






范数
通常我们⽤范数
(
norm
)
来衡量向量,向量的
L
p
范数定义为:
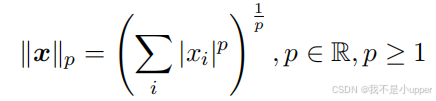
范数是满足以下条件的函数 ||・||:
- 非负性:||x|| ≥ 0,当且仅当 x=0 时取等
- 齐次性:||αx|| = |α|・||x||
- 三角不等式:||x + y|| ≤ ||x|| + ||y||
范数:也是从向量到矩阵的多元度量工具
在数学与机器学习领域,范数是度量向量、矩阵特性的核心工具,不同类型的范数因定义与特性差异,适用于多样场景。
一、向量范数:多维空间的 “长度” 度量
-
L² 范数(欧几里得范数) 计算向量到原点的直线距离,公式为
。实际应用中,常使用其平方形式
,因计算梯度更便捷 —— 梯度分量仅依赖向量对应分量,而非像 L² 范数梯度需依赖整个向量。
-
L¹ 范数 专注区分向量中的 0 与非 0 元素,计算元素绝对值之和:
。其在所有方向增长速率一致的特性,让它在突出非零元素的任务中表现优异。
-
L⁰范数 统计向量非零元素个数,但因不满足范数的三角不等式等条件,严格来说不算范数。实际中,L¹ 范数常作为其替代,既保留区分 0 与非 0 的能力,又符合范数数学定义。
-
L∞范数(最大范数) 取向量元素绝对值的最大值,公式为
。例如向量 [1.0, 3.0],其 L∞范数为 3.0,仅关注最大元素。
二、矩阵范数:矩阵 “规模” 的量化工具
机器学习中,F 范数(Frobenius norm)用于衡量矩阵,计算矩阵所有元素平方和的平方根: ,全面反映矩阵元素的综合规模。
三、代码实现与解析
import numpy as np
from sklearn.linear_model import Lasso, Ridge
# 向量范数计算示例
vec = np.array([3, 4])
# L0范数(非零元素个数)
l0 = np.count_nonzero(vec) # 结果: 2
# L1范数
l1 = np.linalg.norm(vec, ord=1) # 结果: 7.0
# L2范数
l2 = np.linalg.norm(vec, ord=2) # 结果: 5.0
# L∞范数
l_inf = np.linalg.norm(vec, ord=np.inf) # 结果: 4.0
# 机器学习应用示例
X = np.array([[1, 2], [3, 4], [5, 6]])
y = np.array([1, 2, 3])
# L1正则化(Lasso回归)
lasso = Lasso(alpha=0.1)
lasso.fit(X, y)
print("L1正则化系数:", lasso.coef_) # 可能产生稀疏解
# L2正则化(Ridge回归)
ridge = Ridge(alpha=0.1)
ridge.fit(X, y)
print("L2正则化系数:", ridge.coef_) # 参数更平滑L0 范数(非零元素计数)
vec = np.array([3, 4])
l0 = np.count_nonzero(vec) # 结果: 2- 计算方式:统计向量中非零元素的个数
- 几何意义:表示向量中非零维度的数量
- 结果分析:向量 [3,4] 两个元素均非零,故 L0 范数为 2
- 特点:非连续不可导,难以直接优化,多用于理论分析
L1 范数(绝对值之和)
l1 = np.linalg.norm(vec, ord=1) # 结果: 7.0- 计算方式:各元素绝对值之和(3+4=7)
- 几何意义:曼哈顿距离(城市街区距离)
- 结果分析:对所有元素的贡献线性叠加,与元素符号无关
- 特点:对异常值不敏感,梯度稳定,容易产生稀疏解
L2 范数(欧氏距离)
l2 = np.linalg.norm(vec, ord=2) # 结果: 5.0- 计算方式:平方和的平方根(√(3²+4²)=5)
- 几何意义:欧几里得空间中的直线距离
- 结果分析:通过平方放大较大元素的贡献(4²=16 远大于 3²=9)
- 特点:对较大元素敏感,容易产生平滑解,计算效率高
L∞范数(最大绝对值)
l_inf = np.linalg.norm(vec, ord=np.inf) # 结果: 4.0- 计算方式:向量元素的最大绝对值
- 几何意义:切比雪夫距离(棋盘距离)
- 结果分析:仅关注最大元素,完全忽略其他元素
- 特点:对极端值高度敏感,常用于误差界分析
| 范数类型 | 数学特性 | 敏感性 | 几何形状 | 优化行为 |
|---|---|---|---|---|
| L0 | 离散计数 | 无 | 超立方体顶点 | 稀疏性最优 |
| L1 | 线性求和 | 异常值鲁棒 | 菱形 | 稀疏解(参数归零) |
| L2 | 平方加权 | 异常值敏感 | 圆形 | 平滑解(参数趋近零) |
| L∞ | 最大值选取 | 极端值敏感 | 正方形 | 误差控制 |
四、关键区别与选择建议
-
稀疏性:L0 > L1 > L2 > L∞
- L1 在稀疏性和计算效率间取得平衡
- L0 因离散特性难以优化,通常用 L1 近似
-
误差敏感性:
- L1 对异常值更鲁棒(线性增长)
- L2 对异常值敏感(平方增长)
-
几何特性:
- L1 的等高线是菱形,易在坐标轴上产生顶点解
- L2 的等高线是圆形,最优解倾向原点附近
五、进阶应用场景
-
深度学习:
- L2 范数用于权重衰减(Weight Decay)
- L1 范数用于稀疏连接(如剪枝预处理)
-
图像处理:
- L1 范数用于图像去噪(TV 正则化)
- L∞范数用于图像匹配(最大差异最小化)
-
强化学习:
- L2 范数用于策略梯度的 KL 散度约束
- L∞范数用于 Q 值函数的误差界估计
六、扩展知识
- 矩阵范数:如 Frobenius 范数(矩阵元素平方和)
- 范数诱导的距离:d (x,y) = ||x - y||
- 对偶范数:L1 与 L∞互为对偶范数
建议在实际应用中:
- 优先尝试 L2 正则化,除非需要显式稀疏性
- 高维数据可尝试弹性网络(L1+L2 组合)
- 对异常值敏感的场景考虑 Huber 损失(结合 L1/L2)


















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









