






引言
本教程将带领大家完成一个基于 VisDrone-DET 数据集的 YOLO11 完整项目实战,涵盖从环境搭建、模型训练、Transformer 集成到最终利用 TensorRT 加速的全流程。考虑到训练对算力的较高要求,还会介绍算力租赁的相关操作,即使是硬件配置有限的同学也能顺利完成项目。

【如果你对人工智能的学习有兴趣可以看看我的其他博客,对新手很友好!!!】
【本猿定期无偿分享学习成果,欢迎关注一起学习!!!】
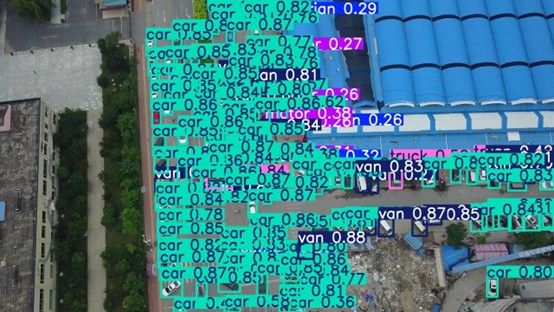
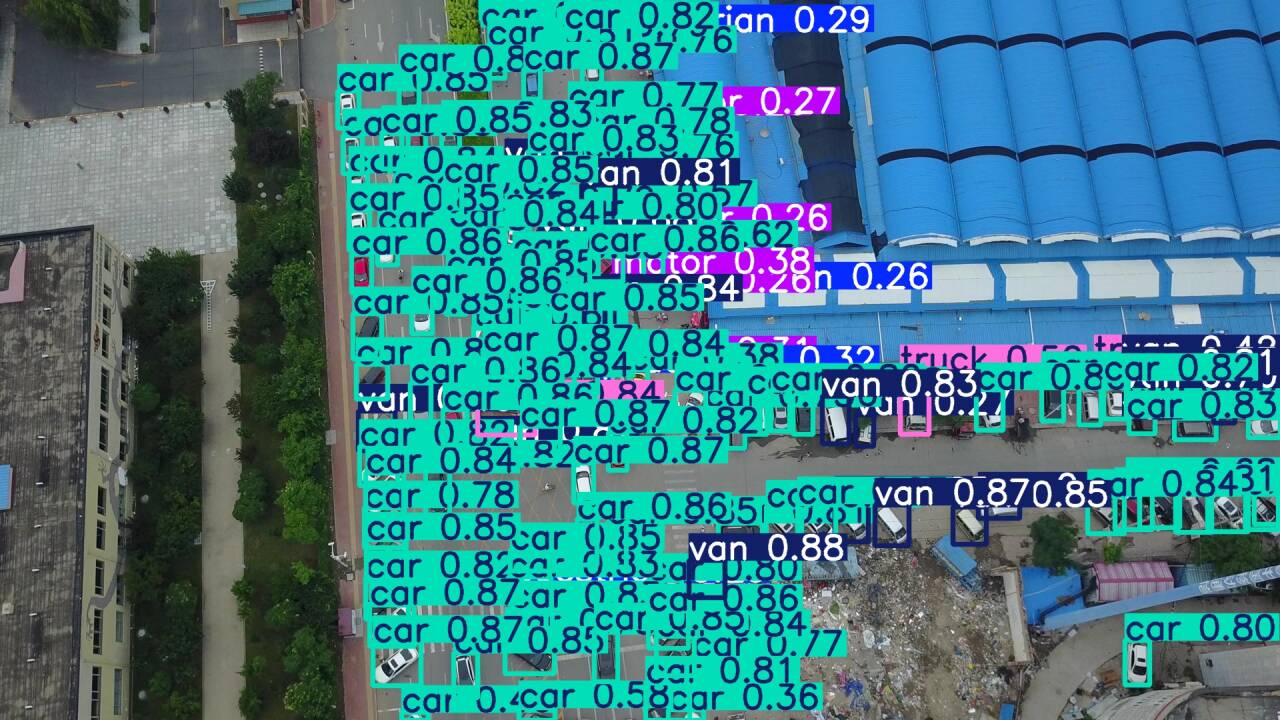
[效果展示]
(针对无人机航拍的小目标检测,检测难度很大)

一、环境搭建与部署
1.1 Conda 环境配置
在 Windows 中搜索Anaconda Prompt,以管理员身份运行
使用以下命令创建并管理 conda 环境:
查看现有环境:
conda env list创建名为yolo11的环境(指定 Python 版本为 3.12):
conda create -n yolo11 python=3.12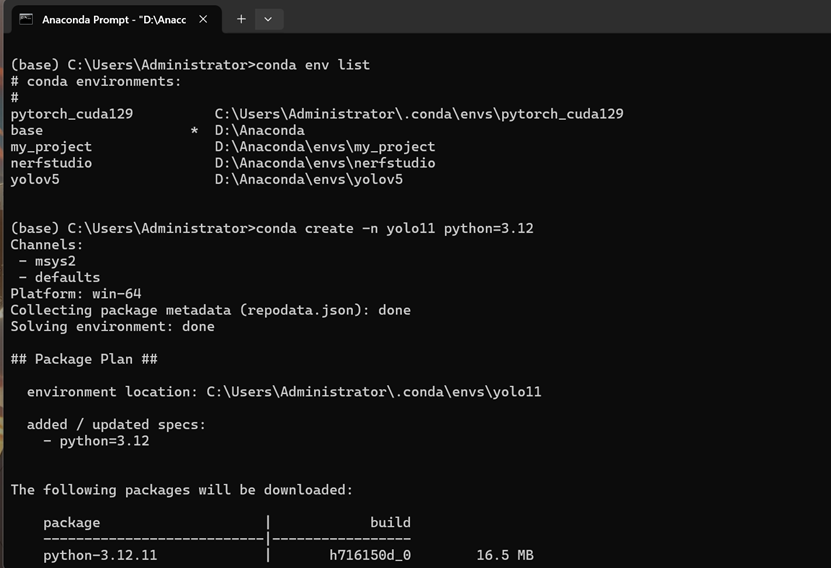
激活创建的环境:
conda activate yolo11安装基础依赖包:
安装 conda 管理的基础包:
conda install -y numpy pandas scipy pillow升级 pip 并安装相关工具:
pip install --upgrade pip
pip install setuptools wheel1.2 Ultralytics 本地部署
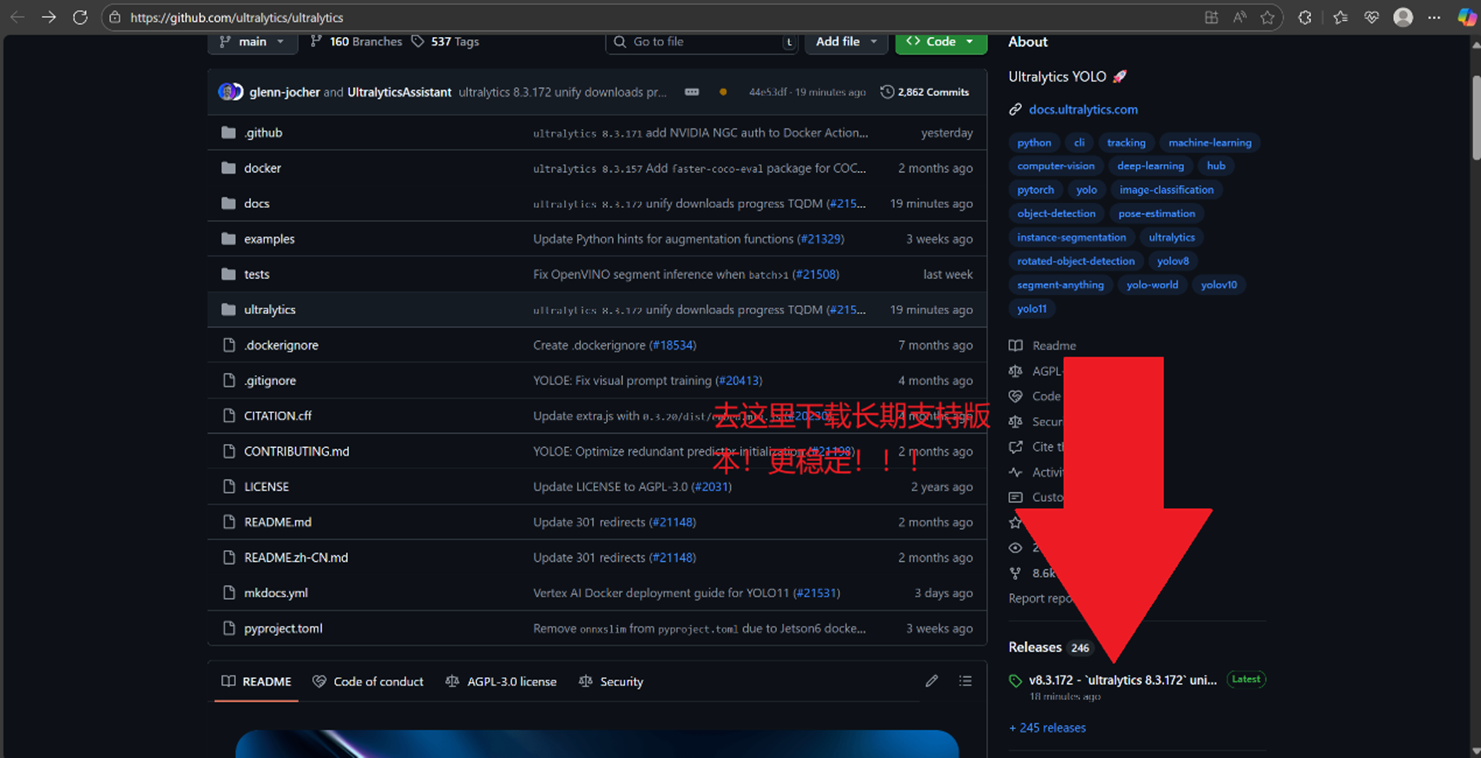
1.获取 Ultralytics 源码:
访问 GitHub 网址:ultralytics/ultralytics: Ultralytics YOLO 🚀
注意查看页面右下角的下载指引,不要直接点击 code 下载。
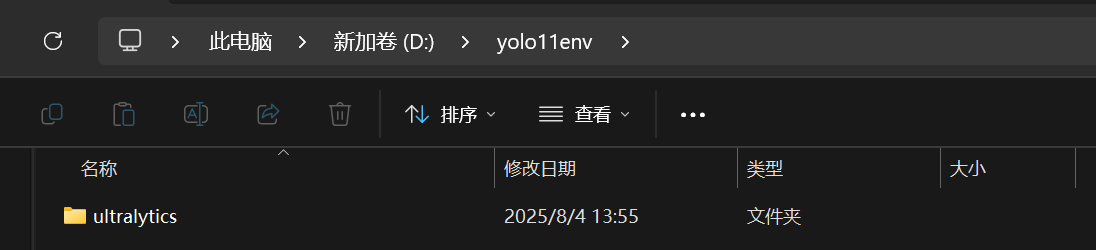
2.文件放置与路径配置:
在 D 盘创建文件夹yolo11env
将解压后的源码文件夹(名称类似ultralytics-*.*.***)放入yolo11env,并重命名为ultralytics。
记录ultralytics的绝对路径(例如:D:\yolo11env\ultralytics)
3.安装 Ultralytics:
以管理员身份运行Anaconda Prompt,激活yolo11环境。
通过cd命令进入ultralytics目录,例如:
cd D:\yolo11env\ultralytics执行可编辑模式安装:
pip install -e .
4.PyTorch 版本检测调整:
安装完成后,可通过env_test.py脚本检测,可能默认安装的是 CPU 版本的 Torch。
env_test.py脚本:
import torch
def check_torch_info():
# 打印PyTorch版本
print(f"PyTorch 版本: {torch.__version__}")
# 检查是否支持CUDA(GPU加速)
cuda_available = torch.cuda.is_available()
print(f"是否支持CUDA (GPU): {cuda_available}")
if cuda_available:
# 打印CUDA版本
print(f"CUDA 版本: {torch.version.cuda}")
# 打印可用GPU数量
print(f"可用GPU数量: {torch.cuda.device_count()}")
# 打印当前使用的GPU名称
print(f"当前GPU名称: {torch.cuda.get_device_name(0)}")
else:
print("当前使用的是CPU版本")
if __name__ == "__main__":
check_torch_info()
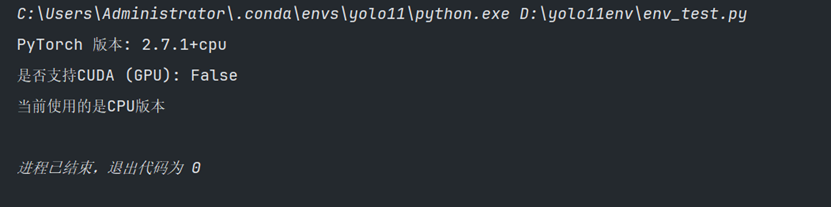
如果是CPU版本,那么需要卸载现有 Torch:
pip uninstall -y torch torchvision torchaudio接下来需要根据电脑 GPU 型号安装对应版本的 Torch,可参考往期博客:
纯干货,无废话CUDA、cuDNN、 PyTorch 环境搭建教程_创建conda环境并安装torch cuda cudnn-优快云博客
如果你也是4060显卡和12.9的cuda
那么你可以和我一样安装适配 CUDA 12.1 的版本:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121pytorch的安装很缓慢,网速不好的同学只能多等等或者去找国内的源文件
二、模型训练
2.1 数据集准备
Github链接:
自行下载之后解压打开,里面是下载链接:
原生的数据集需要进行格式转换:
转换脚本如下:
import os
from PIL import Image
from tqdm import tqdm
def convert_visdrone_labels(annotations_dir):
# 创建labels目录
labels_dir = os.path.join(annotations_dir, 'labels')
os.makedirs(labels_dir, exist_ok=True)
# 获取所有标注文件
txt_files = [f for f in os.listdir(annotations_dir) if f.endswith('.txt')]
for file in tqdm(txt_files, desc="转换VisDrone标签"):
txt_path = os.path.join(annotations_dir, file)
# 构建对应图片路径(严格匹配VisDrone目录结构)
img_dir = annotations_dir.replace('annotations', 'images')
img_path = os.path.join(img_dir, file.replace('.txt', '.jpg'))
try:
# 获取图片尺寸
with Image.open(img_path) as img:
img_width, img_height = img.size
except Exception as e:
print(f"警告: 无法读取图片 {img_path},错误: {e}")
continue
valid_lines = []
with open(txt_path, 'r') as f:
for line_idx, line in enumerate(f.readlines()):
line = line.strip()
if not line:
continue
# 分割标注数据
parts = line.split(',')
# 处理9个字段的情况(取前8个有效字段)
if len(parts) == 9:
parts = parts[:8] # 截取前8个有效字段
elif len(parts) != 8:
print(f"警告: {file} 第{line_idx + 1}行格式错误,需8个字段,实际{len(parts)}个")
continue
try:
# 解析标注字段(严格对应VisDrone格式定义)
bbox_left = int(parts[0]) # 边界框左上角x坐标
bbox_top = int(parts[1]) # 边界框左上角y坐标
bbox_width = int(parts[2]) # 边界框宽度
bbox_height = int(parts[3]) # 边界框高度
score = parts[4] # 目标置信度分数
category = int(parts[5]) # 目标类别(1-10)
# 1. 过滤被忽略的区域(score=0)- 参考博客核心规则
if score == '0':
continue
# 2. 过滤无效类别(仅保留1-10的有效类别)
if not (1 <= category <= 10):
print(f"警告: {file} 第{line_idx + 1}行存在无效类别 {category}(有效范围1-10)")
continue
# 3. 计算YOLO格式坐标(严格按照博客公式)
x_center = (bbox_left + bbox_width / 2) / img_width # 中心x归一化
y_center = (bbox_top + bbox_height / 2) / img_height # 中心y归一化
width = bbox_width / img_width # 宽度归一化
height = bbox_height / img_height # 高度归一化
# 4. 坐标边界校验(确保在[0,1]范围内)
x_center = max(0.0, min(1.0, x_center))
y_center = max(0.0, min(1.0, y_center))
width = max(0.0, min(1.0, width))
height = max(0.0, min(1.0, height))
# 5. 类别ID转换(1-10 → 0-9,匹配YOLO格式)
cls_id = category - 1
valid_lines.append(f"{cls_id} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}\n")
except ValueError:
print(f"警告: {file} 第{line_idx + 1}行存在非数值数据 - {line}")
continue
# 保存转换后的标签
label_path = os.path.join(labels_dir, file)
with open(label_path, 'w') as f:
f.writelines(valid_lines)
# 处理空标签文件(便于后续数据校验)
if not valid_lines:
print(f"注意: {file} 转换后无有效标签(可能全为忽略区域)")
# 执行转换(指定标注文件目录)
annotations_directory = r'D:\yolo11\data\val\annotations'
convert_visdrone_labels(annotations_directory)
print(f"转换完成!标签保存至: {os.path.join(annotations_directory, 'labels')}")2.2 项目文件结构
在 PyTorch 中打开yolo11目录,添加 conda 环境作为解释器
然后我会带着你创建以下关键文件 / 文件夹:
data:我们要训练的数据集
ultralytics:yolo文件
coco.yaml:数据集配置文件
yolo11m.yaml: 模型配置文件
main.py:执行训练的python文件
2.3 配置文件设置
1.coco.yaml配置:
该文件需明确训练集、验证集、测试集路径,类别数量、名称及评估指标等
可参考ultralytics/ultralytics/cfg/datasets/coco.yaml官方文件进行修改
# 数据集根路径(VisDrone 数据集位置)
path: ./data
# 训练集/验证集路径(images/labels 需与 VisDrone 目录对应)
train: train/images # 训练集图片路径(labels 自动关联同级目录)
val: val/images # 验证集图片路径
# 类别配置(修正后的10个类别,移除了others)
nc: 10
names:
0: pedestrian
1: people
2: bicycle
3: car
4: van
5: truck
6: tricycle
7: awning-tricycle
8: bus
9: motor
2.yolo11m.yaml配置:
定义模型网络结构、训练超参数等。
参考ultralytics/ultralytics/cfg/models/11/yolo11.yaml官方文件,根据数据集类别数修改nc等参数。
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO11 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo11
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 10 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 181 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 181 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 231 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 357 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 357 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.4 训练启动脚本
1.命令行启动训练
例如:
yolo task=detect mode=train model=yolo11m.yaml data=path/to/your/coco.yaml epochs=100 batch=16-
task=detect:表示目标检测任务。 -
mode=train:表明进入训练模式。 -
model=yolo11m.yaml:指定模型结构配置文件。 -
data=path/to/your/coco.yaml:指向数据集配置文件。 -
epochs=100:设置训练总轮数。 -
batch=16:设置每个批次的样本数量(根据硬件调整)。
2.main.py脚本启动
这是博主的脚本,需要使用的话可以自行修改
脚本如下:
import sys
import os
import torch
if __name__ == '__main__':
project_root = os.path.abspath(os.path.join(os.path.dirname(__file__), "ultralytics"))
sys.path.insert(0, project_root)
from ultralytics import YOLO
model = YOLO("./yolo11m.yaml")
training_args = {
"data": "./coco.yaml",
"epochs": 100,
"imgsz": 800,
# 1. 降低batch size避免显存波动导致nan(原24→16,保持算力利用率)
"batch": 16,
# 2. 使用预训练权重辅助收敛(原False→True,解决从头训练难收敛问题)
"pretrained": True,
# 3. 降低数据增强强度(解决标签模糊导致的nan)
"augment": True,
"mosaic": 1.0,
"mixup": 0.1, # 原0.3→0.1,减少过度混合
"hsv_h": 0.01, # 原0.02→0.01,降低色彩扰动
"hsv_s": 0.6, # 原0.75→0.6
"hsv_v": 0.4, # 原0.45→0.4
"fliplr": 0.5,
# 4. 优化学习率和精度设置(解决nan和收敛慢)
"half": False, # 原True→False,先关闭FP16避免数值不稳定(后续可再尝试)
"lr0": 0.01, # 原0.02→0.01,降低学习率避免梯度爆炸
"lrf": 0.01,
"cos_lr": True,
"optimizer": "AdamW",
# 5. 延长早期停止耐心(原30→40,避免过早停止)
"project": "runs/detect",
"name": "train_4090_optimized_fixed",
"plots": True,
"verbose": True,
"patience": 40, # 允许更多epoch观察改进
}
model.train(** training_args)
# 6. 验证时优化NMS参数(解决NMS时间超限警告)
model.val(
data="./coco.yaml",
imgsz=800,
batch=16,
plots=True,
save_json=True,
iou=0.6 # 降低NMS的IOU阈值,减少计算量
)3.训练测试
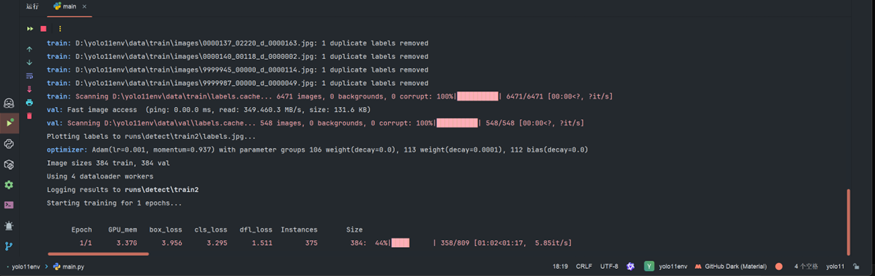
接下来就可以启动main.py进行训练测试,可先跑少量轮次验证环境是否正常。
如图博主跑了一轮
三、Transformers 集成
安装 Transformers
以管理员身份运行Anaconda Prompt,激活yolo11环境:
conda activate yolo11使用清华源安装指定版本:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple transformers==4.50.0四、MobileViT集成
在项目根目录下创建view.py来下载 MobileViT 模型并查看网络各模块结构
【注意需要科学上网才能下的动】
view.py如下:
import os
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
from transformers import MobileViTModel, MobileViTConfig
if __name__ == '__main__':
# 加载 MobileViT 模型,指定预训练模型名称和缓存目录
model = MobileViTModel.from_pretrained(
"apple/mobilevit-small",
cache_dir="./cache",
)
print('MobileViT网络结构: ')
print('=' * 50)
# 打印预处理层
print('预处理层: ')
print('=' * 50)
print(model.conv_stem)
# 打印特征提取层 - 1
print('特征提取层-1: ')
print('=' * 50)
print(model.encoder.layer[0])
# 打印特征提取层 - 2(根据注释,总共有多层可按需扩展,这里先示例到 layer[1] )
print('特征提取层-2: ')
print('=' * 50)
print(model.encoder.layer[1])
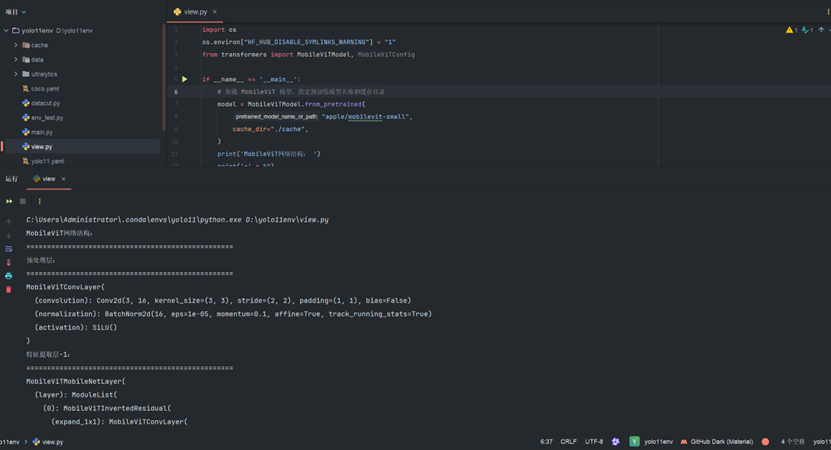
print('=' * 50)如下,可以看到其网络结构
五、ultralytics的本地模型修改
在D:\yolo11env\ultralytics\ultralytics\nn\modules目录下创建:
5.1 mobilevitbackbone.py的创建
代码:
import torch
import torch.nn as nn
from transformers import MobileViTModel # 导入预训练MobileViT模型
class MobileViT_Backbone(nn.Module):
def __init__(self):
super(MobileViT_Backbone, self).__init__()
model = MobileViTModel.from_pretrained(
"apple/mobilevit-small",
cache_dir=r"D:\yolo11env\cache",
)
# 定义自己的网络层
self.conv_stem = model.conv_stem
# layer里面的层
self.layer_0 = model.encoder.layer[0]
self.layer_1 = model.encoder.layer[1]
self.layer_2 = model.encoder.layer[2]
self.layer_3 = model.encoder.layer[3]
self.layer_4 = model.encoder.layer[4]
def forward(self, x):
x = self.conv_stem(x)
x = self.layer_0(x)
x = self.layer_1(x)
layer_2 = self.layer_2(x)
layer_3 = self.layer_3(layer_2)
layer_4 = self.layer_4(layer_3)
return [layer_2, layer_3, layer_4]
if __name__ == "__main__":
model = MobileViT_Backbone()
# 输入数据
x = torch.randn(1, 3, 640, 640)
out = model(x)
print(out[0].shape, out[1].shape, out[2].shape)5.2 SelectLayer.py的创建
代码:
import torch.nn as nn
class SelectLayer(nn.Module):
def __init__(self, ind):
super().__init__()
self.ind = ind
self.act = nn.SiLU(inplace=True) # 添加Swish激活函数
def forward(self, x):
# 先选择特征,再应用激活函数
return self.act(x[self.ind])
5.3 备份并修改yolo11.yaml
新 yolo11.yaml如下:
# 模型配置参数
nc: 10 # 类别数量:10个类别
# 不同规模模型的参数配置 (宽度因子, 深度因子, 输入尺寸)
scales:
n: [0.50, 0.25, 1024] # nano模型: 宽度50%, 深度25%, 输入尺寸1024
s: [0.50, 0.50, 1024] # small模型: 宽度50%, 深度50%, 输入尺寸1024
m: [0.50, 1.00, 800] # medium模型: 宽度50%, 深度100%, 输入尺寸800
# 1. 调整m模型的输入尺寸与训练一致(原512→800)
l: [1.00, 1.00, 512] # large模型: 宽度100%, 深度100%, 输入尺寸512
x: [1.00, 1.50, 512] # xlarge模型: 宽度100%, 深度150%, 输入尺寸512
# 骨干网络配置 (每一行代表一个网络层)
# 格式: [来自哪一层, 重复次数, 模块名称, 模块参数]
backbone:
- [-1, 1, MobileViT_Backbone, []] # 0-P1/2: 基础MobileViT骨干网络,输出步长为2
# 小目标特征提取 (P3/8)
- [0, 1, SelectLayer, [0,96]] # 1-P3/8: 从骨干网络第0层选择96通道的特征图,输出步长8
- [-1, 2, C3k2, [768, False, 0.25]]# 2: 2层C3k2模块,输出通道768,不使用残差,缩放因子0.25
# 2. 增加小目标特征层的通道数(原512→768,增强表达能力)
# 中目标特征提取 (P4/16)
- [0, 1, SelectLayer, [1,128]] # 3-P4/16: 从骨干网络第1层选择128通道的特征图,输出步长16
- [-1, 2, C3k2, [768, True]] # 4: 2层C3k2模块,输出通道768,使用残差(原512→768)
# 大目标特征提取 (P5/32)
- [0, 1, SelectLayer, [2,160]] # 5-P5/32: 从骨干网络第2层选择160通道的特征图,输出步长32
- [-1, 2, C3k2, [1024, True]] # 6: 2层C3k2模块,输出通道1024,使用残差
# 特征增强
- [-1, 1, CBAM, [7]] # 7: CBAM注意力机制,作用于第7层特征
- [-1, 1, SPPF, [1024, 5]] # 8: SPPF模块,输出通道1024,卷积核大小5(对应原配置第9层)
- [-1, 2, C2PSA, [1024]] # 9: 2层C2PSA模块,输出通道1024(对应原配置第11层)
# 检测头配置
head:
# 上采样融合P5和P4特征
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 10: 最近邻上采样2倍(对应原配置第12层)
- [[-1, 4], 1, Concat, [1]] # 11: 拼接第10层和第4层特征(通道维度)(对应原配置第13层)
- [-1, 2, C3k2, [768, False]] # 12: 2层C3k2模块,输出通道768,不使用残差(原512→768)(对应原配置第15层)
# 上采样融合到P3特征
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 13: 最近邻上采样2倍(对应原配置第16层)
- [[-1, 2], 1, Concat, [1]] # 14: 拼接第13层和第2层特征(通道维度)(对应原配置第17层)
- [-1, 2, C3k2, [512, False]] # 15: 2层C3k2模块,输出通道512,不使用残差(原256→512)(对应原配置第19层)(P3/8-small)
# 下采样融合到P4特征
- [-1, 1, Conv, [512, 3, 2]] # 16: 3x3卷积,步长2,输出通道512(对应原配置第20层)
- [[-1, 12], 1, Concat, [1]] # 17: 拼接第16层和第12层特征(通道维度)(对应原配置第21层)
- [-1, 2, C3k2, [768, False]] # 18: 2层C3k2模块,输出通道768,不使用残差(原512→768)(对应原配置第23层)(P4/16-medium)
# 下采样融合到P5特征
- [-1, 1, Conv, [768, 3, 2]] # 19: 3x3卷积,步长2,输出通道768(原512→768)(对应原配置第24层)
- [[-1, 9], 1, Concat, [1]] # 20: 拼接第19层和第9层特征(通道维度)(对应原配置第25层)
- [-1, 2, C3k2, [1024, True]] # 21: 2层C3k2模块,输出通道1024,使用残差(对应原配置第27层)(P5/32-large)
# 检测输出层
- [[15, 18, 21], 1, Detect, [nc]] # 从第15、18、21层获取特征,通过Detect模块输出,检测10个类别
# Detect(P3, P4, P5) 分别对应小、中、大目标检测5.4 修改__init__.py
在D:\yolo11env\ultralytics\ultralytics\nn\modules\__init__.py:
在 104 行和 109 行插入相应内容:
使用#NEW进行了注解 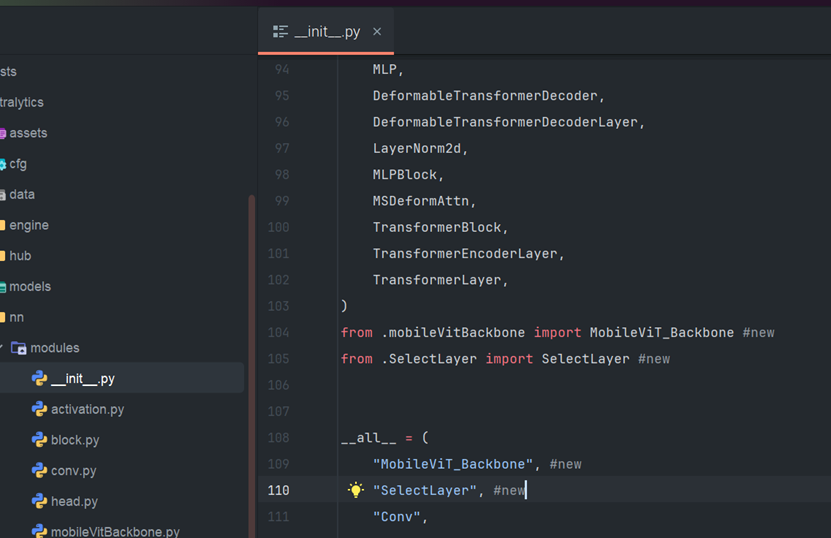
5.5 task.py的修改
然后来到同目录的task.py进行插入:
第一处#NEW进行了注解:
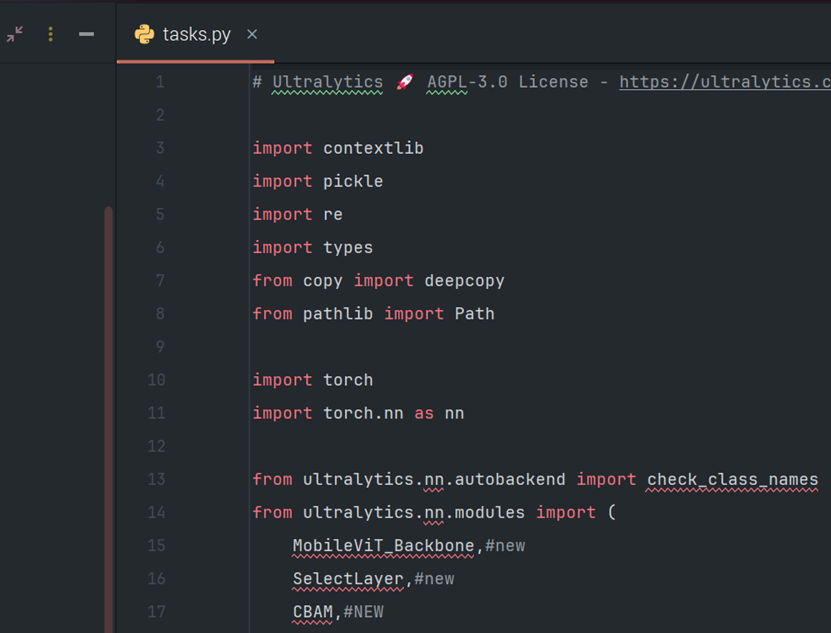
第二处用#NEW进行了注解:
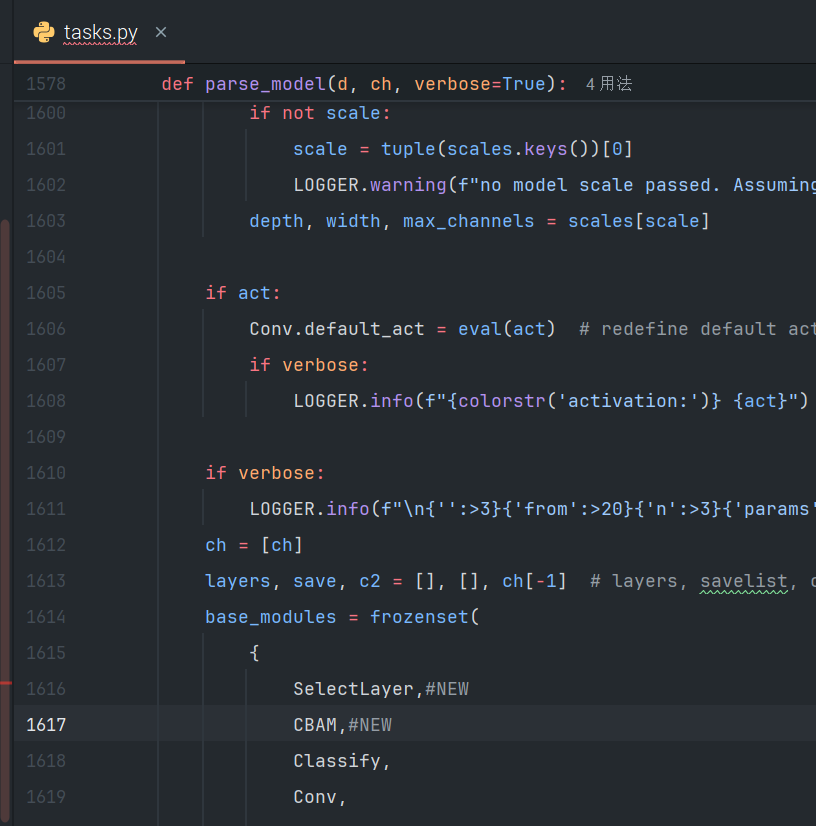
第三处,用#进行了包裹:
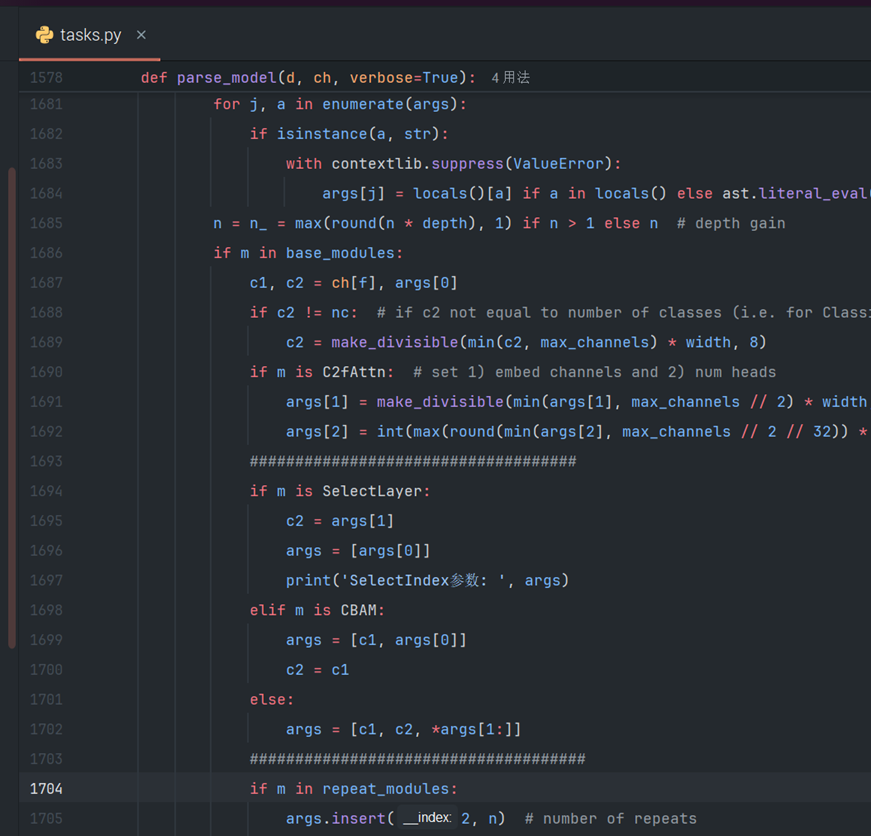
至此,本地模型调整完成!
六、算力租赁
因为我们的训练对算力要求较高,所以推荐使用算力租赁,博主的4060也跑不动
(事先说好博主不是打广告的)
册账号并登录,然后充10块钱就勉强够用了。
6.1 打包上传
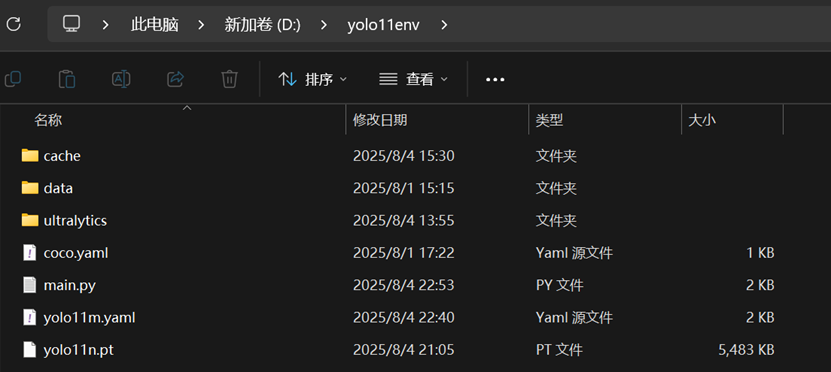
下面是我们需要打包上传的文件
其中yolo11n.pt是自动下载的
压缩为zip

然后来到工作空间
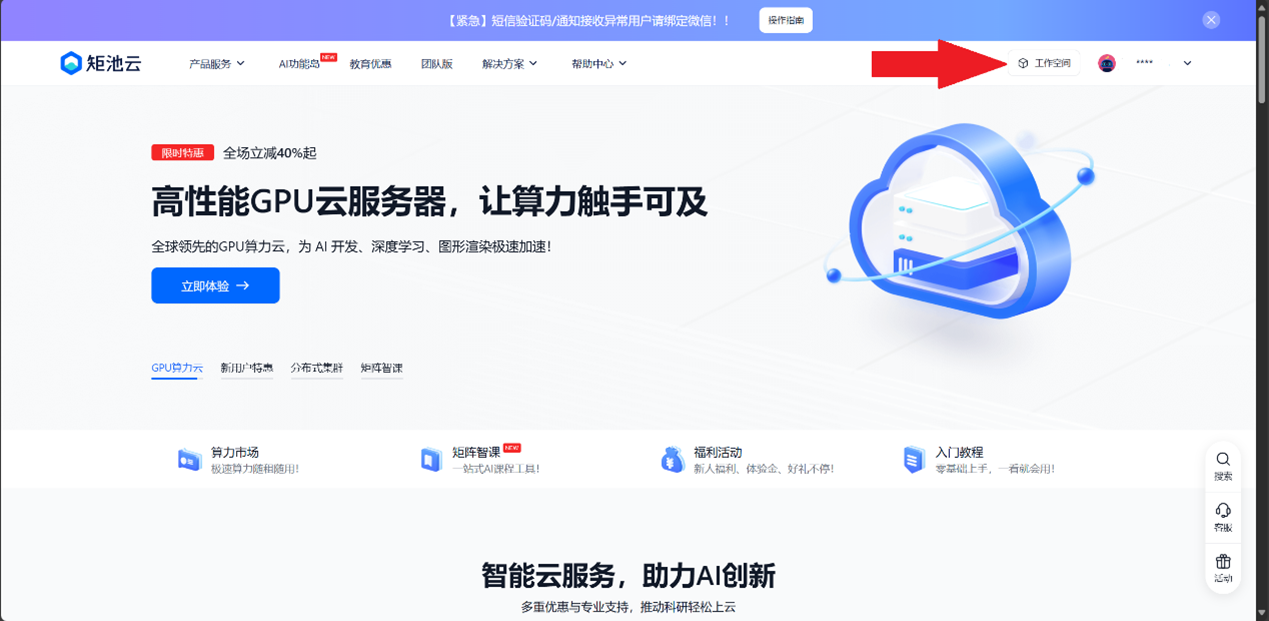
选择我的网盘(左下角)
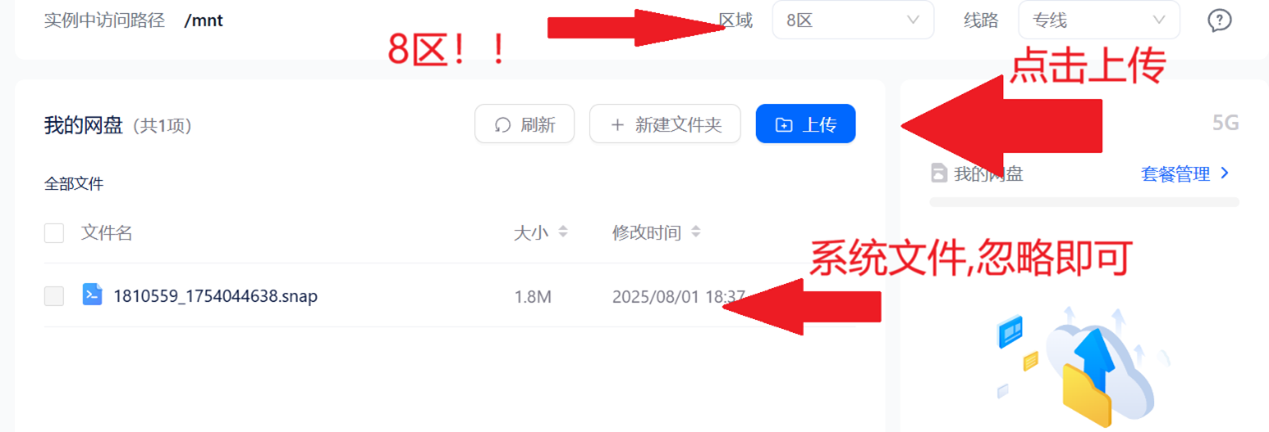
等待上传即可
6.2 VNC的装载
VNC是用来远程链接服务器的,方便我们操作
官网地址放下面了,同学请自行下载
RealVNC® - Remote access software for desktop and mobile | RealVNC
下载完成后打开完成VNC账号的注册和登录。
6.3 服务器的租赁
产品服务-->GPU云服务器
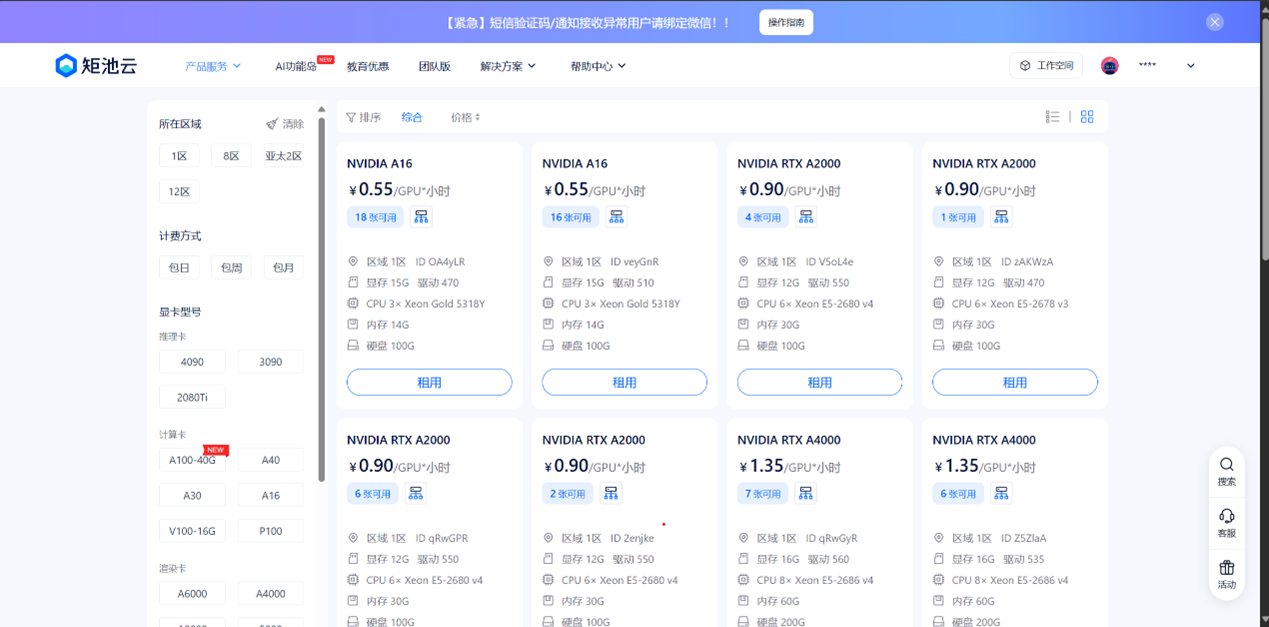
选择8区-->4090
按时-->pytorch2.6.0-->开启VNC
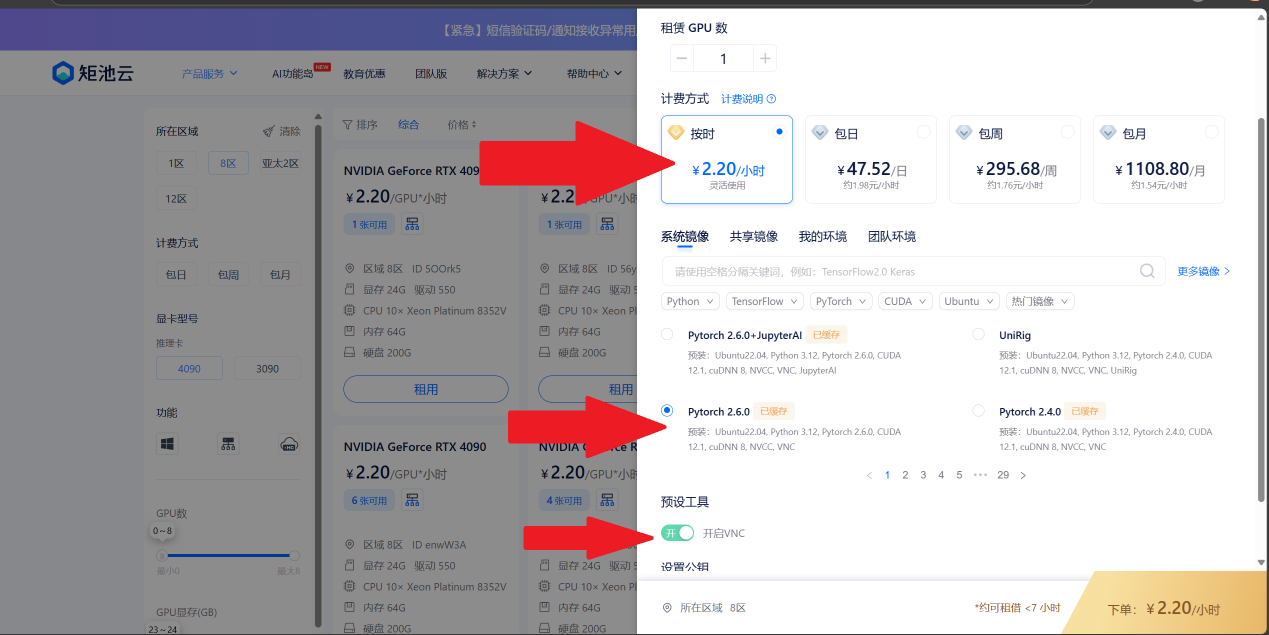
下单!
6.4使用VNC链接服务器
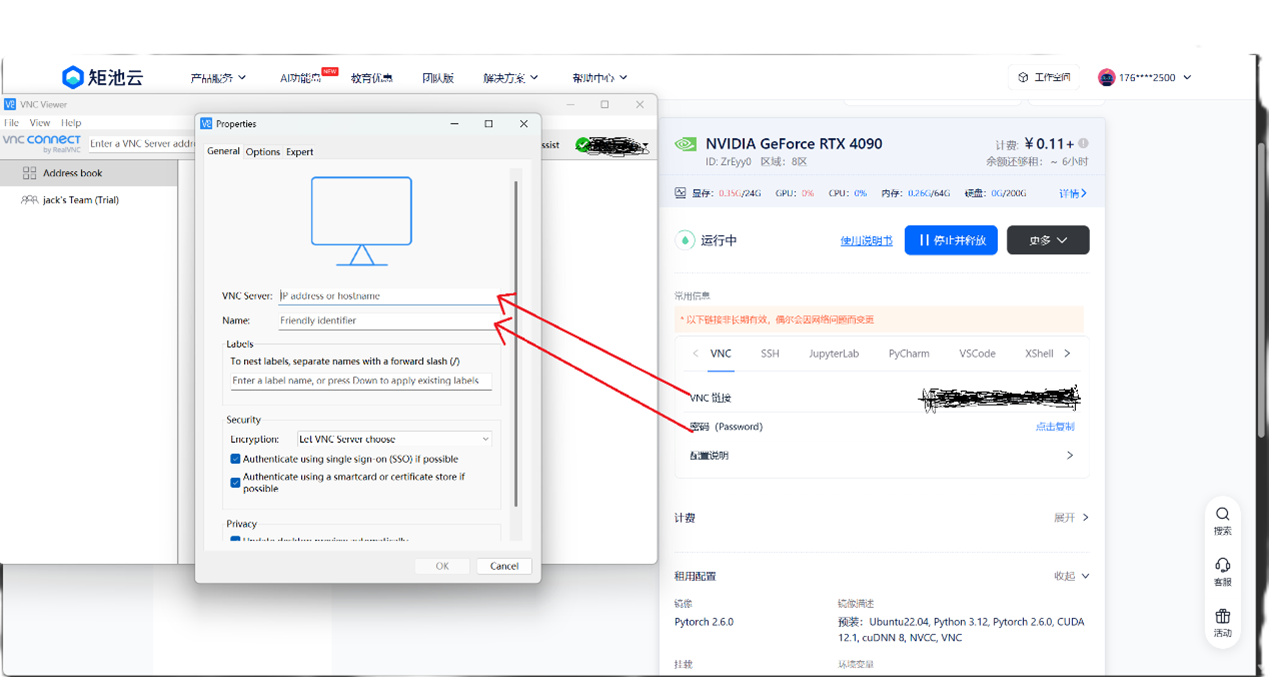
在VNC中fileàNew connection
输入VNC链接和密码进行链接
再次输入密码
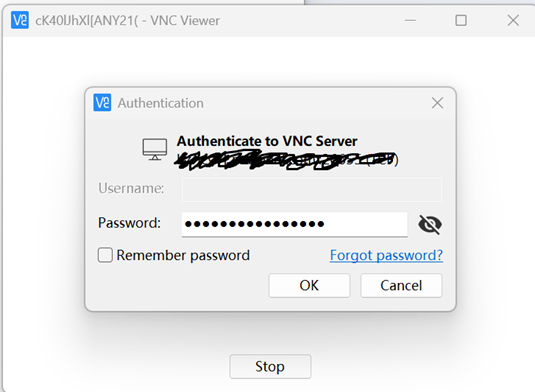
打开终端
进入云盘目录
cd mnt查看云盘文件
ls
然后使用
unzip yolo11env.zip来解压
解压完成了使用
Clear清理屏幕
现在就可以看到我们的工作目录了

使用
cd yolo11env进入工作目录

再使用
cd ultralytics来到ultralytics目录下对ultralytics进行服务器的安装
使用pip install -e.进行ultralytics的本地部署
下面是使用清华源安装,国内地址更快!
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple等待安装完成
然后
cd ..回到上一级目录

执行pip install transformers来安装transformers
同样使用清华源:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple transformers等待安装完成即可!
6.5 开始训练!
回到 工作目录yolo11env

使用
chmod +x main.py让脚本可执行
因为训练时间长达几个小时,所以说这是一场持久战,而正常训练的话我们又不能断开服务器的链接,所以我们使用后台运行,让训练脚本自动在后台跑,这样哪怕我们关闭了VNC也不会停止!
后台运行命令:
nohup python main.py > train_log.txt 2>&1 &
然后使用
tail -f train_log.txt来实时查看日志
如果有问题就中断训练
pkill -f "python main.py"七、TensorRT推理加速
7.1 TensorRT装载
下面是英伟达官方的下载地址,请根据自己cuda版本和显卡版本选择下载
TensorRT 10.x Download | NVIDIA Developer
下载完成后解压到D盘
例如我的地址:D:\tensorTR\TensorRT-10.10.0.31
然后把D:\tensorTR\TensorRT-10.10.0.31\lib配置到环境变量
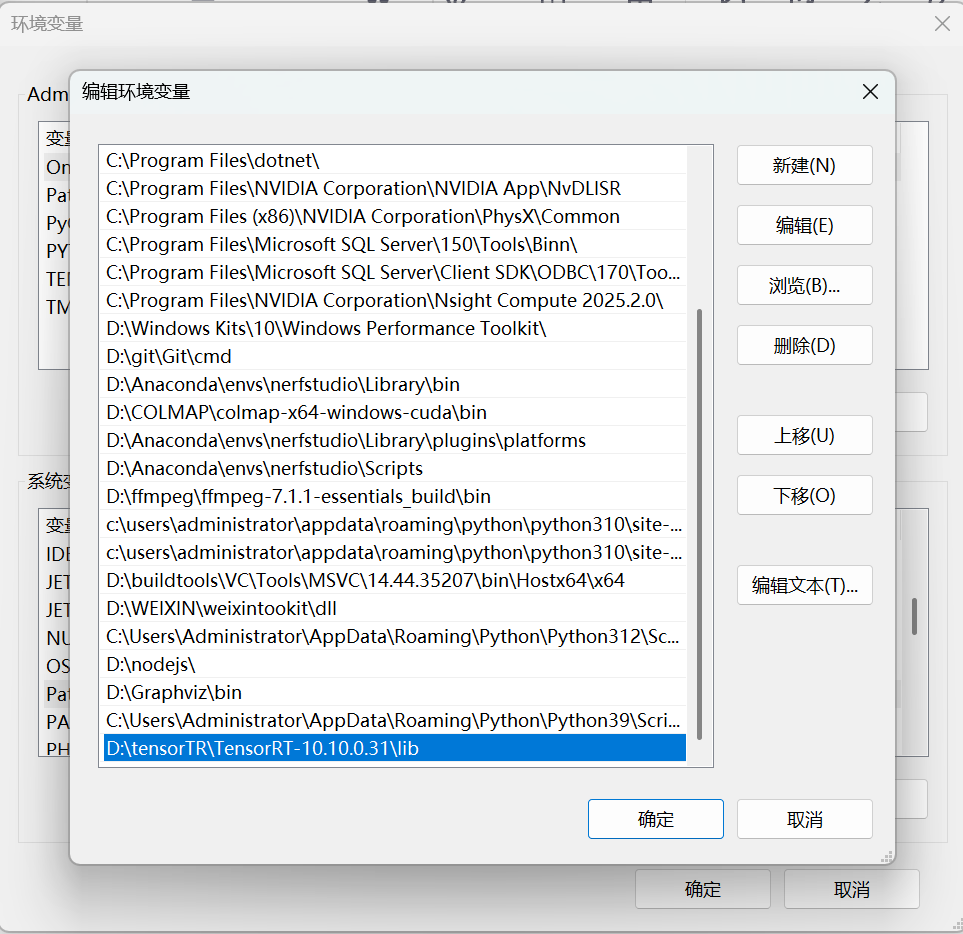
依旧是激活我们需要进行推理的conda环境然后来到D:\tensorTR\TensorRT-10.10.0.31\python目录下
pip install tensorrt_lean-10.10.0.31-cp312-none-win_amd64.whl #取决于python版本
然后继续安装依赖
pip install onnx onnxruntime-gpu onnx-graphsurgeon pycuda onnxslim大功告成!
7.2 engine的预测推理
推理完成后我们在云盘目录的runs目录下找到best.pt导出到本地,
然后使用以下脚本把pt转化engine
from ultralytics import YOLO
import logging
# 配置日志(可选,用于记录导出过程)
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[logging.FileHandler("export_engine.log"), logging.StreamHandler()]
)
def export_pt_to_engine(
model_path: str,
imgsz: tuple = (640, 640),
dynamic: bool = False,
batch: int = 1,
half: bool = True,
save_dir: str = "./"
) -> None:
"""
将 YOLO 模型从 .pt 导出为 TensorRT Engine (.engine)
参数:
model_path: .pt 模型路径(如 "best.pt")
imgsz: 输入尺寸 (height, width),默认 (640, 640)
dynamic: 是否启用动态维度(支持动态 batch 或输入尺寸)
batch: 批次大小(动态模式下为最大 batch)
half: 是否启用 FP16 精度(加速推理,需 GPU 支持)
save_dir: 导出文件保存目录
"""
try:
# 加载模型
model = YOLO(model_path)
logging.info(f"成功加载模型: {model_path}")
# 导出配置
export_args = {
"format": "engine",
"imgsz": imgsz,
"dynamic": dynamic,
"batch": batch,
"half": half,
"save_dir": save_dir
}
# 执行导出
logging.info(f"开始导出 Engine,配置: {export_args}")
results = model.export(**export_args)
# 导出成功提示
if results:
logging.info(f"Engine 导出成功!保存路径: {results}")
else:
logging.warning("导出未返回结果,可能存在隐藏错误")
except Exception as e:
logging.error(f"导出失败: {str(e)}", exc_info=True)
raise # 如需忽略错误可注释此行
# 示例:导出自己的 best.pt
if __name__ == "__main__":
export_pt_to_engine(
model_path="best.pt", # 替换为你的模型路径
imgsz=(640, 640), # 输入尺寸
dynamic=True, # 启用动态 batch(1~batch 范围)
batch=16, # 最大 batch 尺寸
half=True, # 启用 FP16 加速
save_dir="./engine_output" # 保存目录
)然后创建以下目录
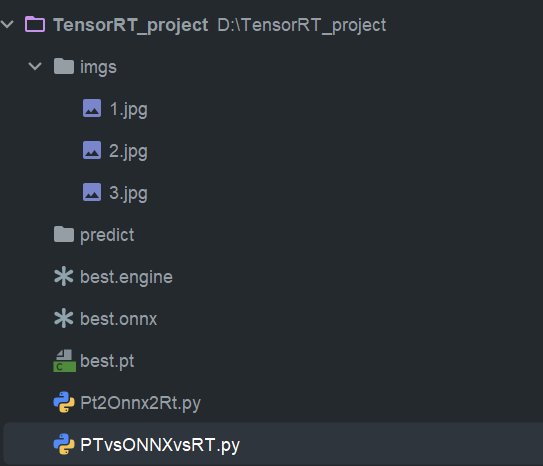
在imgs里放入三张测试图片
接下来使用这个脚本进行预测
import os
import time
from ultralytics import YOLO
# 定义路径
IMG_DIR = os.path.join(os.path.dirname(os.path.abspath(__file__)), "imgs/")
RESULT_DIR = os.path.join(os.path.dirname(os.path.abspath(__file__)), "predict/")
# 创建结果目录
os.makedirs(RESULT_DIR, exist_ok=True)
# 图片列表
image_paths = [
os.path.join(IMG_DIR, "1.jpg"),
os.path.join(IMG_DIR, "2.jpg"),
os.path.join(IMG_DIR, "3.jpg")
]
# 检查图片是否存在
for img in image_paths:
if not os.path.exists(img):
print(f"警告: 图片不存在 - {img}")
# 加载TensorRT模型
model = YOLO("best.engine", task="detect")
# 预热模型
model(image_paths[0:1], imgsz=640, device=0, verbose=False)
# 执行推理并计时
start_time = time.time()
results = model(image_paths, imgsz=640, device=0, verbose=False)
infer_time = time.time() - start_time
# 保存结果
for i, result in enumerate(results):
result.save(os.path.join(RESULT_DIR, f"result_{i}_{int(time.time())}.jpg"))
result.save_crop(os.path.join(RESULT_DIR, "crops/"))
# 输出信息
print(f"推理完成,耗时: {infer_time:.4f}秒")
print(f"结果保存至: {RESULT_DIR}")
预测效果展示:

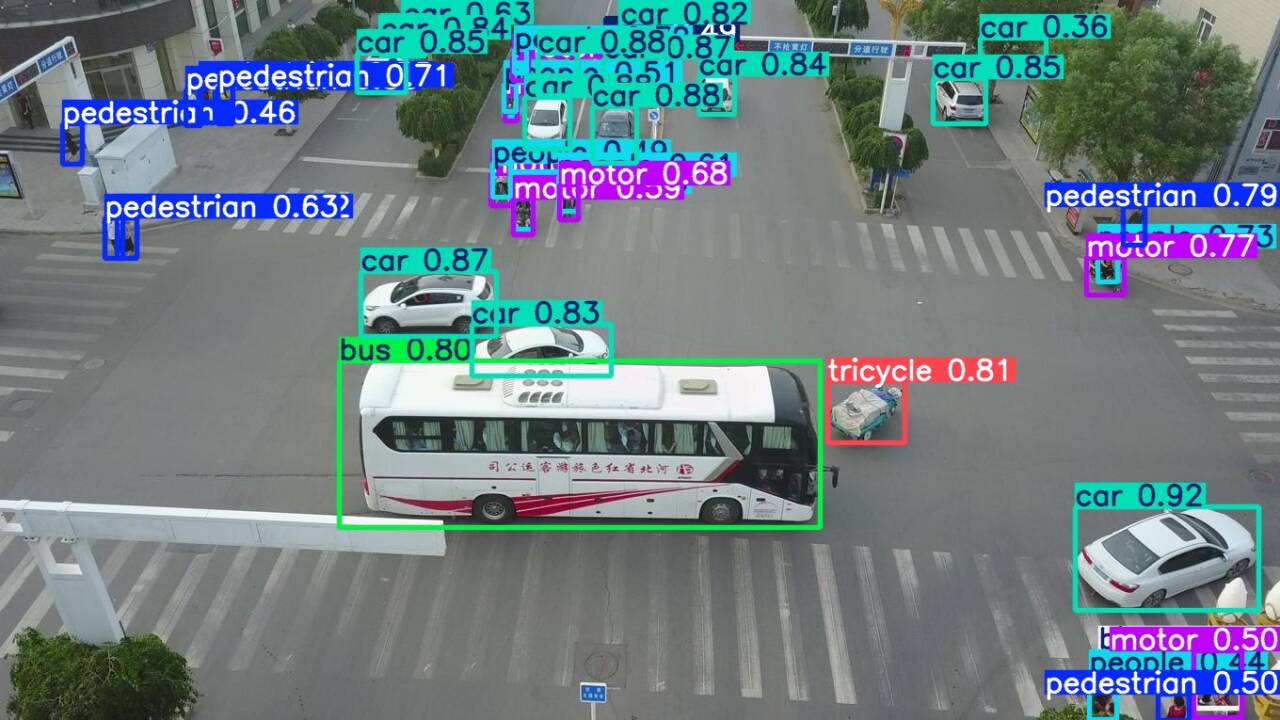





















 1919
1919


 到【灌水乐园】发言
到【灌水乐园】发言








