







 卷积神经网络(CNN)利用卷积层和池化层处理图像数据,具有平移不变性和局部性的特点。CNN通过多层卷积减少计算量,同时保持高效。通过学习卷积核,网络可以检测图像边缘。填充和步幅用于调整输出尺寸,多输入多输出通道增加了模型的灵活性。1×1卷积层可视为全连接层,用于调整通道数量。LeNet是一个早期的CNN实例,包含卷积和全连接层,用于图像分类。
卷积神经网络(CNN)利用卷积层和池化层处理图像数据,具有平移不变性和局部性的特点。CNN通过多层卷积减少计算量,同时保持高效。通过学习卷积核,网络可以检测图像边缘。填充和步幅用于调整输出尺寸,多输入多输出通道增加了模型的灵活性。1×1卷积层可视为全连接层,用于调整通道数量。LeNet是一个早期的CNN实例,包含卷积和全连接层,用于图像分类。
卷积神经网络
1.从全连接层到卷积
详细请参考教学文档 6.1. 从全连接层到卷积 — 动手学深度学习 2.0.0 documentation
多层感知机十分适合处理表格数据,然而对于高维感知数据,这种缺少结构的网络可能会变得不实用。
卷积神经网络(convolutional neural networks,CNN)是机器学习利用自然图像中一些已知结构的创造性方法。
1.1知识点
-
不变性:儿童游戏”沃尔多在哪里”
-
多层感知机的限制:
-
平移不变性(translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。
-
局部性(locality):神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。
-
卷积
-
通道
1.2小结
-
图像的平移不变性使我们以相同的方式处理局部图像,而不在乎它的位置。
-
局部性意味着计算相应的隐藏表示只需一小部分局部图像像素。
-
在图像处理中,卷积层通常比全连接层需要更少的参数,但依旧获得高效用的模型。
-
卷积神经网络(CNN)是一类特殊的神经网络,它可以包含多个卷积层。
-
多个输入和输出通道使模型在每个空间位置可以获取图像的多方面特征。
2.图像卷积
详细请参考教学文档 6.2. 图像卷积 — 动手学深度学习 2.0.0 documentation
卷积神经网络的设计是用于探索图像数据
2.1互相关运算
严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是互相关运算(cross-correlation),而不是卷积运算。
实现并验证二维互相关运算
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
corr2d(X, K)
"""
tensor([[19., 25.],
[37., 43.]])
"""2.2卷积层
-
卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出。
-
卷积层中的两个被训练的参数是卷积核权重和标量偏置。
-
随机初始化卷积核权重
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias2.3 图像中目标的边缘检测
"""
如下是卷积层的一个简单应用:通过找到像素变化的位置,来检测图像中不同颜色的边缘。 首先,我们构造一个6*8像素的黑白图像。中间四列为黑色(0),其余像素为白色(1)。
"""
X = torch.ones((6, 8))
X[:, 2:6] = 0
X
"""
tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])
"""
# 构造一个高度为1、宽度为2的卷积核K
# 进行互相关运算时,如果水平相邻的两元素相同,则输出为零,否则输出为非零
K = torch.tensor([[1.0, -1.0]])
# 1代表从白色到黑色的边缘,-1代表从黑色到白色的边缘,其他情况的输出为0
Y = corr2d(X, K)
Y
"""
tensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])
"""
# 将输入的二维图像转置,再进行如上的互相关运算
# 检测到的垂直边缘消失
corr2d(X.t(), K)
"""
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
"""
# 这个卷积核K只可以检测垂直边缘,无法检测水平边缘。2.4 学习卷积核
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')
"""
epoch 2, loss 15.223
epoch 4, loss 5.325
epoch 6, loss 2.029
epoch 8, loss 0.805
epoch 10, loss 0.326
"""
# 卷积核的权重张量
# 卷积核权重非常接近我们之前定义的卷积核K
conv2d.weight.data.reshape((1, 2)) # tensor([[ 1.0486, -0.9313]])2.5互相关和卷积
为了与深度学习文献中的标准术语保持一致,我们将继续把“互相关运算”称为卷积运算,尽管严格地说,它们略有不同。 此外,对于卷积核张量上的权重,我们称其为元素。
2.6 特征映射和感受野
当一个特征图中的任意元素需要检测更广区域的输入特征时,我们可以构建一个更深的网络。
2.7 小结
-
二维卷积层的核心计算是二维互相关运算。最简单的形式是,对二维输入数据和卷积核执行互相关操作,然后添加一个偏置。
-
我们可以设计一个卷积核来检测图像的边缘。
-
我们可以从数据中学习卷积核的参数。
-
学习卷积核时,无论用严格卷积运算或互相关运算,卷积层的输出不会受太大影响。
-
当需要检测输入特征中更广区域时,我们可以构建一个更深的卷积网络。
3.填充和步幅
详细请参考教学文档 6.3. 填充和步幅 — 动手学深度学习 2.0.0 documentation
3.1 填充
由于在应用多层卷积时,我们常常丢失边缘像素。 由于我们通常使用小卷积核,因此对于任何单个卷积,我们可能只会丢失几个像素。 但随着我们应用许多连续卷积层,累积丢失的像素数就多了。 解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素(通常填充元素是0)。
填充后输出的形状: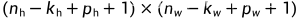
在许多情况下,我们需要设置和
,使输入和输出具有相同的高度和宽度。
"""
创建一个高度和宽度为3的二维卷积层,并在所有侧边填充1个像素。给定高度和宽度为8的输入,则输出的高度和宽度也
是8.
"""
import torch
from torch import nn
# 为了方便起见,我们定义了一个计算卷积层的函数。
# 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数
def comp_conv2d(conv2d, X):
# 这里的(1,1)表示批量大小和通道数都是1
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
# 省略前两个维度:批量大小和通道
return Y.reshape(Y.shape[2:])
# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
comp_conv2d(conv2d, X).shape # torch.Size([8, 8])
# 当卷积核的高度和宽度不同时,我们可以填充不同的高度和宽度,使输出和输入具有相同的高度和宽度。
# 使用高度为5,宽度为3的卷积核,高度和宽度两边的填充分别为2和1。
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape # torch.Size([8, 8])3.2 步幅
有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。将每次滑动元素的数量称为步幅(stride)。
设置步幅后输出的形状为: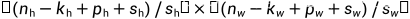
# 将高度和宽度的步幅设置为2,从而将输入的高度和宽度减半。
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape # torch.Size([4, 4])
# 一个稍微复杂的例子
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape # torch.Size([2, 2])3.3 小结
-
填充可以增加输出的高度和宽度。这常用来使输出与输入具有相同的高和宽。
-
步幅可以减小输出的高和宽,例如输出的高和宽仅为输入的高和宽的1/n(n是一个大于1的整数)。
-
填充和步幅可用于有效地调整数据的维度。
4.多输入多输出通道
详细请参考教学文档 6.4. 多输入多输出通道 — 动手学深度学习 2.0.0 documentation
4.1 多输入通道
假设输入的通道数为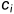 ,那么卷积核的输入通道数也需要为。如果卷积核的窗口形状是
,那么卷积核的输入通道数也需要为。如果卷积核的窗口形状是 ,那么当
,那么当 时,我们可以把卷积核看作形状为的二维张量。
时,我们可以把卷积核看作形状为的二维张量。
import torch
from d2l import torch as d2l
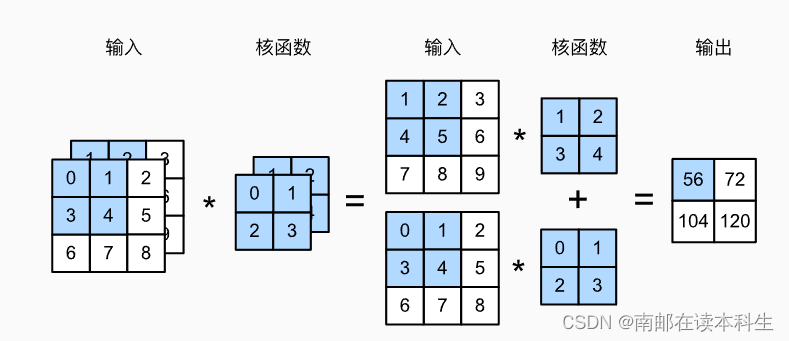
def corr2d_multi_in(X, K):
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
corr2d_multi_in(X, K)
"""
tensor([[ 56., 72.],
[104., 120.]])
"""4.2 多输出通道
用和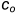 分别表示输入和输出通道的数目,并让
分别表示输入和输出通道的数目,并让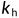 和
和 为卷积核的高度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为
为卷积核的高度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为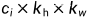 的卷积核张量,这样卷积核的形状是
的卷积核张量,这样卷积核的形状是 。在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。
。在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。
# 实现一个计算多个通道的输出的互相关函数。
def corr2d_multi_in_out(X, K):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
# 通过将核张量K与K+1(K中每个元素加)和K+2连接起来,构造了一个具有个输出通道的卷积核。
K = torch.stack((K, K + 1, K + 2), 0)
K.shape # torch.Size([3, 2, 2, 2])
# 对输入张量X与卷积核张量K执行互相关运算
corr2d_multi_in_out(X, K)
"""
tensor([[[ 56., 72.],
[104., 120.]],
[[ 76., 100.],
[148., 172.]],
[[ 96., 128.],
[192., 224.]]])
"""4.3 1×1卷积层
1×1卷积的唯一计算发生在通道上
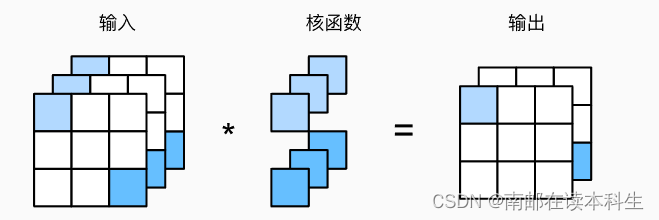
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
assert float(torch.abs(Y1 - Y2).sum()) < 1e-64.4 小结
-
多输入多输出通道可以用来扩展卷积层的模型。
-
当以每像素为基础应用时,1×1卷积层相当于全连接层。
-
1×1卷积层通常用于调整网络层的通道数量和控制模型复杂性。
5.汇聚层
详细请参考教学文档 6.5. 汇聚层 — 动手学深度学习 2.0.0 documentation
汇聚(pooling)层,它具有双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
5.1 最大汇聚层和平均汇聚层
最大汇聚层(maximum pooling):在汇聚窗口到达的每个位置,它计算该窗口中输入子张量的最大值
平均汇聚层(average pooling):在汇聚窗口到达的每个位置,它计算该窗口中输入子张量的平均值
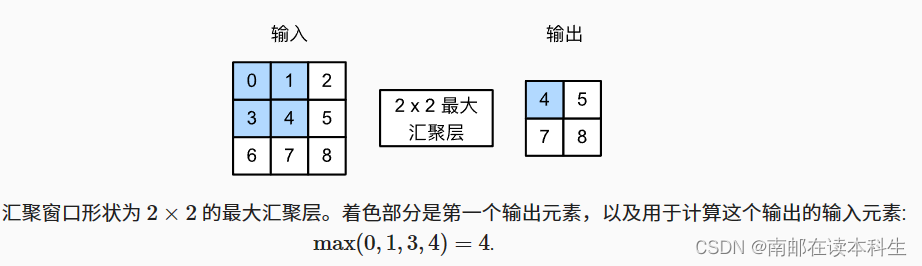
import torch
from torch import nn
from d2l import torch as d2l
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
# 验证二维最大汇聚层的输出
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
pool2d(X, (2, 2))
"""
tensor([[4., 5.],
[7., 8.]])
"""
# 验证平均汇聚层
pool2d(X, (2, 2), 'avg')
"""
tensor([[2., 3.],
[5., 6.]])
"""5.2 填充和步幅
与卷积层一样,汇聚层也可以改变输出形状。
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
X
"""
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]]]])
"""
# 默认情况下,深度学习框架中的步幅与汇聚窗口的大小相同。
# 使用形状为(3, 3)的汇聚窗口,那么默认情况下,我们得到的步幅形状为(3, 3)。
pool2d = nn.MaxPool2d(3)
pool2d(X) # tensor([[[[10.]]]])
# 手动设定填充和步幅
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
"""
tensor([[[[ 5., 7.],
[13., 15.]]]])
"""
# 设定一个任意大小的矩形汇聚窗口,并分别设定填充和步幅的高度和宽度。
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
pool2d(X)
"""
tensor([[[[ 5., 7.],
[13., 15.]]]])
"""5.3 多个通道
汇聚层的输出通道数与输入通道数相同。
X = torch.cat((X, X + 1), 1)
X
"""
tensor([[[[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.]],
[[ 1., 2., 3., 4.],
[ 5., 6., 7., 8.],
[ 9., 10., 11., 12.],
[13., 14., 15., 16.]]]])
"""
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
"""
tensor([[[[ 5., 7.],
[13., 15.]],
[[ 6., 8.],
[14., 16.]]]])
"""6.卷积神经网络(LeNet)
详细请参考教学文档 6.6. 卷积神经网络(LeNet) — 动手学深度学习 2.0.0 documentation
6.1 LeNet
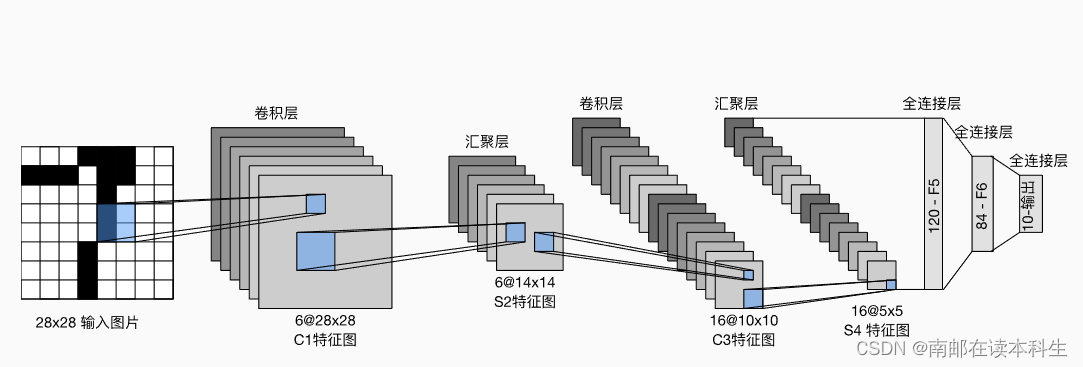
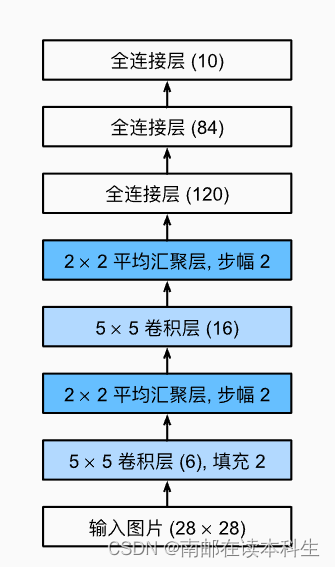
总体来看,LeNet(LeNet-5)由两个部分组成:
-
卷积编码器:由两个卷积层组成;
-
全连接层密集块:由三个全连接层组成。
|
|
-
每个卷积块中的基本单元是一个卷积层、一个sigmoid激活函数和平均汇聚层。
-
第一卷积层有6个输出通道,而第二个卷积层有16个输出通道。
-
卷积的输出形状由批量大小、通道数、高度、宽度决定。
-
LeNet的稠密块有三个全连接层,分别有120、84和10个输出。
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
"""
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
"""6.2 模型训练
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
# 由于完整的数据集位于内存中,因此在模型使用GPU计算数据集之前,我们需要将其复制到显存中。
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
# 训练和评估LeNet-5模型
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
"""
loss 0.467, train acc 0.825, test acc 0.821
88556.9 examples/sec on cuda:0
"""6.3 小结
-
卷积神经网络(CNN)是一类使用卷积层的网络。
-
在卷积神经网络中,我们组合使用卷积层、非线性激活函数和汇聚层。
-
为了构造高性能的卷积神经网络,我们通常对卷积层进行排列,逐渐降低其表示的空间分辨率,同时增加通道数。
-
在传统的卷积神经网络中,卷积块编码得到的表征在输出之前需由一个或多个全连接层进行处理。
-
LeNet是最早发布的卷积神经网络之一。


















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











