








《Very Deep Convolutional Networks for Large-Scale Image Recognition》
- arXiv:[1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition
- intro:ICLR 2015
- homepage:Visual Geometry Group Home Page
1. 论文背景
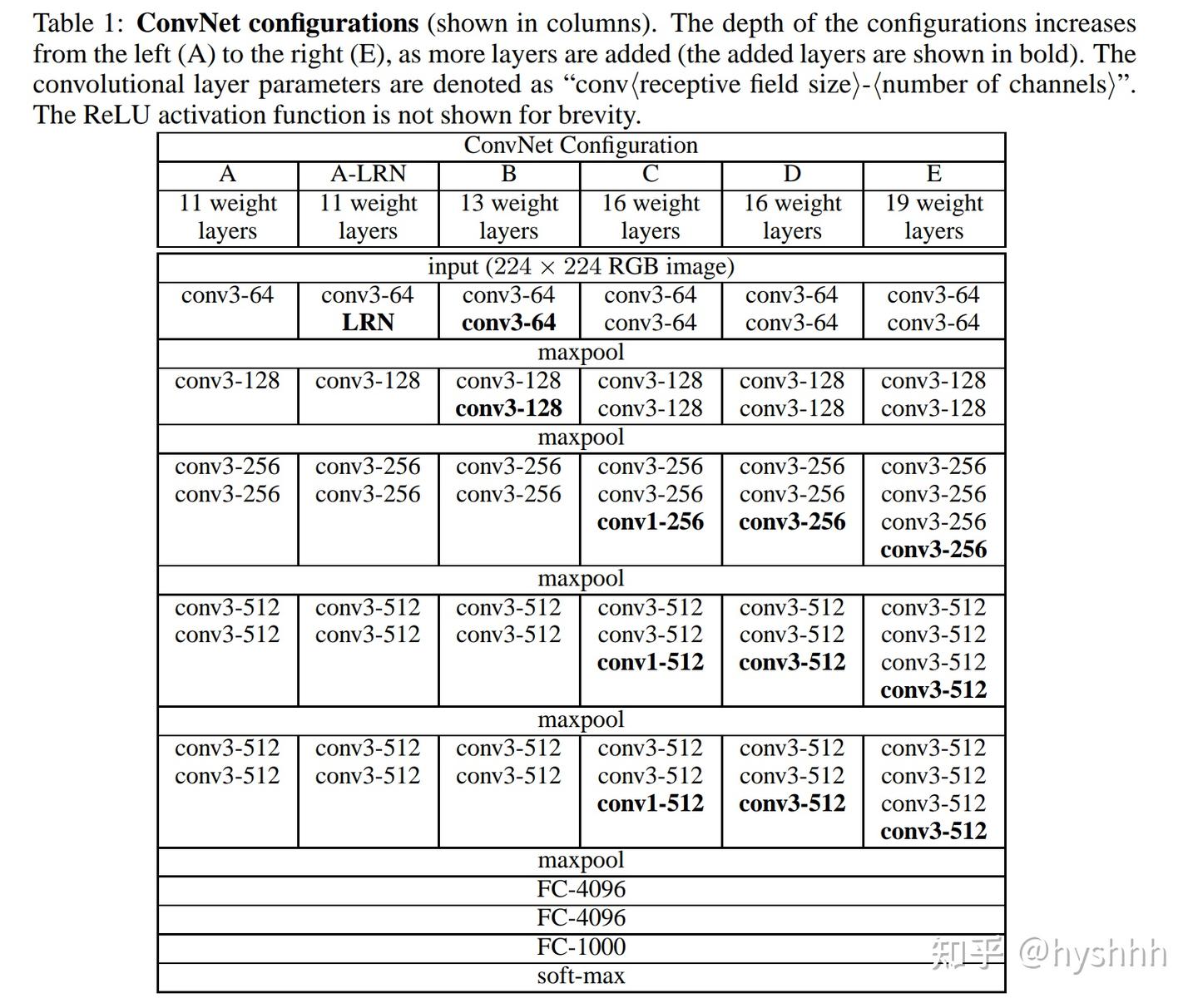
VGG(Visual Geometry Group)网络由 牛津大学计算机视觉组(Visual Geometry Group, VGG) 提出,并在 2014 年的 ImageNet 竞赛(ILSVRC-2014) 中获得了分类任务的 亚军 和定位任务的 冠军。该网络的核心贡献是 使用更深的卷积层 来提升模型性能,同时采用 小卷积核(3×3)来减少参数数量并提高学习能力。VGG的网络结构如下
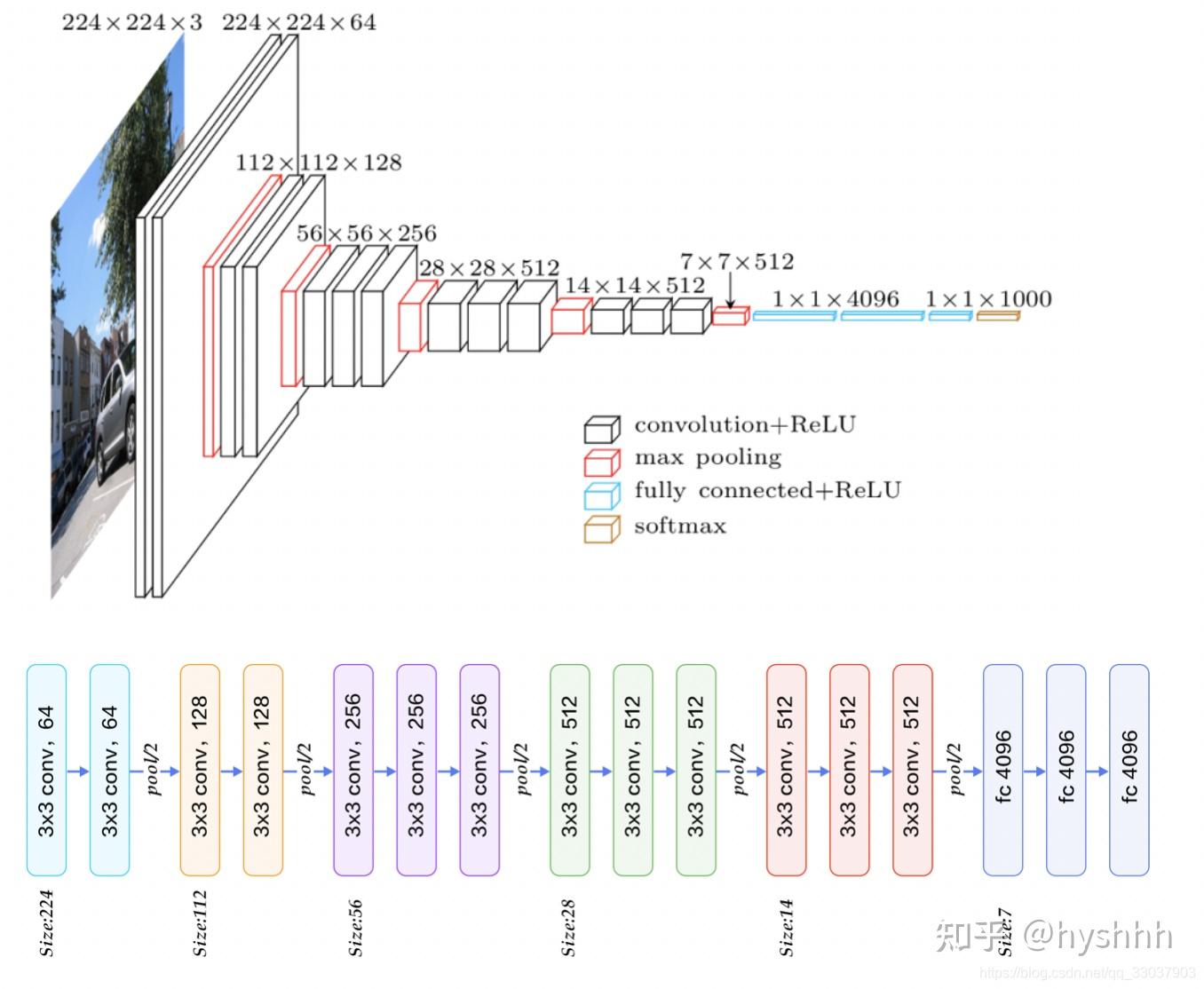
下图可以清楚的知道各个层级的尺度变换和通道变换
2. VGG 的核心思想
VGG 的主要创新点在于:
- 采用更深的网络结构:相比 AlexNet(8 层),VGG 增加到了 16 或 19 层,提升了网络的表达能力。
- 使用小卷积核(3×3):所有卷积层都使用 3×3卷积核,而不是较大的 5×5或 7×7,这样可以:
- 增加非线性能力(两个 3×3卷积相当于一个 5×5巻积)。
- 减少参数数量(比单个 5×5 卷积的参数更少)
3. 使用多个连续的卷积层:VGG 采用 多个连续的 3×3卷积层,然后接一个池化层,而不是直接用大核卷积或池化。
4. 使用最大池化(Max Pooling):采用 2×2 最大池化层 来减少特征图尺寸。
5. 全连接层(FC):在最后使用三个全连接层,其中两个具有 4096 个神经元,最后一个是 Softmax 分类层。
6.输出结果

3. 小巻积核替代大巻积核的原理
一、计算量减少的原理

二、小巻积核替代大巻积核感受野不变原理

下面这张图片可以直观的表现出感受野变换的原理:5*5尺度的区域经过一个3*3的巻积核变成一个3*3的尺度区域,再经过一个3*3巻积核变成一个1*1尺度的区域。这样两个巻积核对5*5尺度区域作用同样得到一个像素拥有5的感受野。与直接使用5*5巻积的感受野相同。
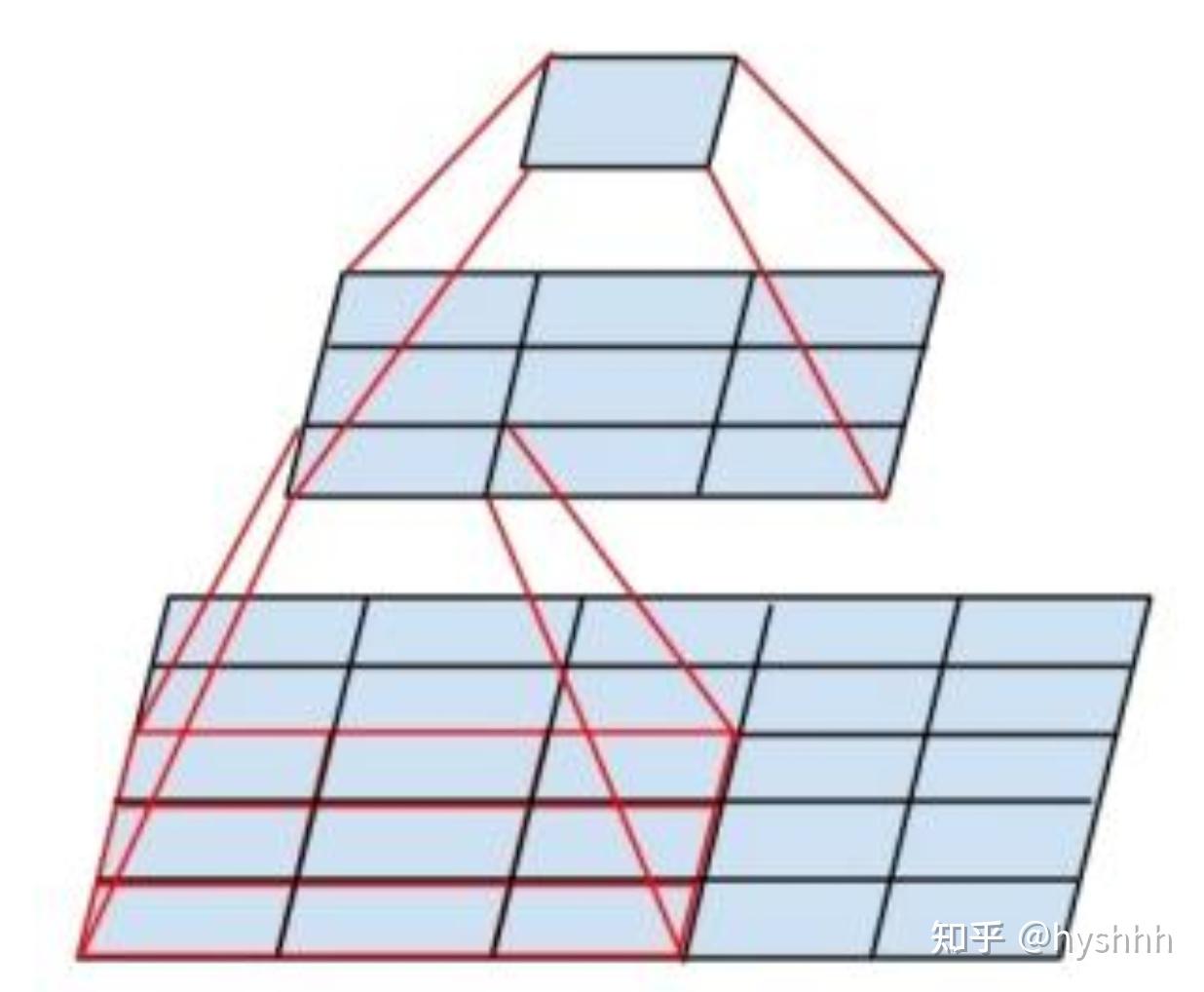
4. 总结一下弊端
一、需要更深的网络,训练更困难
- 用多个 3×3卷积代替大卷积,会增加网络深度,深度过大可能带来梯度消失或梯度爆炸问题。
- 解决方案:
- 使用 Batch Normalization(BN) 进行归一化。
- 采用 ResNet 残差连接,保证梯度有效传播。
可以看我对resnet网络的介绍: hyshhh:何恺明ResNet(残差网络)——彻底改变深度神经网络的训练方式


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









