







💕个人主页:Puszy-优快云博客💕
🎉 欢迎关注:👍点赞 📣留言 😍收藏 💖 💖 💖
只要信心不滑坡,办法总比困难多。 –– 《人民日报》
🌈🌈🌈往期精选链接
目录
📚一、什么是熵权法?
熵值法(Entropy Method)是一种多属性决策分析工具,它在诸如风险评估、资源分配等多个领域中发挥着重要作用。该方法的基本原理是利用信息熵这一概念来评估各个属性对于整个决策过程的贡献大小,进而确定每个属性的权重。信息熵是一种衡量信息不确定性或信息量大小的指标,熵值法通过计算各属性的熵值来反映其信息的有序程度,熵值越小,表明该属性的变异性越大,对决策的影响也越显著,因此赋予的权重也相对较高。通过这种方法,决策者可以更加客观和科学地确定各属性的权重,为最终的决策提供依据。
📚二、熵权法计算步骤
假设有个指标,
个样本,
表示第
个样本的第
个指标的数值
🚀2.1、标准化和正向化
| 正向指标 | |
| 反向指标 |
🚀2.2、计算相对比重
计算第个研究对象下第
项指标的比重
:
🚀2.3、计算熵值
计算第项指标的熵值
:
,
🚀2.4、计算差异系数
计算第项指标的差异系数
:
🚀2.5、计算评价指标权重
第项指标的权重:
🚀2.6、计算各样本综合评价得分
通过权重计算样本评价值,第个研究对象下第
项指标的评价值为
📚三、案例分析
本文使用2021全国大学生数学建模C题供应商评价问题为例,研究熵权法的实际解决问题的方案。
问题一需要针对附件1中402家原材料供应商的订货量和供货量进行量化分析,为您出最重要的50家供应商,本题使用平均供货强度、完成率、订单率和风险作为指标对供应商的重要性进行评估。
-
平均供货强度:将各家供应商 240周的供货量之和取均值定义为平均供货强度平均供货强度越大,说明供应商生产能力越强,越能保证企业生产,进而该家供应商重要性越强。
-
平均完成率:将402家供应商240周的总体供货量与接收到的订货量的比值定义为供应商的完成率,若完成率太高会提高仓储成本,若完成率太低则供应商供应能力不足。针对这一问题本文对完成率定义区间[0.8,1.2],若完成率在区间内或越接近该区间,说明供应商完成企业安排的能力越强,越能保证企业生产,进而该家供应商的重要性越强。
-
订单率:将每家供应商完成指标的供货量的周数在240周的占比定义为订单率7,观察致据,定义指标为10,即若供应商该周供货量不小于10,则算完成指标,记录完成指标的总周数,再求出总周数在240周的占比。因此,订单率越高,则供应商供货能力越强,越能保证企业生产,进而该家供应商的重要性越强。
-
风险:将各供应商240周的供贷量的标准差定义为风险n”由于在实际情况下企业往往选择供贷能力较稳定的供应商,因此供应商的重要性往往与其稳定性挂钩。风险越小,说明该供应商供货量越稳定,则企业选择的可能性越大,进雨供应商的重要性越强。
确定权重后,将每家供应商按平均供货强度、完成率、订单事、风险结合各自权重计算得分,得分公式如下:
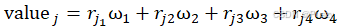
🚀3.1熵权法求解结果分析
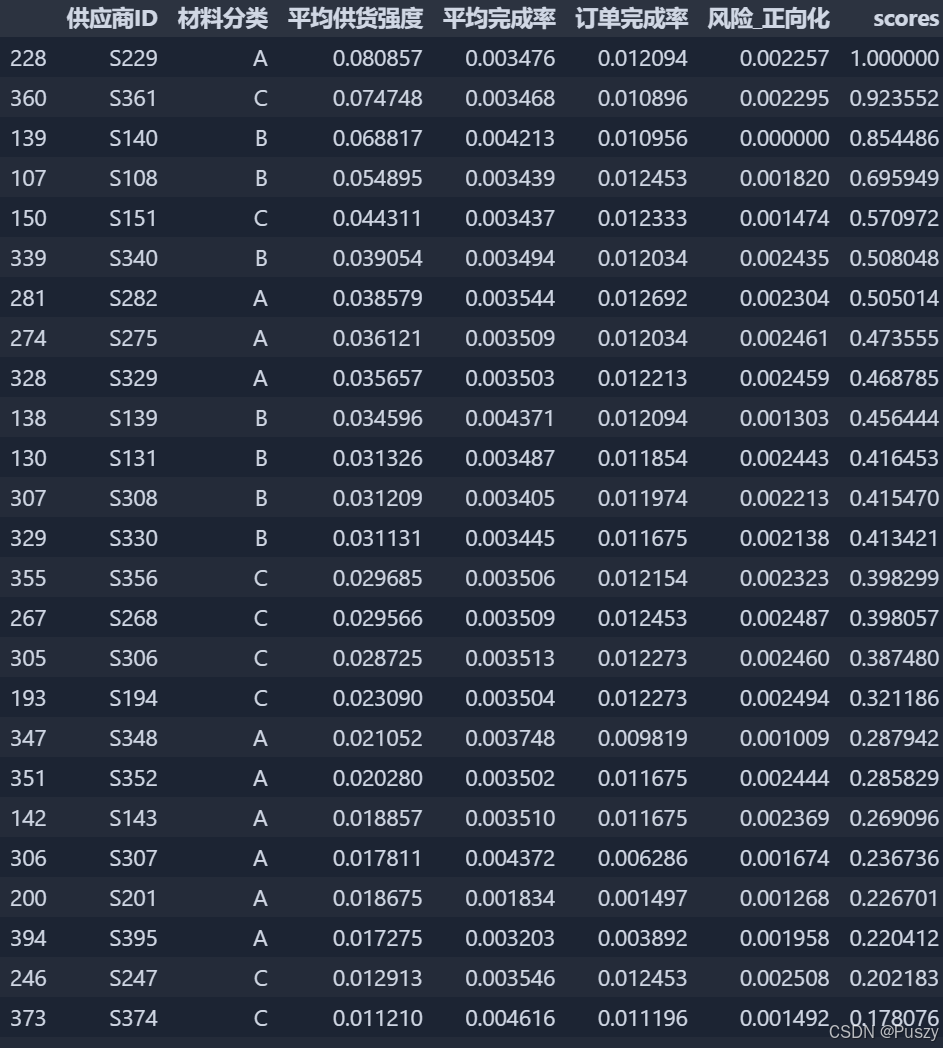
本文将4种指标作为评价标准对402家供应商进行重要性的评分,依据熵权法利用确定评价指标的权重,权重如表所示:
| 计算指数 | 平均供货强度 | 平均完成率 | 订单率 | 风险 |
| 熵值 | 0.5971 | 0.9753 | 0.8686 | 0.9991 |
| 权重 | 0.7198 | 0.0441 | 0.2346 | 0.0144 |
得分排名:结合得分公式,得出最后得分,并依据得分选出前50家供应商如下图所示
供应商分布如下:

📚四、代码实现
使用Jupyter Notebook分块实现
🚀4.1、导入相关的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='SimHei', weight='bold')
plt.rcParams['font.sans-serif']=['FangSong'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False 🚀4.2、数据处理和计算步骤实现
xls = pd.ExcelFile('./data/附件1 近5年402家供应商的相关数据.xlsx')
sheet_names = xls.sheet_names
print(sheet_names)
df_Order = pd.read_excel(xls, sheet_name='企业的订货量(m³)')
df_supply = pd.read_excel(xls, sheet_name='供应商的供货量(m³)')
df_supply['平均供货强度']=df_supply.iloc[:,2:].mean(axis=1)
df_supply['平均完成率']=(df_supply.iloc[:,2:-1]/df_Order.iloc[:,2:]).mean(axis=1)
comparison = df_supply.iloc[:,2:-2] > df_Order.iloc[:,2:]
count = comparison.apply(lambda x: (x == True).sum(),axis=1)
df_supply['订单完成率']=count/240
df_supply['风险']=df_supply.iloc[:,2:-3].std(axis=1)
#1.正向化和标准化
df_supply.iloc[:,-4:]=(df_supply.iloc[:,-4:] - df_supply.iloc[:,-4:].min()) / (df_supply.iloc[:,-4:].max() - df_supply.iloc[:,-4:].min())
df_supply['风险_正向化']=df_supply['风险'].apply(lambda x: df_supply['风险'].max()-x)
need=df_supply[['供应商ID','材料分类','平均供货强度','平均完成率','订单完成率','风险_正向化']]
sum=np.sum(need.iloc[:,2:],axis=0)
# print(sum)
# 2.计算比例值
need.iloc[:,2:]= need.iloc[:,2:].div(need.iloc[:,2:].sum(axis=0), axis=1)
# 3.计算熵值
k = 1.0 / np.log(len(need.iloc[:,2:]))
entropy = -k * (need.iloc[:,2:]* np.log(need.iloc[:,2:] + 1e-9)).sum(axis=0)
print(entropy)
# print(entropy)
# 4.计算差异系数
d = 1 - entropy
# print(d)
# 5.计算权重
weights = d / d.sum()
print(weights)
# print(weights)
# 6.计算每个供应商的得分
scores =need.iloc[:,2:] @ weights.values
#最大最小化得分
scores=(scores- scores.min()) / (scores.max() - scores.min())
need_copy = need.copy()
need_copy['scores'] = scores
# 7.按得分排序,取前50名
top_50_supplier= need_copy.iloc[np.argsort(need_copy['scores'])[-50:]]
top_50_supplier = top_50_supplier[::-1]
top_50_supplier🚀4.3、扇形图代码
counts = top_50_supplier['材料分类'].value_counts()
# 绘制扇形图
colors = [ 'gold', 'lightskyblue', 'lightcoral']
explode = (0.1, 0, 0)
plt.figure(figsize=(8, 8))
plt.pie(counts,explode=explode,labels=counts.index ,startangle=90,colors=colors,
autopct='%1.1f%%', shadow=True, radius=1.2)
plt.legend(loc='best')
# 添加标题
plt.title('材料分布')
plt.gca().set_aspect('equal')
plt.tight_layout()
# 显示图形
plt.show()📚参考链接
1、全国大学生数学竞赛官网+内附赛题全国大学生数学建模竞赛![]() https://www.mcm.edu.cn/
https://www.mcm.edu.cn/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











