




本文为pandas菜鸟学习做的总结
一. 介绍
(1)Pandas 是一个流行的 Python 库,用于数据分析和数据操作。它提供了数据结构和函数,使得在 Python 中进行数据操作更加简单和高效。Pandas 最主要的数据结构是 Series 和 DataFrame。
- Series 是一维标记数组,可以包含任何数据类型。每个 Series 都有一个与之关联的索引,可以用于访问数据项。
- DataFrame 是一个二维的、大小可变的数据结构,类似于电子表格或 SQL 数据表。它由行和列组成,每列可以包含不同的数据类型。DataFrame 也有索引,用于标识行和列。
(2)Pandas 提供了广泛的功能,包括数据读取、数据清洗、数据转换、数据筛选、数据聚合和统计分析等。它通常与其他 Python 库(如 NumPy、Matplotlib 和 Scikit-learn)一起使用,为数据科学和机器学习提供了强大的工具集。
- 数据清洗:处理缺失数据、重复数据等。
- 数据转换:改变数据的形状、结构或格式。
- 数据分析:进行统计分析、聚合、分组等。
- 数据可视化:通过整合 Matplotlib 和 Seaborn 等库,可以进行数据可视化。
二. 应用
-
数据清洗和预处理: Pandas被广泛用于清理和预处理数据,包括处理缺失值、异常值、重复值等。它提供了各种方法来使数据更适合进行进一步的分析。
-
数据分析和统计: Pandas使数据分析变得更加简单,通过DataFrame和Series的灵活操作,用户可以轻松地进行统计分析、汇总、聚合等操作。从均值、中位数到标准差和相关性分析,Pandas都提供了丰富的功能。
-
数据可视化: 将Pandas与Matplotlib、Seaborn等数据可视化库结合使用,可以创建各种图表和图形,从而更直观地理解数据分布和趋势。这对于数据科学家、分析师和决策者来说都是关键的。
-
时间序列分析: Pandas在处理时间序列数据方面表现出色,支持对日期和时间进行高效操作。这对于金融领域、生产领域以及其他需要处理时间序列的行业尤为重要。
-
机器学习和数据建模: 在机器学习中,数据预处理是非常关键的一步,而Pandas提供了强大的功能来处理和准备数据。它可以帮助用户将数据整理成适用于机器学习算法的格式。
-
数据库操作: Pandas可以轻松地与数据库进行交互,从数据库中导入数据到DataFrame中,进行分析和处理,然后将结果导回数据库。这在数据库管理和分析中非常有用。
-
实时数据分析: 对于需要实时监控和分析数据的应用,Pandas的高效性能使其成为一个强大的工具。结合其他实时数据处理工具,可以构建实时分析系统。
Pandas 在许多领域中都是一种强大而灵活的工具,为数据科学家、分析师和工程师提供了处理和分析数据的便捷方式。
三. 安装
安装非常简单
pip install pandas
或者,在conda建立的环境中
conda install pandas
安装后可查看版本
import pandas
print(pandas.__version__)
打印

四. 数据结构
1. Series
Series 特点:
-
索引: 每个
Series都有一个索引,它可以是整数、字符串、日期等类型。如果没有显式指定索引,Pandas 会自动创建一个默认的整数索引。 -
数据类型:
Series可以容纳不同数据类型的元素,包括整数、浮点数、字符串等。

(摘自菜鸟教程)
Series 是 Pandas 中的一种基本数据结构,类似于一维数组或列表,但具有标签(索引),使得数据在处理和分析时更具灵活性。
以下是关于 Pandas 中的 Series 的详细介绍: 创建 Series: 可以使用 pd.Series() 构造函数创建一个 Series 对象,传递一个数据数组(可以是列表、NumPy 数组等)和一个可选的索引数组。
pandas.Series( data, index, dtype, name, copy)
参数说明:
-
data:一组数据(ndarray 类型)。
-
index:数据索引标签,如果不指定,默认从 0 开始。
-
dtype:数据类型,默认会自己判断。
-
name:设置名称。
-
copy:拷贝数据,默认为 False。
示例
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
print("------------------------------")
print(myvar[1])
打印
左列的0,1,2为索引,右列的0,1,2为相应索引对应的值

(1)指定索引值
示例
import pandas as pd
a = [11, 22, 33]
myvar = pd.Series(a, index=['a', 'b', 'c'])
print(myvar)
print("------------------------------")
print(myvar["c"])
打印

(2)使用 key/value 创建
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)
打印

只需要字典中的一部分数据,只需要指定需要数据的索引即可
示例
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2])
print(myvar)
打印

(3)设置 Series 名称参数
示例
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)
打印

(4)其他基本操作
基本操作:
# 获取值
value = series[2] # 获取索引为2的值
# 获取多个值
subset = series[1:4] # 获取索引为1到3的值
# 使用自定义索引
value = series_with_index['b'] # 获取索引为'b'的值
# 索引和值的对应关系
for index, value in series_with_index.items():
print(f"Index: {index}, Value: {value}")
基本运算:
# 算术运算
result = series * 2 # 所有元素乘以2
# 过滤
filtered_series = series[series > 2] # 选择大于2的元素
# 数学函数
import numpy as np
result = np.sqrt(series) # 对每个元素取平方根
属性和方法:
# 获取索引
index = series_with_index.index
# 获取值数组
values = series_with_index.values
# 获取描述统计信息
stats = series_with_index.describe()
# 获取最大值和最小值的索引
max_index = series_with_index.idxmax()
min_index = series_with_index.idxmin()
(5)注意事项
Series中的数据是有序的。- 可以将
Series视为带有索引的一维数组。 - 索引可以是唯一的,但不是必须的。
- 数据可以是标量、列表、NumPy 数组等。
2. DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
DataFrame 特点:
-
列和行:
DataFrame由多个列组成,每一列都有一个名称,可以看作是一个Series。同时,DataFrame有一个行索引,用于标识每一行。 -
二维结构:
DataFrame是一个二维表格,具有行和列。可以将其视为多个Series对象组成的字典。 -
列的数据类型: 不同的列可以包含不同的数据类型,例如整数、浮点数、字符串等。
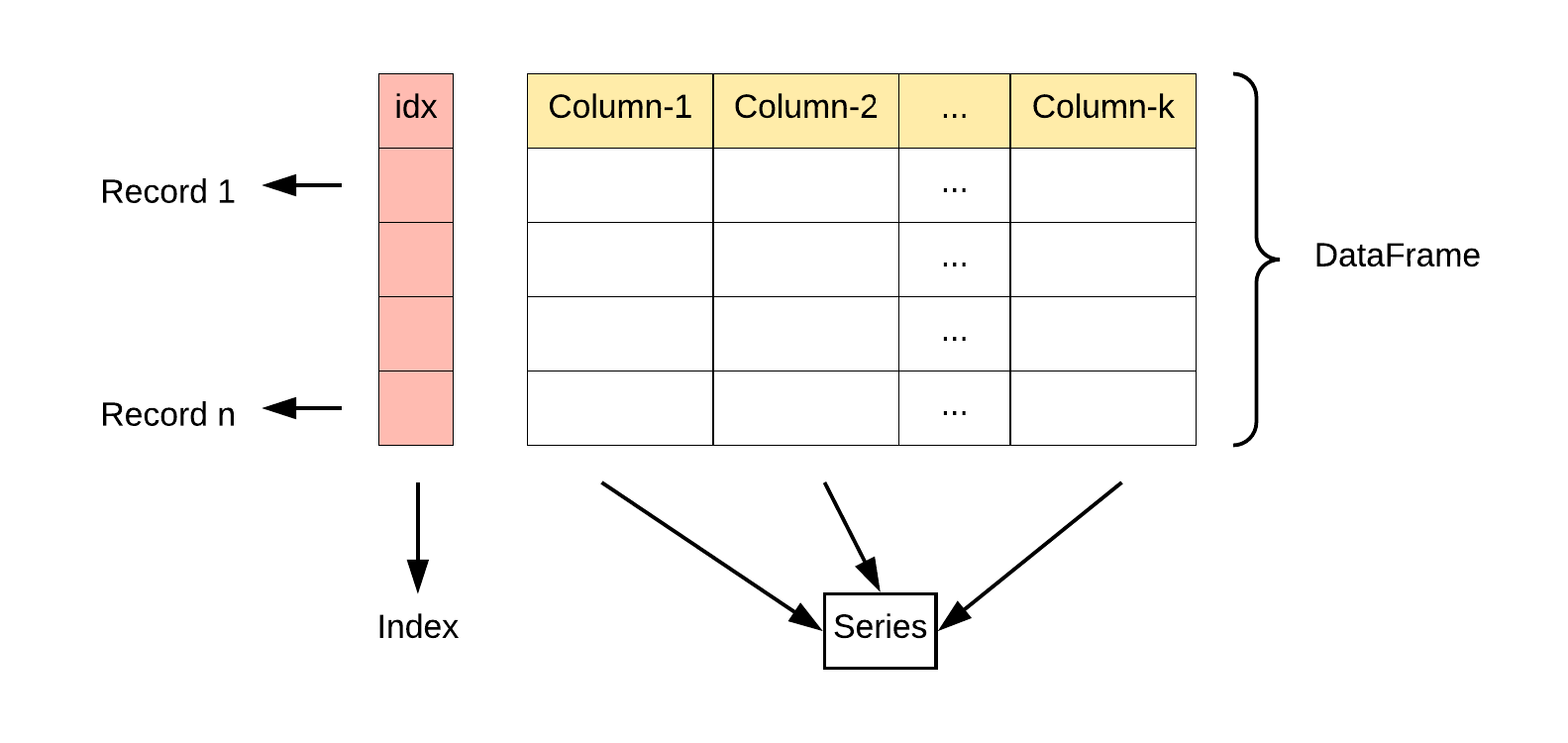
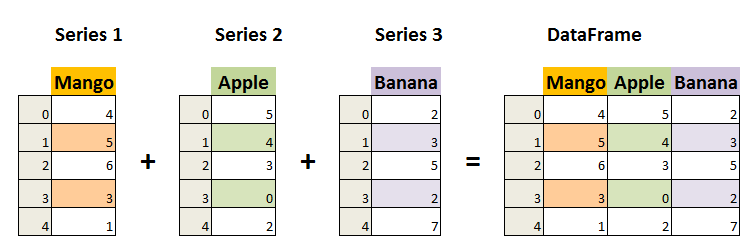
(摘自菜鸟)
构造
pandas.DataFrame( data, index, columns, dtype, copy)
-
data:一组数据(ndarray、series, map, lists, dict 等类型)。
-
index:索引值,或者可以称为行标签。
-
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
-
dtype:数据类型。
-
copy:拷贝数据,默认为 False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
(1)使用列表创建
示例
import pandas as pd
data = [['Google', 10], ['Runoob', 12], ['Wiki', 13]]
# 创建DataFrame
df = pd.DataFrame(data, columns=['Site', 'Age'])
# 使用astype方法设置每列的数据类型
df['Site'] = df['Site'].astype(str)
df['Age'] = df['Age'].astype(float)
print(df)
打印
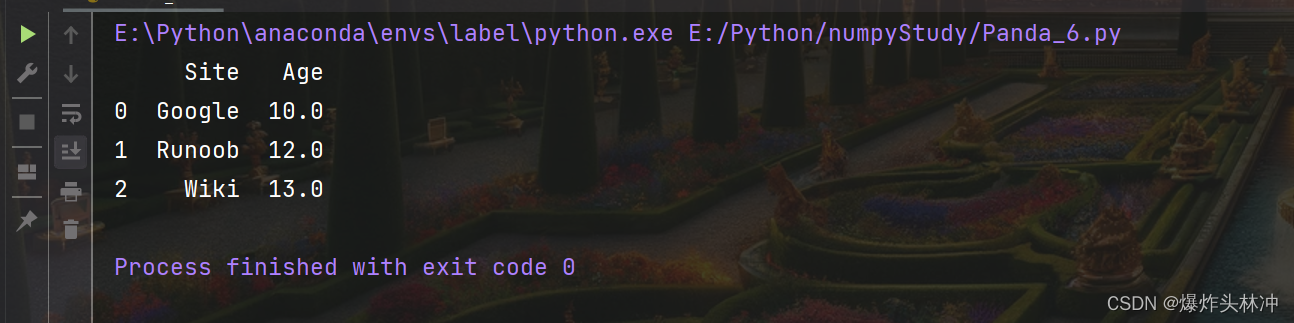
(2)使用字典创建
示例
import pandas as pd
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)
打印

使用字典(key/value),其中字典的 key 为列名:
示例
import pandas as pd
data = [{'e': 1, 'd': 2}, {'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print(df)
打印

没有对应的部分数据为 NaN。
(3)使用ndarray创建
示例
import numpy as np
import pandas as pd
# 创建一个包含网站和年龄的二维ndarray
ndarray_data = np.array([
['Google', 10],
['Runoob', 12],
['Wiki', 13]
])
# 使用DataFrame构造函数创建数据帧
df = pd.DataFrame(ndarray_data, columns=['Site', 'Age'])
# 打印数据帧
print(df)
打印

从以上输出结果可以知道, DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列):
(4)获取指定行数据
Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
示例
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])
打印
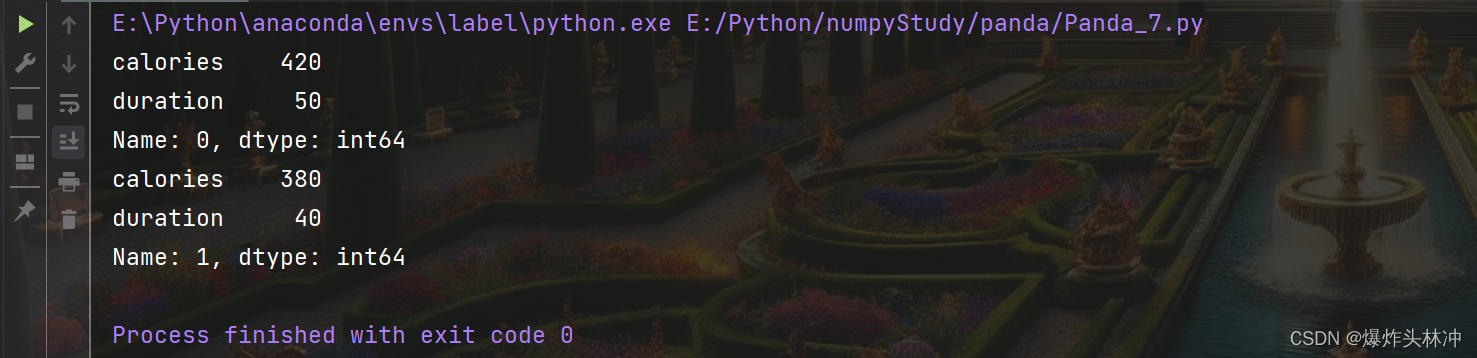
注意:返回结果其实就是一个 Pandas Series 数据。
也可以返回多行数据,使用 [[ ... ]] 格式,... 为各行的索引,以逗号隔开:
示例
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行和第二行
print(df.loc[[0, 1]])
打印
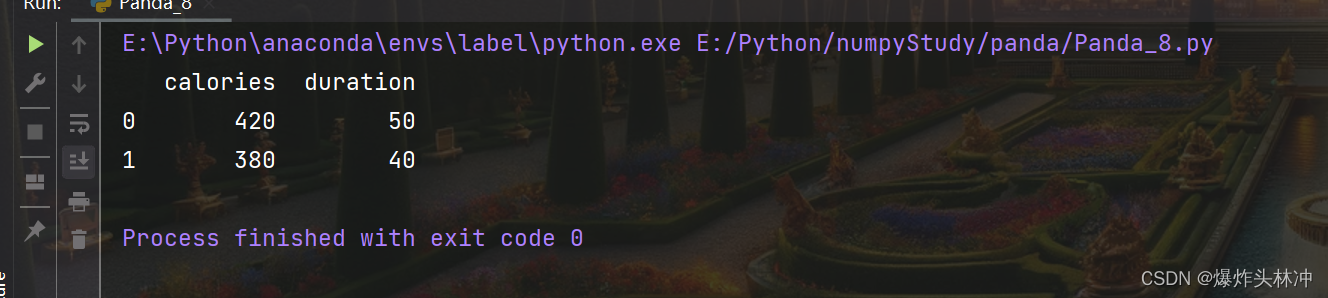
可以指定索引值
Pandas 可以使用 loc 属性返回指定索引对应到某一行:
示例
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
print(df)
print(df.loc['day1'])
打印

(5)其他基本操作
基本操作:
# 获取列
name_column = df['Name']
# 获取行
first_row = df.loc[0]
# 选择多列
subset = df[['Name', 'Age']]
# 过滤行
filtered_rows = df[df['Age'] > 30]
属性和方法:
# 获取列名
columns = df.columns
# 获取形状(行数和列数)
shape = df.shape
# 获取索引
index = df.index
# 获取描述统计信息
stats = df.describe()
数据操作:
# 添加新列
df['Salary'] = [50000, 60000, 70000]
# 删除列
df.drop('City', axis=1, inplace=True)
# 排序
df.sort_values(by='Age', ascending=False, inplace=True)
# 重命名列
df.rename(columns={'Name': 'Full Name'}, inplace=True)
从外部数据源创建 DataFrame:
# 从CSV文件创建 DataFrame
df_csv = pd.read_csv('example.csv')
# 从Excel文件创建 DataFrame
df_excel = pd.read_excel('example.xlsx')
# 从字典列表创建 DataFrame
data_list = [{'Name': 'Alice', 'Age': 25}, {'Name': 'Bob', 'Age': 30}]
df_from_list = pd.DataFrame(data_list)
注意事项:
DataFrame是一种灵活的数据结构,可以容纳不同数据类型的列。- 列名和行索引可以是字符串、整数等。
DataFrame可以通过多种方式进行数据选择、过滤、修改和分析。- 通过对
DataFrame的操作,可以进行数据清洗、转换、分析和可视化等工作。
五. CSV
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 ... 代替。
(1)打印
示例
import pandas as pd
df = pd.read_csv('nba.csv')
print(df)
print(df.to_string())
打印
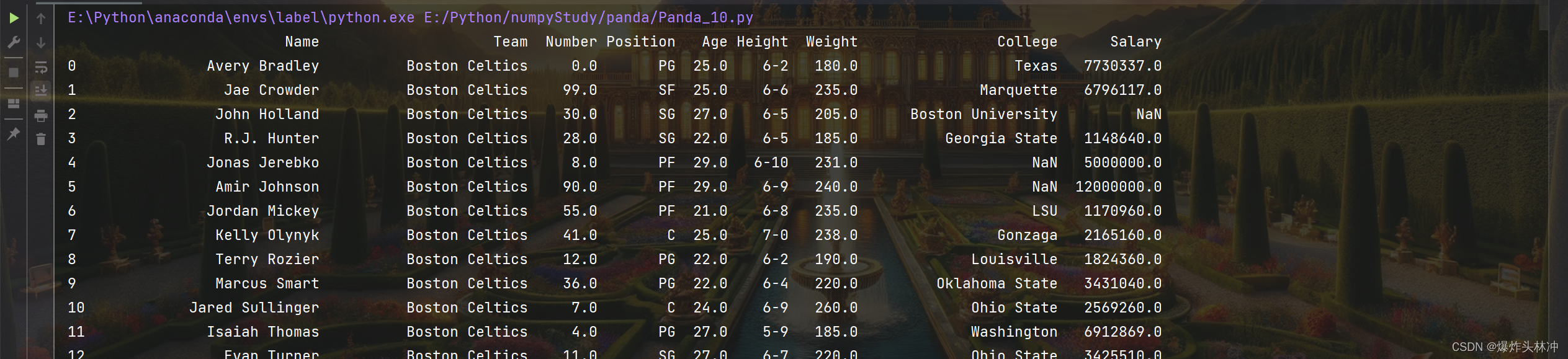

(2)存储csv文件
我们也可以使用 to_csv() 方法将 DataFrame 存储为 csv 文件:
示例
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')
打印
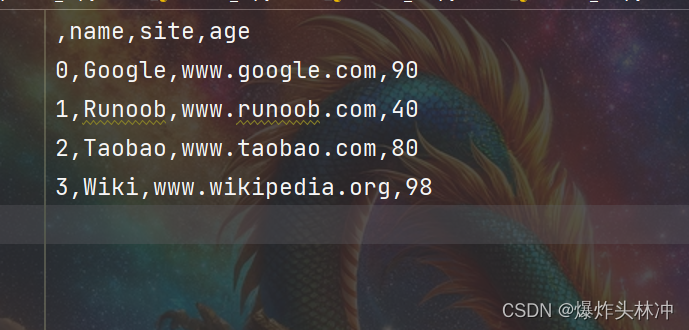
(3)数据处理
a. head()
head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head())
打印
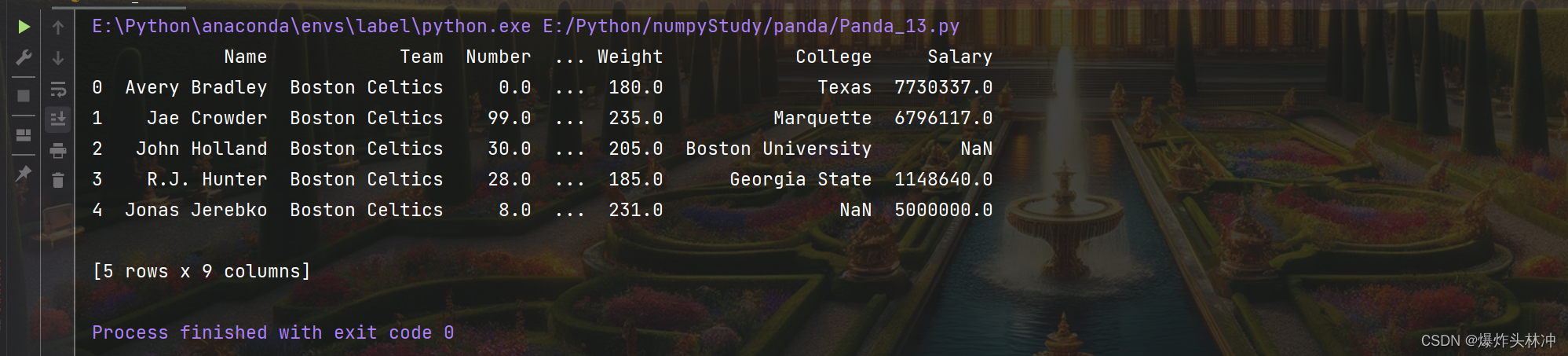
读取前面 10 行
示例
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head(10))
打印
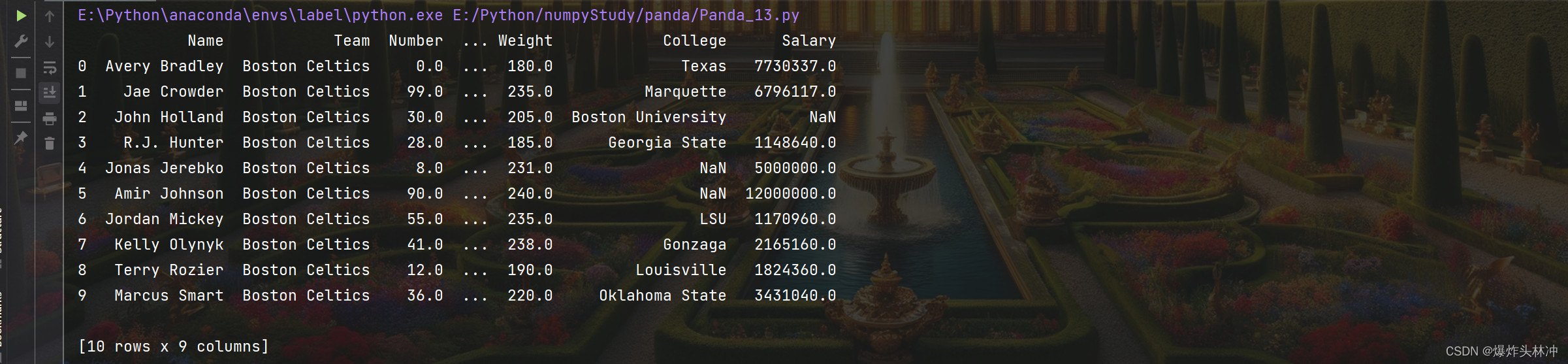
b. tail()
tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
示例
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail())
打印
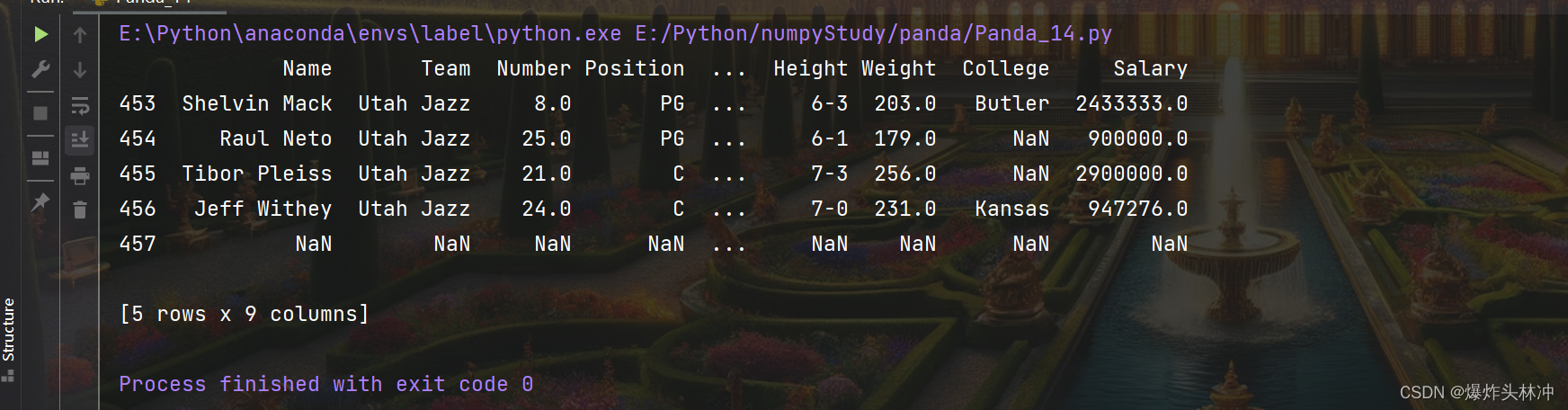
读取末尾 10 行
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail(10))
打印
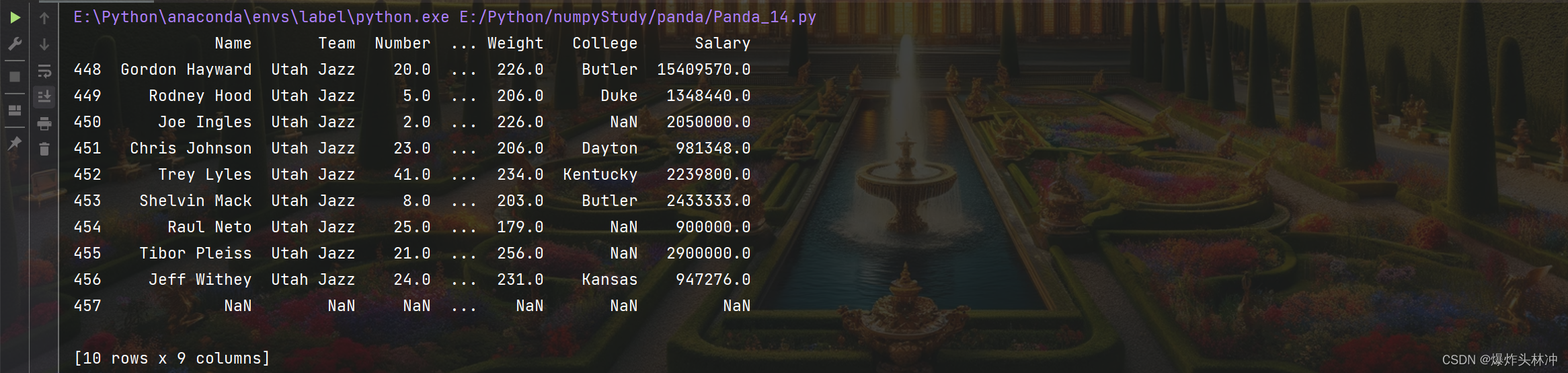
(4)info()
info() 方法返回表格的一些基本信息:
示例
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())
打印
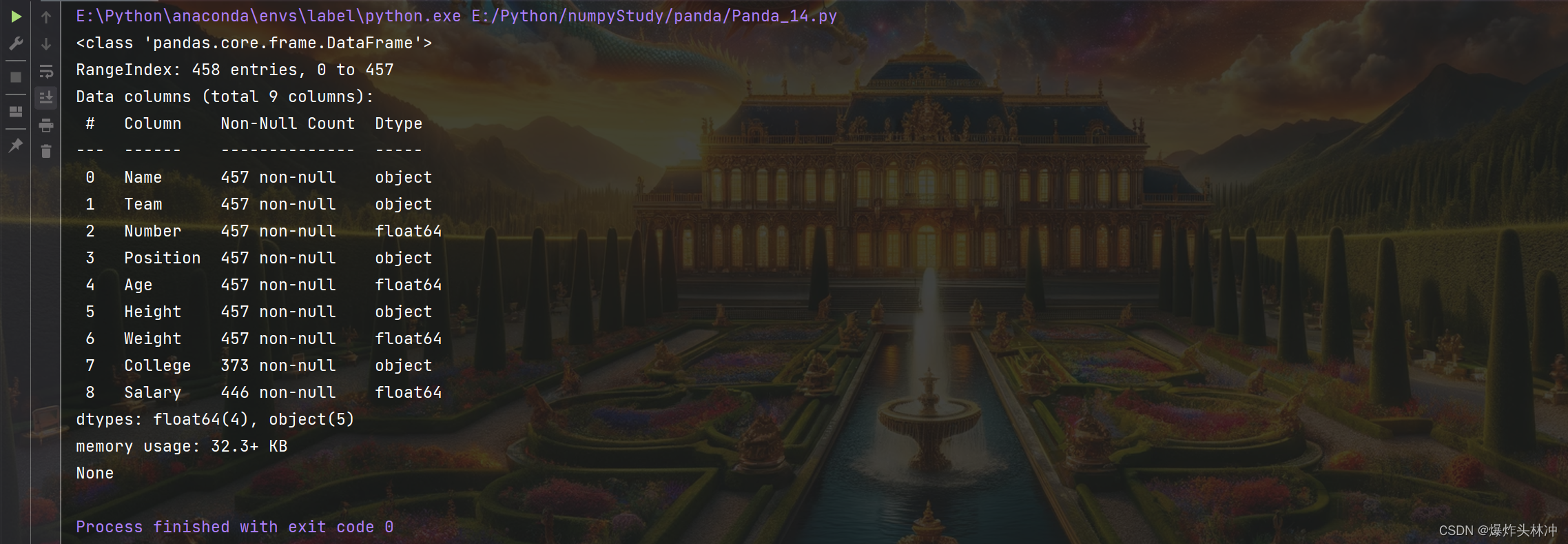
non-null 为非空数据,我们可以看到上面的信息中,总共 458 行,College 字段的空值最多。
六. JSON
JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似 XML。
JSON 比 XML 更小、更快,更易解析
1. 打印json文件
示例
import pandas as pd
df = pd.read_json('sites.json')
print(df.to_string())
打印

2. 直接打印json字符串
示例
import pandas as pd
data =[
{
"id": "A001",
"name": "菜鸟教程",
"url": "www.runoob.com",
"likes": 61
},
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
df = pd.DataFrame(data)
print(df)
打印

3. 字典转化为 DataFrame 数据
示例
import pandas as pd
# 字典格式的 JSON
s = {
"col1":{"row1":1,"row2":2,"row3":3,"row4":4},
"col2":{"row1":"x","row2":"y","row3":"z"}
}
# 读取 JSON 转为 DataFrame
df = pd.DataFrame(s)
print(df)
打印

4. URL 中读取 JSON 数据
示例
import pandas as pd
URL = 'https://static.jyshare.com/download/sites.json'
df = pd.read_json(URL)
print(df)
打印

5. 内嵌 JSON 数据
示例
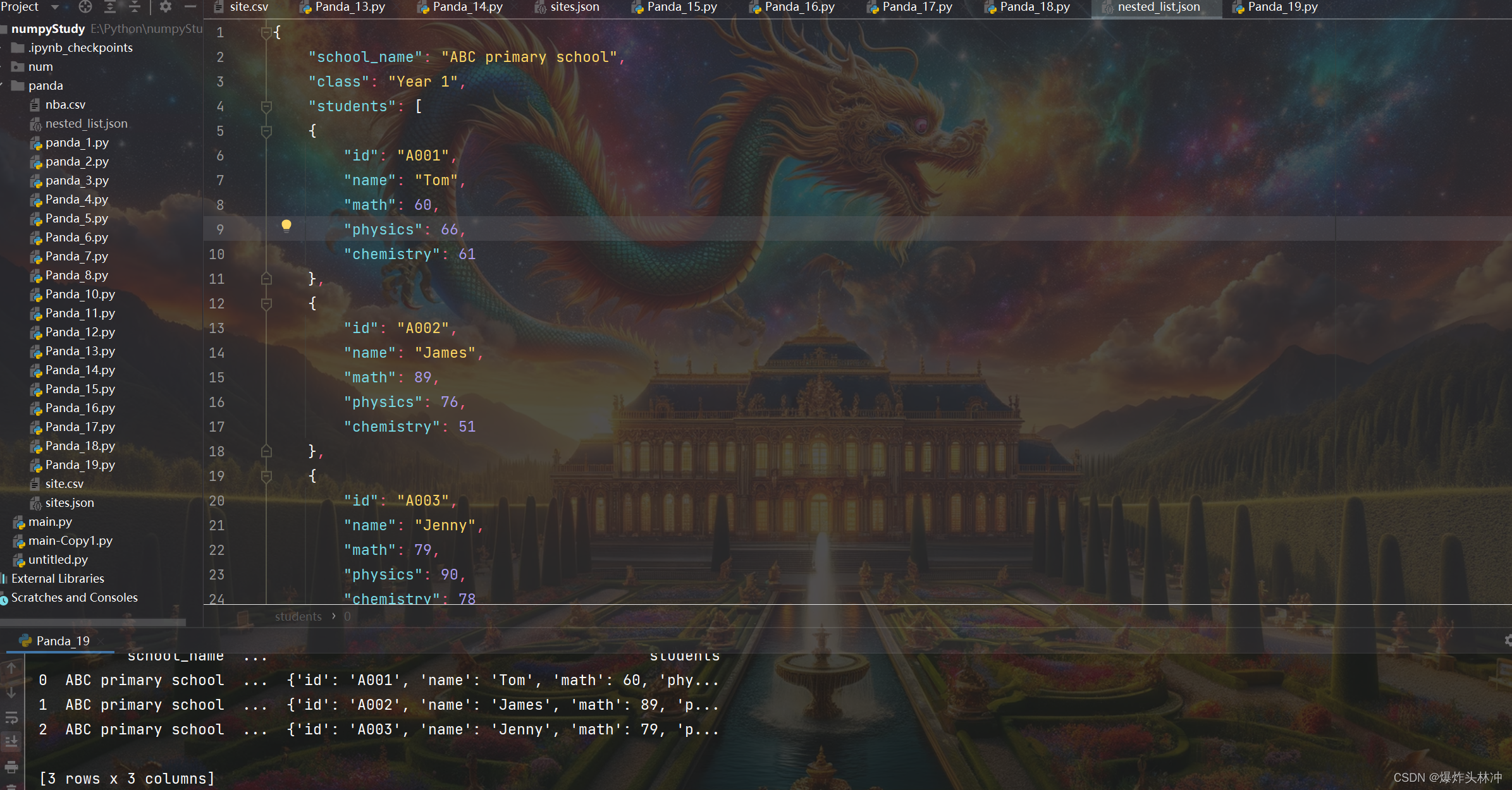
import pandas as pd
df = pd.read_json('nested_list.json')
print(df)
打印

需要使用到 json_normalize() 方法将内嵌的数据完整的解析出来
示例
import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(data, record_path =['students'])
print(df_nested_list)
打印

data = json.loads(f.read()) 使用 Python JSON 模块载入数据。
json_normalize() 使用了参数 record_path 并设置为 ['students'] 用于展开内嵌的 JSON 数据 students。
显示结果还没有包含 school_name 和 class 元素,如果需要展示出来可以使用 meta 参数来显示这些元数据:
示例
import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(
data,
record_path =['students'],
meta=['school_name', 'class']
)
print(df_nested_list)
打印

读取更复杂的 JSON 数据,该数据嵌套了列表和字典,数据文件 nested_mix.json
示例
import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_mix.json', 'r') as f:
data = json.loads(f.read())
df = pd.json_normalize(
data,
record_path=['students'],
meta=[
'class',
['info', 'president'],
['info', 'contacts', 'tel']
]
)
print(df.to_string())
打印

6.访问内嵌对象属性
安装依赖
pip3 install glom
nested_deep.json 文件内容
{
"school_name": "local primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"grade": {
"math": 60,
"physics": 66,
"chemistry": 61
}
},
{
"id": "A002",
"name": "James",
"grade": {
"math": 89,
"physics": 76,
"chemistry": 51
}
},
{
"id": "A003",
"name": "Jenny",
"grade": {
"math": 79,
"physics": 90,
"chemistry": 78
}
}]
}
示例
import pandas as pd
from glom import glom
df = pd.read_json('nested_deep.json')
data = df['students'].apply(lambda row: glom(row, 'grade.math'))
print(data)
打印



















 5558
5558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









