







一、实验目的
通过编写和调试一个词法分析程序,掌握在对程序设计语言的源程序进
行扫描的过程中,将字符流形式的源程序转化为一个由各类单词构成的序列
的词法分析方法。
二、基本实验内容与要求
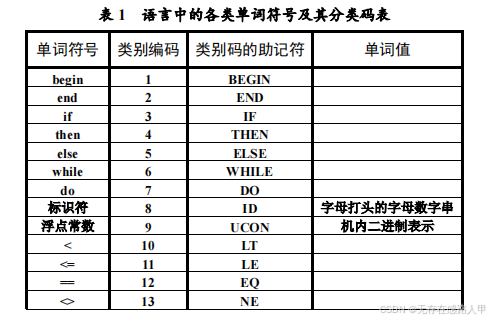
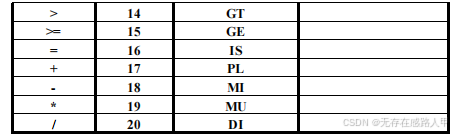
假定一种高级程序设计语言中的单词主要包括关键字 begin、end、if、then、
else、while、do;标识符;浮点常数;六种关系运算符;一个赋值符和四个
算术运算符,试构造能识别这些单词的词法分析程序(各类单词的分类码可
参见表 1)。
输入:由符合和不符合所规定的单词类别结构的各类单词组成的源程序
文件。
输出:把所识别出的每一单词均按形如(CLASS,VALUE)的二元式形
式输出,并将结果放到某个文件中。对于标识符和浮点常数,CLASS 字段为
相应的类别码的助记符;VALUE 字段则是该标识符、常数的具体值;对于关
键字和运算符,采用一词一类的编码形式,仅需在二元式的 CLASS 字段上
放置相应单词的类别码的助记符,VALUE 字段则为“空”。
要求:
1、上机前完成词法分析程序的程序流程设计,并选择好相应的数据结构。
2、用于测试扫描器的实例源文件中至少应包含两行以上的源代码。
3、对于输入的测试用例的源程序文件,词法正确的单词分析结果在输出
文件中以二元式形式输出,错误的字符串给出错误提示信息。
例如,若输入文件中的内容为:“if myid>=1.5 then x=y”,则输出文件
中的内容应为:
(IF, )
(ID,’myid’)
(GE, )
(UCON,1.5)
(THEN, )
(ID,’x’)
(IS, )
(ID,’y’)
三、参考实现方法
1、一般实现方法说明
词法分析是编译程序的第一个处理阶段,可以通过两种途径来构造词法
分析程序。其一是根据对语言中各类单词的某种描述或定义(如 BNF),用手
工的方式(例如可用 C 语言)构造词法分析程序。一般地,可以根据文法或
状态转换图构造相应的状态矩阵,该状态矩阵连同控制程序一起便组成了编
译器的词法分析程序;也可以根据文法或状态转换图直接编写词法分析程序。
构造词法分析程序的另外一种途径是所谓的词法分析程序的自动生成,即首
先用正规式对语言中的各类单词符号进行词型描述,并分别指出在识别单词时,词法分析程序所应进行的语义处理工作,然后由一个所谓词法分析程序
的构造程序对上述信息进行加工。如美国 BELL 实验室研制的 LEX 就是一个被
广泛使用的词法分析程序的自动生成工具。总的来说,开发一种新语言时,
由于它的单词符号在不停地修改,采用 LEX 等工具生成的词法分析程序比较
易于修改和维护。一旦一种语言确定了,则采用手工编写词法分析程序效率
更高。本实验建议使用手工编写的方法。
在一个程序设计语言中,一般都含有若干类单词符号,为此可首先为每
类单词建立一张状态转换图,然后将这些状态转换图合并成一张统一的状态
图,即得到了一个有限自动机,再进行必要的确定化和状态数最小化处理,
最后添加当进行状态转移时所需执行的语义动作,就可以据此构造词法分析
程序了。
2、单词分类与词法分析器的设计
为了使词法分析程序结构比较清晰,且尽量避免某些枝节问题的纠缠,
我们假定要编译的语言中,全部关键字都是保留字,程序员不得将它们作为
源程序中的标识符;在源程序的输入文本中,关键字、标识符、浮点常数之
间,若未出现关系和算术运算符以及赋值符,则至少须用一个空白字符加以
分隔。作了这些限制以后,就可以把关键字和标识符的识别统一进行处理。
即每当开始识别一个单词时,若扫视到的第一个字符为字母,则把后续输入
的字母或数字字符依次进行拼接,直至扫视到非字母、数字字符为止,以期
获得一个尽可能长的字母数字字符串,然后以此字符串查所谓保留字表(此
保留字表要事先造好),若查到此字符串,则取出相应的类别码;反之,则表
明该字符串应为一标识符。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2337
2337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









