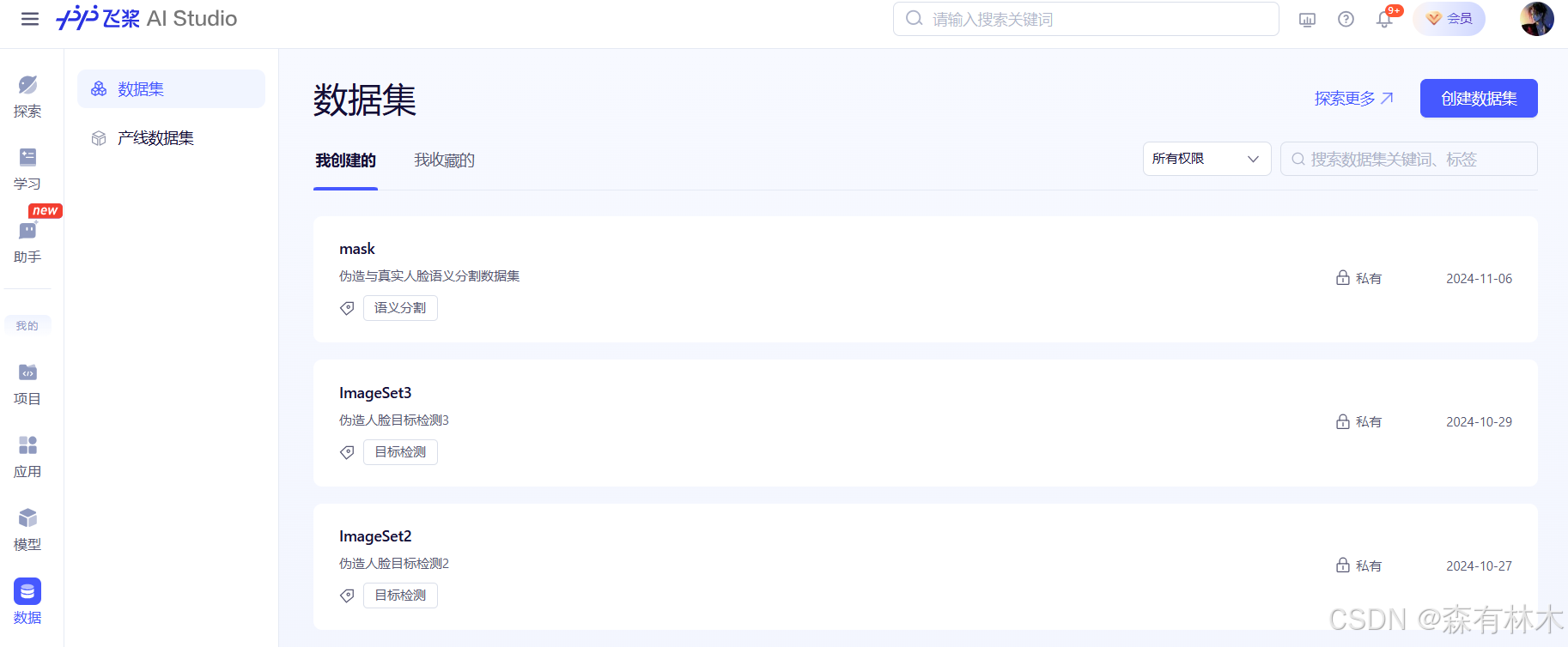
为数据集取个名字,然后点击上传文件,把准备好的压缩包上传到服务器。时间取决于数据集的大小。标签看自己数据集的情况选择,无关紧要。是否公开那里建议不公开,公开之后无法删除。摘要栏就简要结束一下就行,建议认真写一写,不然后面自己都忘了数据是什么东西。

2、运行项目
经过上面的步骤之后,就基本完工了。
2.1、把数据集挂载到项目
停止正在运行的项目。点击右边的修改项目。

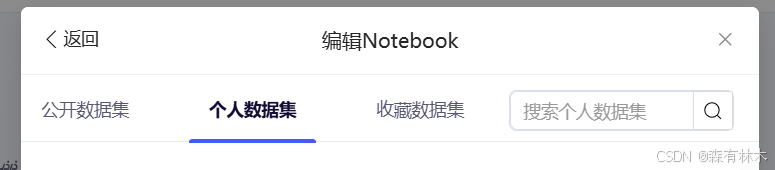
点击添加数据集

选择个人数据集,这里就有你刚刚创建好的数据集。最多选择两个,点击确定之后,会把你选择的数据集挂载到项目的data目录下,因为上传的是压缩包,所以等会进入环境之后,需要对数据集解压(注意,在data目录做的修改不会被保留)。
2.2、启动环境运行
挂载好数据集之后,根据自己需求选择相应配置的环境启动,进入环境之后,把源代码里有关于数据集的部分,换成data目录下对应的路径,这里我建议使用绝对路径。
然后运行训练模型相关的代码即可。训练过程文件和模型文件可保存到指定目录下,后续可以右击该目录,将结果下载下来。
熟练之后呢,就可以尝试飞浆其他功能,如去使用飞浆的模型和数据集、去创建运行时间更长的脚本任务等等。

















 1906
1906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









