




 本文详细介绍了Python pandas库在数据处理中的常用方法,包括读取CSV文件、设置列索引、行索引、数据统计、DataFrame操作等。通过实例展示了如何读取文件、查看数据、切片、统计分析以及数据清洗,帮助读者快速掌握pandas的使用技巧。
本文详细介绍了Python pandas库在数据处理中的常用方法,包括读取CSV文件、设置列索引、行索引、数据统计、DataFrame操作等。通过实例展示了如何读取文件、查看数据、切片、统计分析以及数据清洗,帮助读者快速掌握pandas的使用技巧。
Python pandas学习总结
pandas是做数据分析非常重要的一个模块,它使得数据分析的工作变得更快更简单。由于现实世界中数据源的格式非常多,但是pandas也支持了不同数据格式的导入方法,所以学习pandas非常有必要。
要是想看所有的方法详解可以去官网,要想学习Pandas建议先看下面2个网站。
官网地址如下:https://pandas.pydata.org/
官网教程如下(十分钟搞定pandas):https://pandas.pydata.org/pandas-docs/stable/10min.html
两种特殊数值:NAN (数值数据类型的一类数),全称Not a Number ,表示未定义或者不可表示的值,inf表示无穷,可能无穷大也可能无穷小。
常用方法
| 常用方法 | 程序 | 备注 |
|---|---|---|
| 创建pandas数据 | df=pd.DataFrame({“列1”:[1,2,3],“列2”:[4,5,6]}) | #DataFrame类 |
| 读取excel数据到python中 | pd.read_excel(“路径”,header=n,index_col=“列1”,skiprows=3,usecols=“C:F”,dtype={“old”:str,“name”:str},sheet_name=‘sheet2’) | #read_excel方法,header默认为0,即将第0行作为索引列,如果需要设置第n行为索引列,则headers=n,若读取的数据中只有数据,没有有列索引,则需要添加header=None来表示,同时可以通过df.columns=[“name”,“old”,“sexuality”]来为数据新增列索引,index_col表示在导入数据的时候就指定行索引,siprows=3表示跳过前3行,从第4行开始读取,usecols="C:F"表示使用C:F列数据,一般用于数据前几行前几列为空白,dtype为设置某列的数据类型,sheet_name表示读取excel中的某个sheet页 |
| 创建excel并将数据输出到excel中 | df.to_excel(“路径”) | #to_excel方法 |
| 设置excel的行索引并更新(替换原本数据) | df=df.set_index(“列1”) | #列1为想要设置的行索引,set_index方法 |
| 返回数据的行和列 | print(df.shape) | #主要为shape属性 |
| 返回数据的列名,即属性 | print(df.columns) df.columns=[“name”,“old”,“sexuality”] | #主要为colums属性,df.columns=[“name”,“old”,“sexuality”]来为数据新增列索引 |
| 返回数据的前几行 | print(df.head(n)) | #head()默认返回前5行,若返回n行则head(n) |
| 返回数据的后几行 | print(df.tail()) | #tail()默认返回前5行,若返回n行则tail(n) |
Series
| 常用方法 | 程序 | 备注 |
|---|---|---|
| 创建Series | 1、d={‘x’:100,‘y’:200,‘z’:300} pd.Series(d) 2、 L1=[100,200,300] L2=[‘x’,‘y’,‘z’ ]pd.Series(L1,index=L2) 3、 pd.Series([100,200,300],index=[‘x’,‘y’,‘z’]) | 3种方法创建Series,方法1是通过字典形式,index表示标签 |
| 创建含有行标签和列标签的Series | s1=pd.Series([1,2,3],index=[1,2,3],name=‘A’) s2=pd.Series([10,20,30],index=[1,2,3],name=‘B’) s3=pd.Series([100,200,300],index=[1,2,3],name=‘C’) | 创建Series时name表示这些数据的列标签,index表示行标签 |
| 将几个Series合并为DataFrame (正确做法) | pd.DataFrame(s1.name:s1,s2.name:s2,s3.name:s3) | 此方法将Series中的S1,S2,S3合并,并将原来的行标签作为行标签,将单个Series作为一列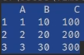 |
| 将几个Series合并为DataFrame(错误方法) | pd.DataFrame([s1,s2,s3]) | 此方法虽然也能合并,但是标签错误,将单个Series作为一行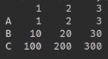 |
| 设置特定位置的值 | df[“name” ].at[0]=1 或者df.at[0,“name”] =1 | 令name列的第0个元素的值为1,at中只能为数字 |
| 对数据的某一列应用函数 | df.[“old”]=df.[“old”].apply(fx)或者用lambda函数代替fx函数,即df.[“old”]=df.[“old”].apply(lambda x:x+2) | 通过使用apply()方法来应用函数,fx为函数名,不加括号 |
| 排序 | df.sort_values(by=[‘old’,‘name’],inplace=True,ascending=[True,False]) | 排序使用sort_values函数,by为排序依据,先按old,后按name,inplace表示在原数据上修改,ascending表示升序降序,默认为True,即升序,False为降序,该式子表示old升序,name降序,即先对old升序排,再对name降序排 |
| 查看到符合条件的特定数值 | df.loc[df[‘old’].apply(fx)] 或者df.loc[df.old.apply(fx)]或者用lambda函数代替fx,即 df.loc[df[‘old’].apply(lambds x:x+2)] | loc用来定位特定位置,后边为方括号[],df[‘old’].apply(fx)表示对df数据的old列使用fx函数进行筛选,然后通过loc返回筛选后的值,函数fx不用加括号 |
| 显示所有列 | pd.options.display.max_columns=888 pd.set_option(‘display.max_columns’, None)#显示所有列 pd.set_option(‘display.max_rows’, None)#显示所有行 pd.set_option(‘max_colwidth’,100) #设置value的显示长度为100,默认为50 | 可能由于列数太多无法显示所有列,因此通过设置max_columns来展示888(大于所有列)列 |
| 显示各个变量之间的相关系数表 | print(df.corr()) | 显示各个变量之间的相关系数,和stata几乎一样 |
| 数据合并1(EXCEL中的VLOOKUP功能 ) | table=df.merge(df1,how=‘left’,on=‘ID’).fillna(0) | 根据相同的’ID列’对df和df1进行合并,on表示根据哪一列进行合并(如果两个表对应的数名称不一样,不都是ID,那么可以将on替换为left_on和right_on,由于默认情况下,当df1中ID为nan时不进行合并,只取交集,因此通过how='left’,无论右边df1中ID列是否为nan,都按df列返回,即以左边df中的ID为基础进行合并,fillna(0)表示将所有的nan替换为0 |
| 数据合并2 | pd.contact([sheet1,sheet2],axis=1) .reset_index(drop=True) | 同样数据纵向合并,但是是通过pandas而不是df,sheet1,sheet2表示需要合并的数据所在的sheet页,rest_index表示重新设置行标签,否则默认将sheet1,sheet2原本的标签直接照搬,axis=0表示竖着合并,axis=1表示横着合并 |
| 追加列 | df[“age”]=np.arrange(len(studets)) | 追加age列,数字一次为0,1,2递增数列 |
| 改变数据类型 | df.old= df.old.astype(int) | 将df表中的old列转换为int格式 |
| 去除重复数据 | df.drop_duplicates(subset=[‘name’,‘old’],inplace=True,keep=‘first’) | subset表示在那列上去除重复值,inplace表示是否在原数据上进行替换,keep表示当有重复时保留前边的重复值还是后边的 |
| 返回某个数据的位置 | a = df[(df.BoolCol3)&(df.attr22)].index.tolist() | 返回df数据中Boolcol为3,attr为22的标签 |
| 删除原标签,重新设置为0,1,2 | data.index=[i for i in range(data.shape[0])] | – |
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – | ||
| – |
一:读取文件,read_csv方法
- 1准备CSV文件
Train_A_001.csv文件内容如下:
0.916,4.37,-1.372,0.102,0.041,0.069,0.018
0.892,3.955,-1.277,0.015,-0.099,-0.066,0.018
0.908,3.334,-1.193,0.033,-0.098,-0.059,0.018
1.013,3.022,-1.082,0.151,0.015,0.035,0.018
1.111,2.97,-1.103,-0.048,-0.175,-0.171,0.019
1.302,3.043,-1.089,0.011,-0.085,-0.097,0.018
1.552,3.017,-1.052,0.066,-0.002,-0.036,0.019
1.832,2.796,-0.933,0.002,-0.028,-0.075,0.019
2.127,2.521,-0.749,0.011,0.041,-0.022,0.019
2.354,2.311,-0.623,-0.038,0.012,-0.056,0.019
2.537,2.024,-0.452,0.039,0.089,0.031,0.019
2.639,1.669,-0.277,-0.005,0.036,-0.008,0.019
2.707,1.314,-0.214,0.013,0.031,-0.005,0.019
2.81,0.926,-0.142,0.062,0.046,0.031,0.019
- 2直接读取文件内容
import pandas as pd
filename = r'Train_A/Train_A_001.csv'
data = pd.read_csv(filename)
print(data)
read_csv读取的数据类型为Dataframe,通过obj.dtypes可以查看每列的数据类型结果如下;
0.916 4.37 -1.372 0.102 0.041 0.069 0.018
0 0.892 3.955 -1.277 0.015 -0.099 -0.066 0.018
1 0.908 3.334 -1.193 0.033 -0.098 -0.059 0.018
2 1.013 3.022 -1.082 0.151 0.015 0.035 0.018
3 1.111 2.970 -1.103 -0.048 -0.175 -0.171 0.019
4 1.302 3.043 -1.089 0.011 -0.085 -0.097 0.018
5 1.552 3.017 -1.052 0.066 -0.002 -0.036 0.019
6 1.832 2.796 -0.933 0.002 -0.028 -0.075 0.019
7 2.127 2.521 -0.749 0.011 0.041 -0.022 0.019
8 2.354 2.311 -0.623 -0.038 0.012 -0.056 0.019
9 2.537 2.024 -0.452 0.039 0.089 0.031 0.019
10 2.639 1.669 -0.277 -0.005 0.036 -0.008 0.019
11 2.707 1.314 -0.214 0.013 0.031 -0.005 0.019
12 2.810 0.926 -0.142 0.062 0.046 0.031 0.019
由于该csv文件是没有列索引的,那么它默认你有列索引,并且把第一行的数据当做列索引,并且从第二行开始设置了行索引,所以说列索引的设置非常重要,起码在这里看来是这样的,那么如何设置呢,下面就具体分析一下。
- 3列索引 header=?的含义
当加上header=None的时候,表明原始文件没有列索引,这样的话会默认自动加上,除非你给定名称。结果如下:
0 1 2 3 4 5 6
0 0.916 4.370 -1.372 0.102 0.041 0.069 0.018
1 0.892 3.955 -1.277 0.015 -0.099 -0.066 0.018
2 0.908 3.334 -1.193 0.033 -0.098 -0.059 0.018
3 1.013 3.022 -1.082 0.151 0.015 0.035 0.018
4 1.111 2.970 -1.103 -0.048 -0.175 -0.171 0.019
5 1.302 3.043 -1.089 0.011 -0.085 -0.097 0.018
6 1.552 3.017 -1.052 0.066 -0.002 -0.036 0.019
7 1.832 2.796 -0.933 0.002 -0.028 -0.075 0.019
8 2.127 2.521 -0.749 0.011 0.041 -0.022 0.019
9 2.354 2.311 -0.623 -0.038 0.012 -0.056 0.019
10 2.537 2.024 -0.452 0.039 0.089 0.031 0.019
11 2.639 1.669 -0.277 -0.005 0.036 -0.008 0.019
12 2.707 1.314 -0.214 0.013 0.031 -0.005 0.019
13 2.810 0.926 -0.142 0.062 0.046 0.031 0.019
当加上header=0的时候,表明原始文件的第0行为列索引。结果如下:
0.916 4.37 -1.372 0.102 0.041 0.069 0.018
0 0.892 3.955 -1.277 0.015 -0.099 -0.066 0.018
1 0.908 3.334 -1.193 0.033 -0.098 -0.059 0.018
2 1.013 3.022 -1.082 0.151 0.015 0.035 0.018
3 1.111 2.970 -1.103 -0.048 -0.175 -0.171 0.019
4 1.302 3.043 -1.089 0.011 -0.085  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









