




 本次实验旨在通过编写和调试词法分析程序,掌握如何将源程序的字符流转化为单词序列。实验要求识别特定语言的关键字、标识符、浮点常数等,并将结果以(CLASS,VALUE)格式输出到文件。实验提供了源程序和结果分析。
本次实验旨在通过编写和调试词法分析程序,掌握如何将源程序的字符流转化为单词序列。实验要求识别特定语言的关键字、标识符、浮点常数等,并将结果以(CLASS,VALUE)格式输出到文件。实验提供了源程序和结果分析。
一、实验目的
通过编写和调试一个词法分析程序,掌握在对程序设计语言的源程序进行扫描的过程中,将字符流形式的源程序转化为一个由各类单词构成的序列的词法分析方法。
二、基本实验内容与要求
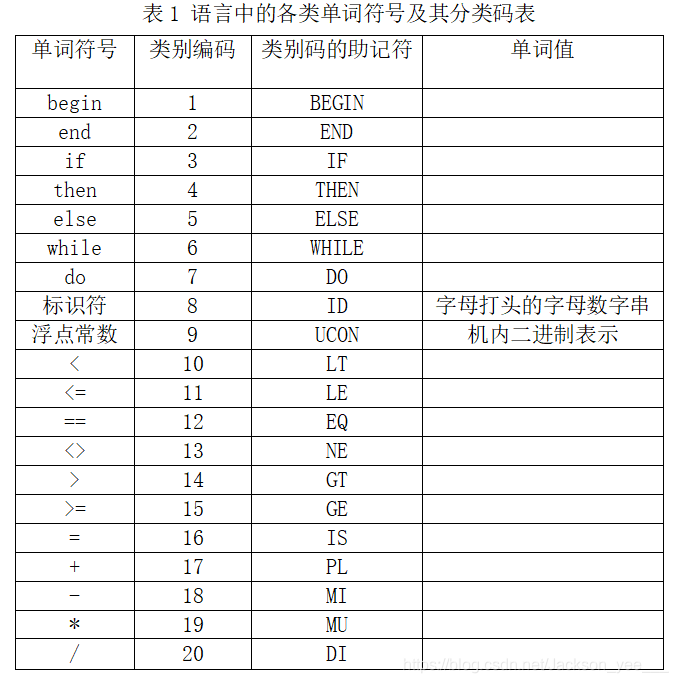
假定一种高级程序设计语言中的单词主要包括关键字 begin、end、if、then、else、while、do;标识符;浮点常数;六种关系运算符;一个赋值符和四个算术运算符,试构造能识别这些单词的词法分析程序(各类单词的分类码可参见表1)。
输入:由符合和不符合所规定的单词类别结构的各类单词组成的源程序文件。
输出:把所识别出的每一单词均按形如(CLASS,VALUE)的二元式形式输出,并将结果放到某个文件中。对于标识符和浮点常数,CLASS 字段为相应的类别码的助记符;VALUE 字段则是该标识符、常数的具体值;对于关键字和运算符,采用一词一类的编码形式,仅需在二元式的 CLASS 字段上放置相应单词的类别码的助记符,VALUE 字段则为“空”。
四、源程序
#include <iostream>
#include <string>
#include <iomanip>
#include <cstring>
#include <fstream>
#include <stdio.h>
#include <cassert>
#include <vector>
//#define _CRT_SECURE_NO_WARNINGS
using namespace std;
/*
begin BEGIN 1
end END 2
if IF 3
then THEN 4
else ELSE 5
while WHILE 6
do DO 7
标识符 ID 8
浮点常数UCON 9
< LT 10
<= LE 11
== EQ 12
<> NE 13
> GT 14
>= GE 15
= IS 16
+ PL 17
- MI 18
* MU 19
/ DI 20
*/
const char* table1[] = {
" ","begin","end","if","then","else","while","do" };//存放关键字
const char* table2[] = {
" ","BEGIN","END","IF","THEN","ELSE","WHILE","DO","ID","UCON","LT","LE","EQ","NE","GT","GE","IS","PL","MI","MU","DI" };//存放所有类别码的助记符
char TOKEN[20];//用来依次存放一个单词词文中的各个字符。
int lookup(char a[])/*查关键字是否存在,每调用一次,就以 TOKEN 中的字符串查保留字表,若查到,就将相应关键字的类别码赋给整型变量 c;否则将 c 置为零。*/
{
int i;
for (i = 1; i <= 7; i++)//查表1
{
if (strcmp(a, table1[i]) == 0)return i;
}
if (i  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8779
8779





 到【灌水乐园】发言
到【灌水乐园】发言







