



nnU-Net的文章:《nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation》。
nnU-Net介绍
nnU-Net 是德国癌症研究中心推出的“自调参”医学分割框架:它沿用经典 U-Net 结构,却能根据任意 CT/MR 数据自动算出网络形态、预处理、训练与后处理超参,零代码即可复现甚至超越论文 SOTA,被业内视为“无脑出 baseline 的神器”。
nnU-Net 的“网络骨架”仍然是 U-Net(encoder-decoder + skip-connection),但它并不是原样复制经典 U-Net,而是在结构、训练、推理全流程做了大量自动化微调。
关于U-Net的讲解请看博主的这篇文章:
nnU-Net改进点
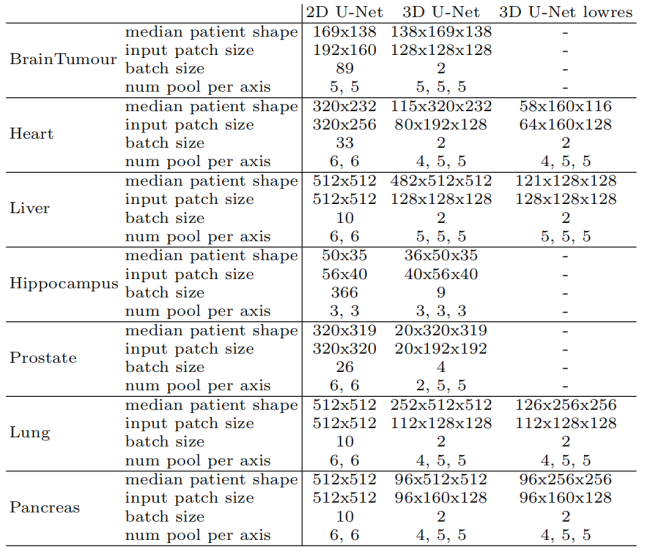
首先,nnU-Net会根据输入图像的维度(2D或3D)自动选择合适的网络架构。对于3D医学图像,nnU-Net会优先选择3D U-Net,以充分利用图像的三维信息。然而,当3D图像的某一维度分辨率较低(例如CT图像的z轴分辨率较低)时,3D卷积可能会引入过多的插值误差,此时nnU-Net会自动切换到2D U-Net或基于3D U-Net的级联架构(U-Net Cascade)。级联架构首先在低分辨率图像上进行初步分割,然后将分割结果上采样到原始分辨率,并作为额外的输入通道与原始图像一起输入到高分辨率的3D U-Net中进行精细分割。下图展示了nn-Unet针对不同数据集自动配置的三种基础网络结构的参数:
(1)将原始的ReLU激活函数替换为Leaky ReLU,以缓解梯度消失问题,Leaky ReLU公式为:
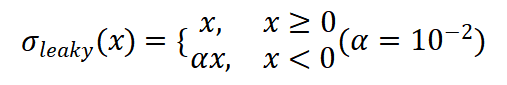
(2)将批量归一化(Batch Normalization)替换为实例归一化(Instance Normalization),以减少不同批次数据之间的统计差异对模型训练的影响。
实例归一化公式为:
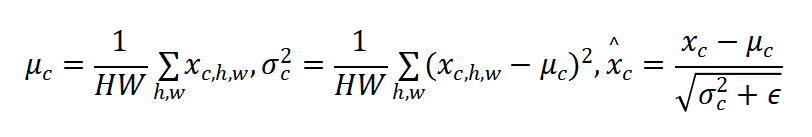
(3)nnU-Net统一采用了Dice损失与交叉熵损失相结合的混合损失函数,以平衡分割的准确性和平滑性。
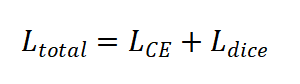
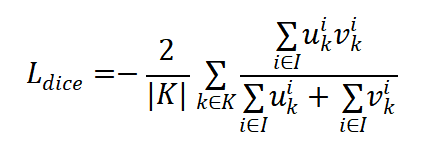
(4)Strided Conv代替max pooling:
通过可学习的卷积核对局部区域进行加权组合;
能自适应地提取下采样特征(比如边缘、纹理);
保留更多语义信息,且梯度可回传,训练更充分。
(5)自适应超参
nnU-Net的自适应超参贯穿“预处理-训练-后处理”三阶段且全程无需人工:
①预处理阶段,读取数据集指纹后立即用硬编码规则自动更新网络拓扑(降采样次数、初始通道、级联/2D/3D分支)、patch与batch大小;
②训练阶段,固定学习率等大部头,仅对“深层监督权重+损失Dice/CE比例”这6组配置做5折交叉验证后自动更新最优组合,并依指纹开关弹性形变等数据增强;
注:5折交叉验证把训练集平均分成5份,轮流取1份当验证折、其余4份训练,循环5次,确保每个样本都做过1次验证,既用来挑超参又给出稳定性能估计。
③训练一结束,nnU-Net立即在验证折上跑一次推理,接着跑两条固定规则的后处理:
A. remove_small_connected_components——把小于某个体素阈值的孤岛直接删掉;
B. apply_classes_postprocessing——对每个类别单独找一个最优概率阈值(0.2~0.8 步长 0.1),把低于阈值的体素置 0。
接着分别算一次 Dice,只要比“原图”高就保留,不高就退回原图。
如果这次任务同时训练了 2D、3D、级联三个模型,框架再把验证折上 Dice 最高的单个模型(或最优两模型平均)选为“最终集成方案”,至此所有超参锁定,推理时不再变动。
补充
下面的表格是unet与nnunet的区别:
| 模块 / 操作 | 原始 U-Net | nnU-Net(默认 3D) | 说明 |
|---|---|---|---|
| 下采样方式 | MaxPool3d(kernel=2) | Conv3d(..., stride=2, padding=1) | nnU-Net 用带步长的卷积代替池化,可学习、保留更多信息 |
| 上采样方式 | ConvTranspose3d(kernel=2, stride=2) | Interpolate(如 trilinear) + Conv3d(kernel=3, padding=1) | nnU-Net 不用转置卷积,避免棋盘伪影 |
| 归一化层 | 无 或 BatchNorm3d | InstanceNorm3d | 医学图像 batch size 小,BN 不稳定,IN 更鲁棒 |
| 激活函数 | ReLU | LeakyReLU(negative_slope=1e-2) | 缓解 ReLU 神经元死亡问题 |
| 初始通道数 | 64 | 32 | nnU-Net 起始通道更少,节省显存(尤其对 3D) |
| 卷积块内部顺序 | Conv → ReLU → Conv → ReLU | Conv → InstanceNorm → LeakyReLU → Conv → InstanceNorm → LeakyReLU | nnU-Net 在每个卷积后都加 Norm + leaky relu |
| 网络深度 | 固定(通常 4 层下采样) | 数据自适应(4–6 层) | nnU-Net 根据图像大小自动决定下采样次数 |


















 7282
7282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









