







1. Pointpillar 介绍、下载与使用方法
KITTI数据集介绍:hyshhh:KITTI数据集介绍、组成结构、可视化方法
pointpillar介绍下载与安装:hyshhh:pointpillar(OpenPCDet)介绍、安装、评价指标介绍
找到各个部分网络对应的文件:hyshhh:OPenPCDet中的pointpillar中各个模块源代码位置与代码原理
2. Pointpillar 改进前准备
之前重写了一下pointpillar神经网络部分代码,以增加易读性并容易修改
hyshhh:重构pointpillar(PCDet)中神经网络部分的代码逻辑
之前改进了特征聚合网络,再此基础上再引入的resnet,其中原理可以看hyshhh:【pointpillar】原创改进3——添加特征聚合(FPN)颈部网络,实现网络有效涨点(3d检测ap涨点6%)
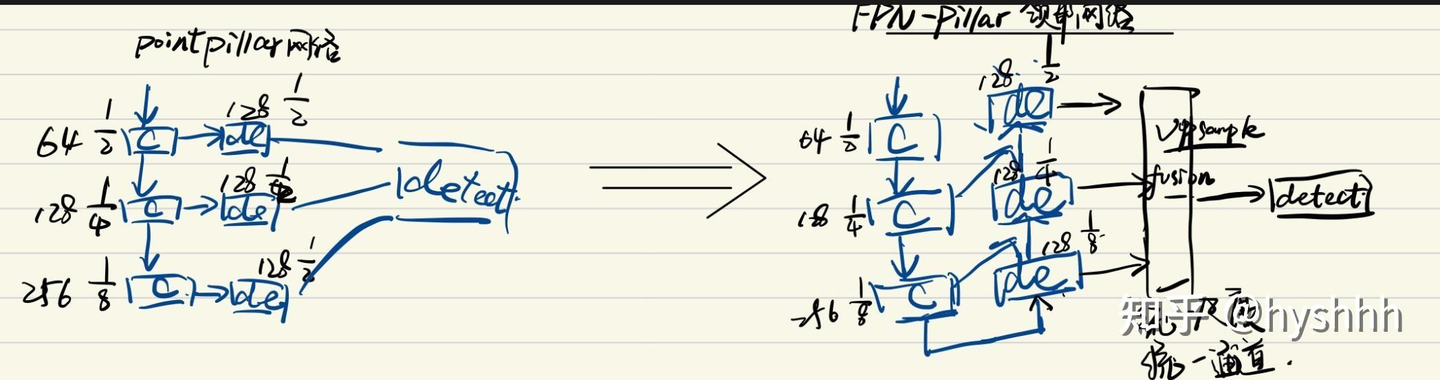
3. 改进方法介绍
SE注意力机制出自SENet,SEnet是resnet的改进版本:resnet原理可以看:hyshhh:何恺明ResNet(残差网络)——彻底改变深度神经网络的训练方式
se注意力机制原理介绍可以看博客:[ 注意力机制 ] 经典网络模型1--SENet 详解与复现
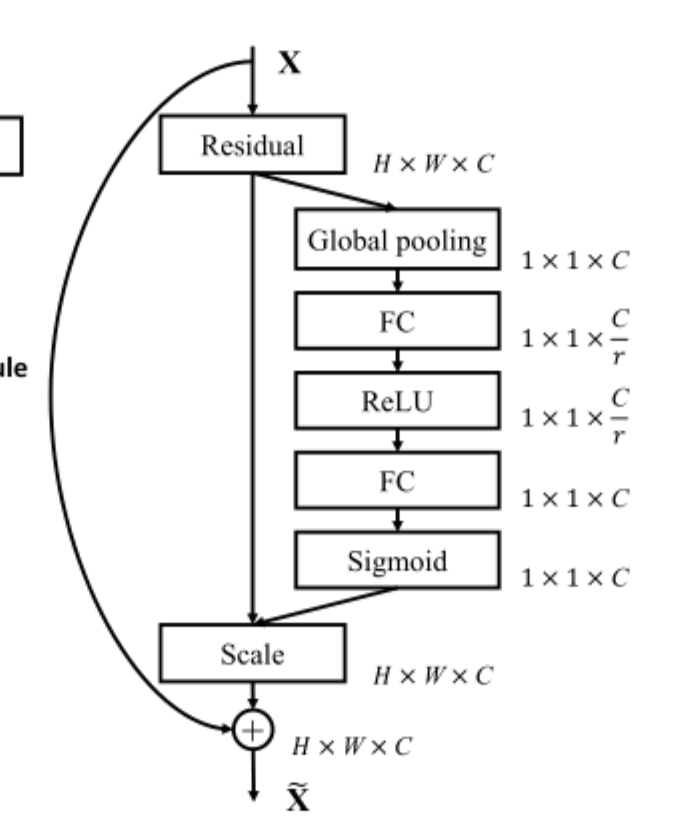
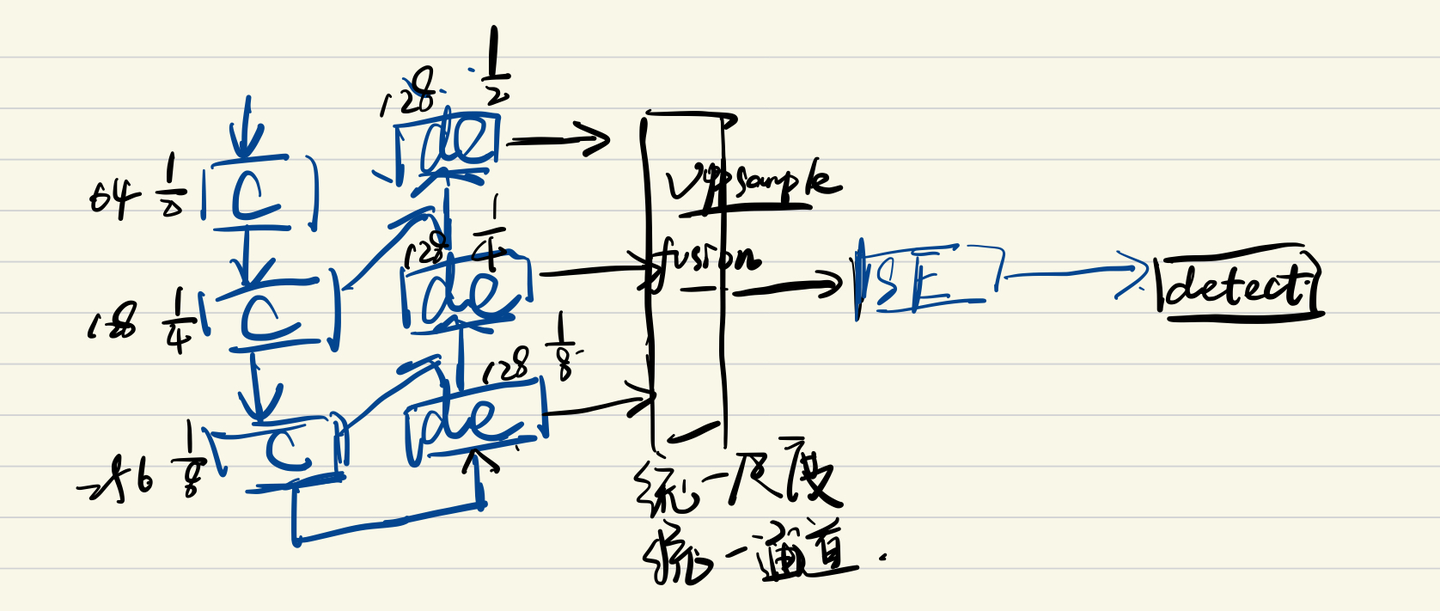
改进方法如图所示,在多尺度融合层之后添加SE注意力机制对所有通道的权重进行加权。
4. 使用方法
找到定义网络类:可以点链接看模块位置
hyshhh:OPenPCDet中的pointpillar中各个模块源代码位置与代码原理

将附录代码全部替换该类的代码 代码中SE类定义的就是SE注意力机制

附录
class deConvModule(nn.Module): #上采样层
def __init__(self, in_channels, out_channels, kernel_size=3, stride=2, padding=0, use_bn=True, use_relu=True):
super(deConvModule, self).__init__()
layers = [nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding, bias=not use_bn)]
if use_bn:
layers.append(nn.BatchNorm2d(out_channels, eps=1e-3, momentum=0.01))
if use_relu:
layers.append(nn.ReLU(inplace=True))
self.deconv = nn.Sequential(*layers)
def forward(self, x):
return self.deconv(x)
class ConvModule2(nn.Module): #可变层卷集
def __init__(self, in_channels, out_channels, kernel_size=3, stride=2, padding=0, use_bn=True, use_relu=True, num_1x1_layers=0):
super(ConvModule2, self).__init__()
layers = []
# 添加 3x3 卷积层
layers.append(nn.ZeroPad2d(1))
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding=0, bias=not use_bn))
if use_bn:
layers.append(nn.BatchNorm2d(out_channels, eps=1e-3, momentum=0.01))
if use_relu:
layers.append(nn.ReLU(inplace=True))
in_channels = out_channels # 保证下一层输入通道匹配
# 添加 1x1 卷积层
for _ in range(num_1x1_layers):
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=not use_bn))
if use_bn:
layers.append(nn.BatchNorm2d(out_channels, eps=1e-3, momentum=0.01))
if use_relu:
layers.append(nn.ReLU(inplace=True))
in_channels = out_channels
self.conv = nn.Sequential(*layers)
def forward(self, x):
return self.conv(x)
#上采样融合层
class upfusion(nn.Module):
def __init__(self):
super().__init__()
self.up1=upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.up2=upsample = nn.Upsample(scale_factor=4, mode='nearest')
def forward(self,ups):
ups[0]=self.up2(ups[0])
ups[1]=self.up1(ups[1])
return ups
class SE(nn.Module):
def __init__(self,in_channels,reduction=4):
super(SE, self).__init__()
self.reduction = reduction # 先存储 reduction,通道数延后处理
layers = [nn.AdaptiveAvgPool2d(1)]
layers.append(nn.Conv2d(in_channels, max(in_channels//self.reduction, 4), kernel_size=1, bias=False))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.Conv2d(max(in_channels // self.reduction, 4), in_channels, kernel_size=1, bias=False))
layers.append(nn.Sigmoid())
self.se = nn.Sequential(*layers)
def forward(self, x):
return self.se(x) # 逐通道加权
class BaseBEVBackbone(nn.Module): #定义网络
def __init__(self, model_cfg, input_channels):
super().__init__()
self.model_cfg = model_cfg
if self.model_cfg.get('LAYER_NUMS', None) is not None:
assert len(self.model_cfg.LAYER_NUMS) == len(self.model_cfg.LAYER_STRIDES) == len(self.model_cfg.NUM_FILTERS)
layer_nums = self.model_cfg.LAYER_NUMS
layer_strides = self.model_cfg.LAYER_STRIDES
num_filters = self.model_cfg.NUM_FILTERS
else:
layer_nums = layer_strides = num_filters = []
if self.model_cfg.get('UPSAMPLE_STRIDES', None) is not None:
assert len(self.model_cfg.UPSAMPLE_STRIDES) == len(self.model_cfg.NUM_UPSAMPLE_FILTERS)
num_upsample_filters = self.model_cfg.NUM_UPSAMPLE_FILTERS
upsample_strides = self.model_cfg.UPSAMPLE_STRIDES
else:
upsample_strides = num_upsample_filters = []
c_in_list = [input_channels, *num_filters[:-1]]
#网络定义和前向传播
#下采样网络
self.c1=ConvModule2(input_channels,64,stride=2,padding=0,num_1x1_layers=3) #0
self.c2=ConvModule2(64,128,stride=2,padding=0,num_1x1_layers=5) #1
self.c3=ConvModule2(128,256,stride=2,padding=0,num_1x1_layers=5) #2
#上采样特征聚合网络
self.d1=deConvModule(256,128,1,stride=1) #3
self.d2=deConvModule(256+128, 128,2,stride=2) #4
self.d3=deConvModule(256,128,2,stride=2) #5
self.Se=SE(in_channels=384)
#上采样融合定义
self.fusion=upfusion()
c_in = sum(num_upsample_filters)
self.num_bev_features = c_in
def forward(self, data_dict):
spatial_features = data_dict['spatial_features']
ups = []
co=[] #存放中间变量
ret_dict = {}
x = spatial_features
#下采样层
x=self.c1(x) #0
x=self.c2(x) #1
co.append(x)
x=self.c3(x) #2
co.append(x)
#上采样特征聚合网络
x=self.d1(x) #3
ups.append(x)
x=torch.cat((x,co[1]), dim=1) #4
x=self.d2(x) #5
ups.append(x)
x=torch.cat((x,co[0]), dim=1) #6
x=self.d3(x) #7
ups.append(x)
ups=self.fusion(ups)
if len(ups) > 1:
x = torch.cat(ups, dim=1) #6
b, c, _, _ = x.size()
x=self.Se(x).view(b, c, 1, 1) *x
elif len(ups) == 1:
x = ups[0]
data_dict['spatial_features_2d'] = x
return data_dict


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









