






 这篇博客介绍了如何使用Python的urllib库进行网页爬取,包括通过urlopen快速获取网页内容以及构造Request对象来设置Http报头,实现更复杂的爬取任务。示例中展示了从百度首页抓取信息并保存到文件的过程。
这篇博客介绍了如何使用Python的urllib库进行网页爬取,包括通过urlopen快速获取网页内容以及构造Request对象来设置Http报头,实现更复杂的爬取任务。示例中展示了从百度首页抓取信息并保存到文件的过程。
爬虫:通过编写程序来获取互联网上的资源
需求:用程序模拟浏览器,输入一个网址,从该网址中获取资源或者内容
工具:pycharm
快速爬取一个网页
# 导入urlopen库
from urllib.request import urlopen
# 指定url
url="https://www.baidu.com/"
# 调用urlopen()方法,客户端发送http请求后,服务器返回的内容封装在一个response对象resp
resp=urlopen(url)
# 使用read()方法读取获取到的网页内容
html=resp.read()
# 输出获取到的网页内容
print(html)
# 获取响应信息对应的url
print(resp.geturl())
# 获取响应码
print(resp.getcode())
# 获取页面的元信息
print(resp.info())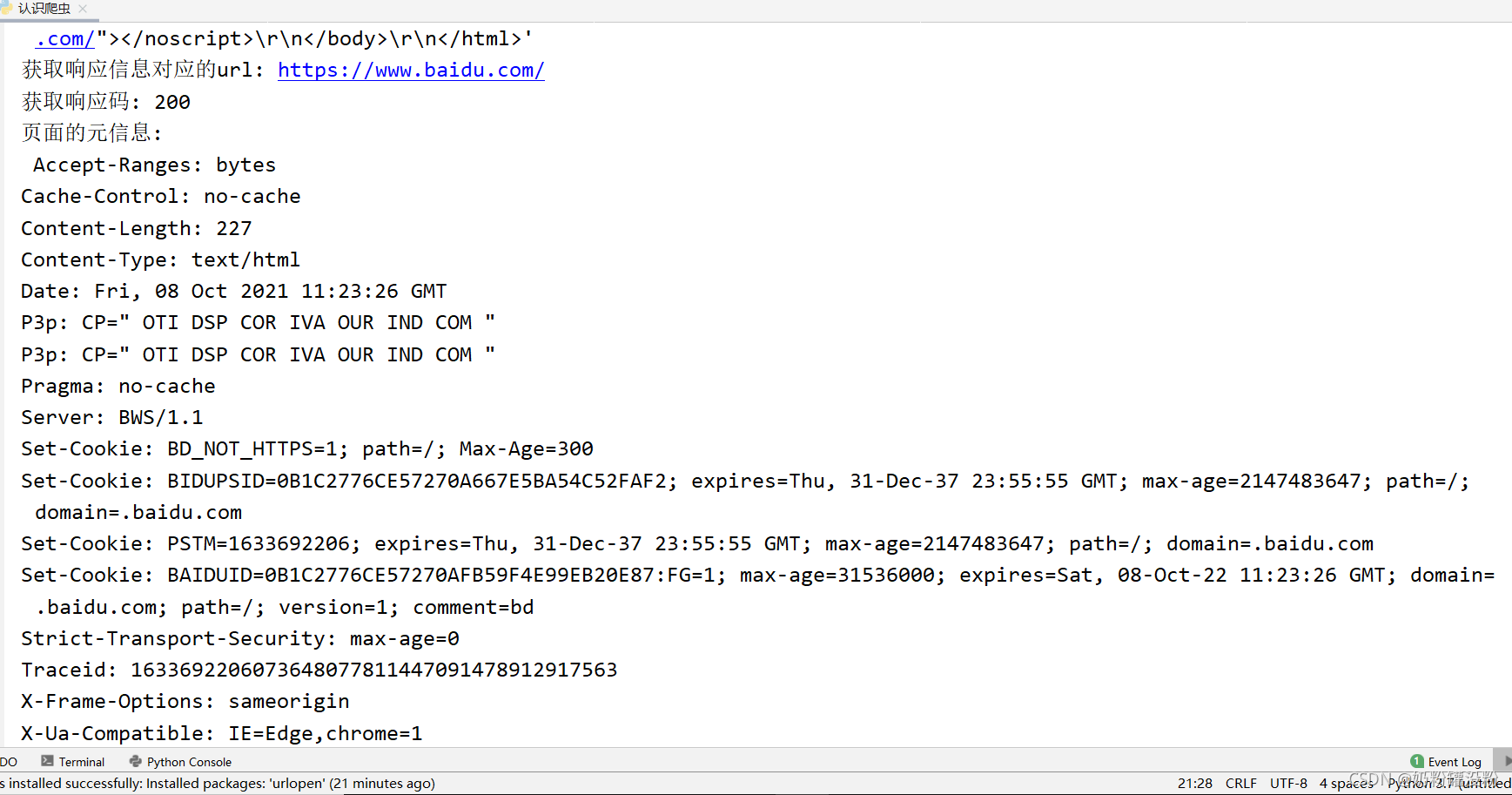
构造Request对象
当使用urlopen()方法发送一个请求时,如果希望执行更为复杂的操作(比如增加Http报头),则必须创建一个Request对象来作为urlopen()的方法。
# 导入urlopen库
import urllib.request
# 指定url
url="https://www.baidu.com/"
# 指定发送Http报头的键值对
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
# 调用request()方法,参数包含url,headers,构造并返回一个Request对象(对象名为re)
re=urllib.request.Request(url=url,headers=headers)
# 将request对象作为urlopen()方法的参数,发送给服务器并接收响应
response=urllib.request.urlopen(re)
# 使用read()方法读取获取到的网页内容
html=response.read()
# 打印网页内容
print('打印网页内容:',html)
# 输出网页的报头信息
print('网页的报头信息:',re.get_header("User-Agent"))
#读取到的信息写入文件中
with open("mybaidu.html",mode="w") as f:
#读取到网页的页面源代码
f.write(html.decode("utf-8"))
print("over!")

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











