







在实时目标检测这一领域,YOLO 系列模型长期以来都占据着举足轻重的地位。它能在延迟和精度之间找到良好的平衡点,凭借这一优势,成为了该领域的主导框架,被广泛应用于众多实际场景中。
与此同时,注意力机制在建模能力方面展现出了显著的优势。基于注意力机制的视觉 Transformer,即便是小模型,也能在处理图像时精准捕捉长距离依赖关系,挖掘复杂特征,对图像内容进行更深入的理解和表达。
然而,在 YOLO 系列模型的发展过程中,一个现象值得关注:大多数的 YOLO 架构设计依旧将重点放在 CNNs 上,没有大规模采用注意力机制。追根溯源,这是因为注意力机制存在一些固有的效率问题。一方面,其计算复杂度与输入序列长度呈二次方增长关系,一旦处理高分辨率图像这类大输入时,计算量便会呈指数上升,对硬件计算资源提出了极高要求;另一方面,注意力计算时的内存访问模式效率较低,和 CNNs 结构化、局部化的高效内存访问方式相比,存在较大差距。综合这两个因素,在计算资源预算相似的情况下,基于 CNN 的架构运行速度大约是基于注意力的架构的 3 倍。这一巨大的速度差距,使得对推理速度极为敏感的 YOLO 系统难以广泛应用注意力机制,严重制约了 YOLO 模型借助注意力机制强大的建模能力来进一步提升性能。
正是在这样的背景下,该论文提出了 YOLOv12,致力于攻克这些难题,全面提升模型在实时目标检测任务中的性能表现。
改进与创新点
1. 提出简单高效的区域注意力模块(A2):通过简单地将特征图在水平或垂直方向划分为多个区域(默认 4 个),避免了复杂的窗口划分操作,在保持较大感受野的同时,将注意力计算复杂度从降低到 ,显著提升了速度,且对性能影响较小。
2. 引入残差高效层聚合网络(R-ELAN):针对注意力机制带来的优化挑战(主要在大规模模型中),R-ELAN 基于原始 ELAN 进行了两项改进。一是引入块级残差设计和缩放技术,对于大模型(如 YOLOv12-L/X),这种设计是稳定训练的关键;二是重新设计特征聚合方法,采用瓶颈结构,在保持特征集成能力的同时,降低了计算成本和参数 / 内存使用。
3. 进行架构改进:对传统注意力架构进行升级,引入 FlashAttention 解决注意力的内存访问问题;去除位置编码,使模型更简洁快速;将 MLP 比例从 4 调整为 1.2(N/S/M-scale 模型为 2),平衡注意力和前馈网络的计算,以获得更好性能;减少堆叠块的深度,便于优化;尽可能使用卷积算子,利用其计算效率。此外,保留 YOLO 系统的分层设计,去除骨干网络最后阶段堆叠的三个块,仅保留一个 R-ELAN 块,减少总块数,有助于优化。
YOLOv12视频讲解:YOLOv12 论文结构解析:强势来临,超越 YOLOv11!_哔哩哔哩_bilibili
1. 区域注意力模块
设计理念:传统注意力机制计算复杂度高,限制了其在实时目标检测中的应用。A2 模块旨在通过一种简单高效的方式降低注意力计算复杂度,同时保持较大感受野。它将特征图在水平或垂直方向划分为多个区域(默认 4 个),这种划分方式避免了复杂的窗口划分操作,仅需简单的重塑(reshape)操作,就能实现注意力计算的加速。

实现方式:在代码实现中,A2 模块(AAttn类)首先通过qkv卷积层生成查询(q)、键(k)和值(v)张量,然后根据area参数对张量进行处理。如果area > 1,则对qkv张量进行重塑,之后根据是否满足使用 FlashAttention 的条件(x.is_cuda and USE_FLASH_ATTN),选择不同的注意力计算方式,最后通过投影层(proj)输出结果,并结合位置感知卷积(pe)增强位置信息感知。

2. 残差高效层聚合网络(R-ELAN)
针对问题:高效层聚合网络(ELAN,也就是下面的A2C2模块)旨在改进特征聚合,但原 ELAN 架构存在稳定性问题,会导致梯度阻塞且缺乏从输入到输出的残差连接。在基于注意力机制构建网络时,这些问题更加凸显,使得 L - 和 X-scale 模型难以收敛或训练不稳定。
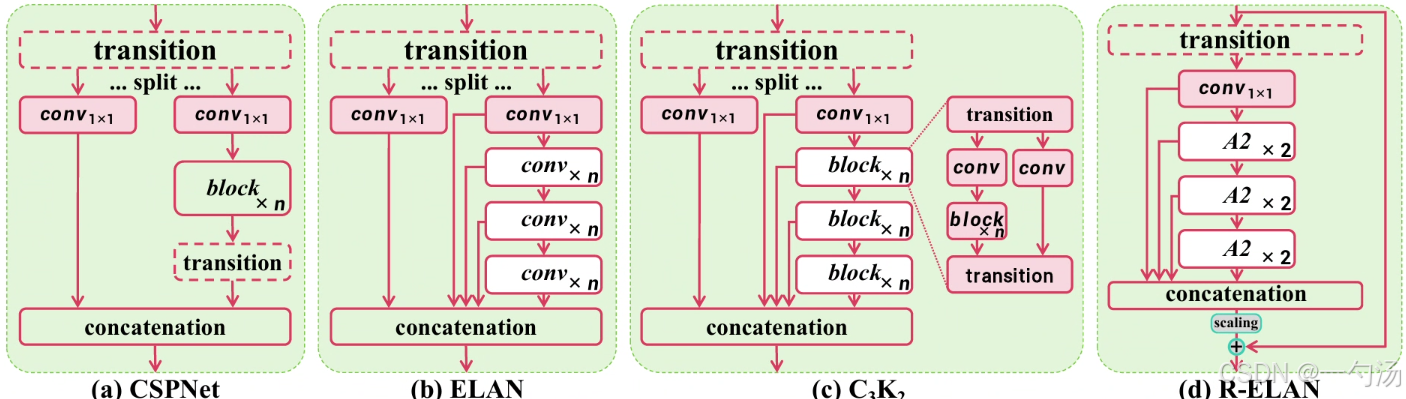
设计改进:R-ELAN 引入了块级残差设计和缩放技术,从输入到输出添加带有缩放因子(默认 0.01)的残差快捷连接,这种设计类似层缩放,但针对整个模块,有助于稳定训练。特别是对于大模型(如 YOLOv12-L/X),残差连接是稳定训练的关键。同时,重新设计了特征聚合方法,原 ELAN 将过渡层输出拆分处理后再拼接,而 R-ELAN 先通过过渡层调整通道维度,生成单特征图,再经后续模块处理和拼接,形成瓶颈结构,这样既保留了特征集成能力,又降低了计算成本和参数 / 内存使用

上面两幅图都是A2C2f模块,左边是使用A2模块(A2也就是图中的ABlock)的时候,右边是不使用A2模块的时候。下面是C3K2和C2PSA模块的图,方便大家对比学习。从图中我们可以看出A2C2f主要是根据C2PSA模块改进,当你不使用A2模块的时候,他的结构与C3K2模块有点类似。他们之间还有个很大的区别是没有split。

3.运行YOLOv12
第一步下载代码,解压文件
第二步,使用Pycharm打开文件,下面这名字是我重命名的原因,你们因该是ultralytics-main
 第三步,添加train_yolov12,目录要选择正确,不然YOLO导入错误。
第三步,添加train_yolov12,目录要选择正确,不然YOLO导入错误。
from sympy import false
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
if __name__=="__main__":
# 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO(r"E:\Part_time_job_orders\YOLO\YOLOv12\ultralytics\cfg\models\12\yolo12.yaml")\
.load(r'E:\Part_time_job_orders\YOLO\YOLOv12\yolo12n.pt') # build from YAML and transfer weights
results = model.train(data=r'E:\Part_time_job_orders\YOLO\YOLOv12\ultralytics\cfg\datasets\VOC_my.yaml',
epochs=300,
imgsz=640,
batch=64,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
amp = True
)
第四步,下载YOLOv12的权重,有这个可以更好的训练模型,是你模型学习更优。下载后放入到代码中。下面是下载链接
YOLO12 -Ultralytics YOLO 文档
 第五步,数据集问题,我的数据集的目录是这个样子的
第五步,数据集问题,我的数据集的目录是这个样子的
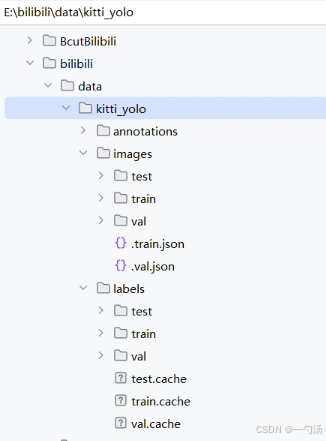
数据集文件放置的位置
 数据集里面的内容
数据集里面的内容
path: E:/bilibili/data/kitti_yolo/
# path: D:/TT_GG_FF/Data/smoke_1/
train: # train images (relative to 'path') 16551 images
- images/train/
val: # val images (relative to 'path') 4952 images
- images/val/
test: # test images (optional)
- images/test/
# Classes
names:
0 : car
1 : Pedestrian
2 : Cyclist
代码:ultralytics/ultralytics: Ultralytics YOLO11 🚀
原作者代码:sunsmarterjie/yolov12: YOLOv12: Attention-Centric Real-Time Object Detectors
论文:[2502.12524] YOLOv12: Attention-Centric Real-Time Object Detectors
以上就是我对YOLOv12模型的分析啦,感谢观看!!!


















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









