







倍增法(binary lifting)
概述
倍增法 和 二分法 的思想是 “相反”的,效率都很高。
二分法是每次将解存在的空间缩小一半,
倍增法是每次扩大一倍,快速扩展到大空间,线性的处理转化为对数级的处理,大大地优化时间复杂度。
故此,倍增法主要有两种应用场合:
- 区间问题中,从小区间倍增到大区间,求解和 区间查询 有关的问题。
- 【RMQ问题 (Range Maximum/Minimum Query) 区间最值查询】(ST 算法、后缀数组)
- 数值计算中,如空间内的元素满足倍增关系,或能借助倍增法计算,能用倍增法求解元素的精确值
- 【LCA 问题(Lowest Common Ancestor)最近公共祖先】。
倍增法原理
倍增 即“成倍增长”。实现倍增,有时即每步乘以二,如后缀数组,每次扩展字符长度。
在大多数题目中有更好地实现方法,即利用二进制本身的倍增特性,把一个数 N 用二进制展开。
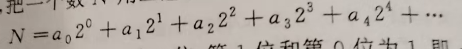
二进制划分反映了一种快速增长的特性,第 i 位的权值等于前面所有权值的和加一
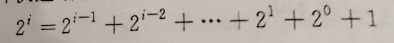
一个整数 n,它的二进制只有$ \log_2n $位,如果要从 0 增长到 n,可以以 $ 1,2,4,…2^k $ 为跳板,快速跳到 n,这些跳板有 k 个。
倍增法的局限性是需要提前计算出 这些跳板,即要求数据是静态不变的,不是动态变化的。如果数据发生变化则跳板需要重新计算,跳板就失去了意义,不能多次重复利用即不再能大大优化时间。
经典例题
国旗计划 洛谷 P4155 1. **倍增法 :**(1)化圆为线,把题目给的圆圈断开变成一条线,更方便分析和处理。
注意.圆圈是首尾相接的,断开后为了保持原来的首尾关系,需要把原来的圆圈复制再接入尾部。
(环的处理)环上的问题一般改成链来做,其主要方法是输入完数据后再复制一遍加到原数组后面
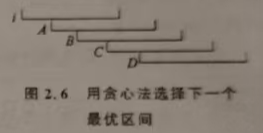
(2)贪心法,首先考虑从一个区间出发,如何选择所有的区间。
(贪心策略)选择一个区间 i 后,下一个区间只能从 左端点小于或等于右端点的那些区间中选择,在这些区同中选择右端点最大的那个区间,是最优的。
(示例)如图,选择区间i后,下一个区间可以从A、B、C中选择,它们的左端点都在i内部。C是最优的,因为它的右端点最远。选定C之后,再用贪心策略找下一个区间。这样找下去,就得到了所需的最少区间
(3)倍增法&动态规划(类似 ST 算法)。通过利用子问题的结果,配合倍增,快速预处理出 跳板。
为了进行高效的"次查询,可以用类似ST算法中的倍增法,预计算出-些“跳板”,快速找到后面的区间。
- O(n)方法

ST 算法(Sparse Table)
ST 算法
Sparse Table(ST 算法)ST(Sparse Table)算法是一种高效的静态查询数据结构,主要用于处理数组中区间最小值、最大值等查询问题。Sparse Table 的设计目标是优化对数组区间查询的时间复杂度,它非常适合用于那些元素不改变(静态)的情形。
Sparse Table 的基本概念
Sparse Table 通过预处理数组,构建一个二维表格,用于存储不同区间长度的最小值。这样,我们可以在查询时通过直接查表的方式,快速获取区间的最小值或最大值。
特点
- 静态数据结构:Sparse Table 是针对静态数组设计的,即数组中的元素不会改变。
- 查询时间复杂度为 O(1):通过预处理,查询任意区间的最小值或最大值的时间复杂度为常数级别 O(1)。
- 预处理时间复杂度为 O(n log n):需要通过预处理来构建 Sparse Table,时间复杂度为 O(n log n),其中 n 是数组的长度。
- 空间复杂度为 O(n log n):为了存储预处理信息,Sparse Table 占用的空间是 O(n log n)。
主要应用
Sparse Table 主要用于以下几种类型的区间查询问题:
- 区间最小值查询(Range Minimum Query, RMQ)
- 区间最大值查询
- 区间 GCD 查询(最大公约数)
Sparse Table 的构建与查询
1. 构建 Sparse Table
假设我们有一个长度为 n 的数组 arr,我们构建一个二维数组 st,其中 st[i][j] 表示从数组 arr[i] 开始,长度为 2^j 的区间的最小值(或最大值)。具体的构建过程如下:
st[i][0]就是数组的原始值,即st[i][0] = arr[i]。- 对于更大的区间,使用动态规划来计算:
st[i][j] = min(st[i][j-1], st[i + 2^(j-1)][j-1])- 这里,
st[i][j-1]表示从i开始的长度为2^(j-1)的最小值(或最大值),而st[i + 2^(j-1)][j-1]表示从i + 2^(j-1)开始的长度为2^(j-1)的最小值(或最大值)。
2. 查询操作
对于一个给定的区间 [L, R],我们要查找其最小值或最大值。由于区间长度可能不是 2^k 的形式,因此我们将区间分成两个部分:
- 从
L开始,查询长度为2^k的区间,最大长度不超过R - L + 1。 - 从
R结束,查询另一个长度为2^k的区间。
具体查询步骤:
- 找到区间
[L, R]所对应的最大k,使得2^k <= R - L + 1。 - 然后查询两个区间,
[L, L + 2^k - 1]和[R - 2^k + 1, R],从st数组中直接取值并返回结果。
示例代码
import math
构建 Sparse Table
def build_sparse_table(arr):
n = len(arr)
max_log = math.floor(math.log2(n)) + 1
st = [[0] * max_log for _ in range(n)]
# 初始化 st[i][0] = arr[i]
for i in range(n):
st[i][0] = arr[i]
# 动态规划计算 st[i][j]
for j in range(1, max_log):
for i in range(n - (1 << j) + 1):
st[i][j] = min(st[i][j - 1], st[i + (1 << (j - 1))][j - 1])
return st
查询区间 [L, R] 的最小值
def query(st, L, R):
length = R - L + 1
k = int(math.log2(length))
return min(st[L][k], st[R - (1 << k) + 1][k])
示例
arr = [1, 3, 2, 7, 9, 11, 6, 5, 8]
st = build_sparse_table(arr)
print(query(st, 2, 5))# 查询区间 [2, 5] 的最小值
时间复杂度分析
- 构建 Sparse Table:
- 对于每个区间长度
2^j,我们需要遍历数组的一部分来填充st[i][j]。 - 总体的时间复杂度为
O(n log n)。
- 对于每个区间长度
- 查询操作:
- 查询只涉及取两个值,并进行一次
min操作,因此时间复杂度为O(1)。
- 查询只涉及取两个值,并进行一次
优缺点
优点:
- 查询非常高效,适用于需要频繁查询的场景。
- 预处理和查询的时间复杂度非常优秀(
O(n log n)和O(1))。
缺点:
- 由于是静态数据结构,更新操作非常麻烦,不适合动态数据变化的情况。
- 空间复杂度较高,尤其是当数组长度很大时,可能需要大量内存。
总结
Sparse Table 是一种非常高效的静态查询数据结构,适用于处理区间最小值、最大值等问题。它通过预处理来加速查询,尤其在需要大量区间查询的情况下,能够提供极快的查询响应。然而,它不适合动态更新的场景,因为更新数据后需要重新构建表。
适用场景
- 静态数组 需要区间查询
- 大区间被两个小区间覆盖
- 小区间的重复覆盖不影响结果
- 可以用倍增法划分小区间 并计算
除了求 区间最值,还有区间最大公约数问题(RGQ, Range GCD Query)
RMQ 问题
RMQ(Range Minimum Query,区间最小值查询)问题是计算机科学中一个经典的算法问题,它的目标是在一个给定的数组或序列中,快速地找出任意区间(通常是子数组)内的最小值。RMQ问题在许多实际应用中都有广泛的应用,比如计算机图形学、数据压缩、网络流量分析等领域。
问题描述
给定一个数组 (A[1..n]) 和若干个查询,每个查询给定一个区间 ([l, r]),要求返回数组 (A) 在区间 ([l, r]) 上的最小值。多个查询的目标是要尽可能高效地计算每个区间的最小值。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











