







NLP经典论文:Attention、Self-Attention、Multi-Head Attention、Transformer 笔记_multi-head attention 原始论文-优快云博客/拆 Transformer 系列二:Multi- Head Attention 机制详解 - 知乎/一文了解Transformer全貌(图解Transformer)
一. 自注意力机制原理:
注意力机制通过计算Query和每个Key之间的相似度来确定关注哪个输入部分。这一过程通常通过点积(dot product)来实现,然后将结果通过一个Softmax函数转换为概率分布,得到每个输入部分的权重。最终的输出是Value的加权求和,权重由上一步的Softmax结果决定。
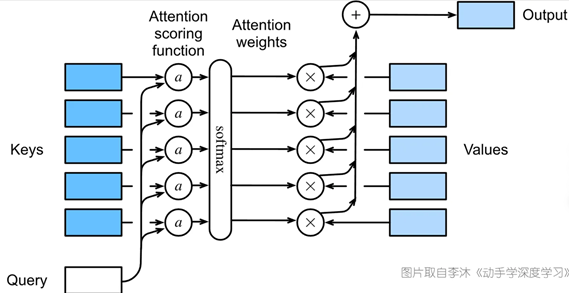
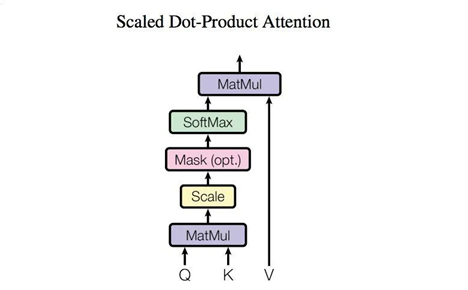
二. 自注意力机制各个模块原理Scaled Dot-Product Attention(若Q=K=V为Self-Attention):



三. 多头注意力机制(Mutiheadattension):
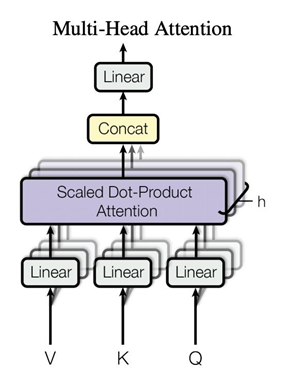
抽象一点说,在 Multi-Head Attention 中, 在 Multi-Head Attention 中,我们将输入的 Query (Q)、Key (K) 和 Value (V) 进行多次独立的注意力计算,每次使用不同的线性变换来生成不同的注意力头(head)。然后,最后将这些头的输出拼接或加权求和,得到最终的结果。举例来说在图像处理中,一个头可能专注于图像的纹理特征,而另一个头则关注图像中的颜色或形状特征。自然语言处理中,一个头可能关注句子中的局部语法结构(如词与词之间的关系),而另一个头则可能关注长距离依赖。其本质任然是Attension的一种形式。
四、Transformer
Multi-Head Attention 主要是一个自注意力机制的扩展,它的目的是提高模型捕捉不同语义子空间的能力。通过并行计算多个注意力头,每个头可以关注不同的输入特征,从而增强模型对复杂模式的理解能力。而Transformer是一个大的网络架构。
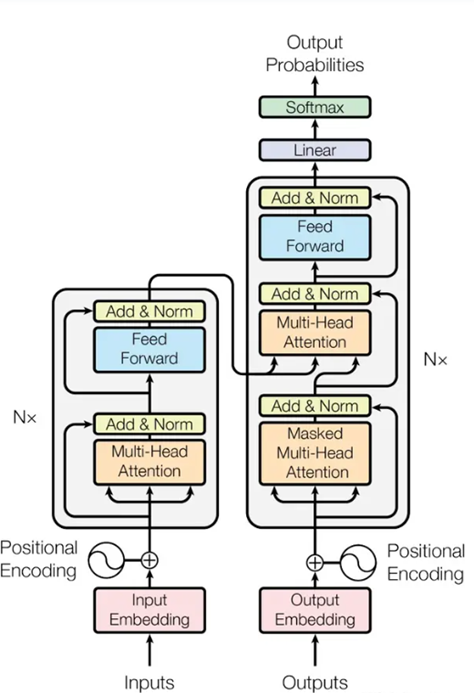
输入处理与位置编码:输入嵌入:输入的序列(如词语)首先会通过嵌入层(Embedding Layer)转化为固定维度的向量。位置编码:由于 Transformer 没有内建的序列顺序信息,所以需要通过位置编码(Positional Encoding)来将序列中每个元素的位置加入到输入的嵌入向量中,帮助模型理解每个词在序列中的位置。 编码器流程(Encoder)(左边的灰色框):
编码器由多个相同的层堆叠而成,每一层主要包含两部分:码器由多个相同的层堆叠而成,每一层主要包含两部分:Multi-Head Self-Attention:每个位置的向量通过自注意力机制与其他位置的向量进行交互,捕捉序列内部的依赖关系。计算过程包括:为输入的每个词生成 Query(Q)、Key(K)和 Value(V)向量。通过点积计算 Query 和 Key 的相似度,再使用 Softmax 计算注意力权重,并用这些权重对 Value 进行加权求和,得到加权的输出。Multi-Head Attention 机制通过多个头并行计算不同的注意力模式,增强了模型的表示能力。前馈神经网络(Feed-Forward Network):经过自注意力层的输出会被送入一个简单的前馈神经网络,它包括两个全连接层,并在中间使用激活函数(如 ReLU)。残差连接与层归一化:每个子层(自注意力层和前馈神经网络)都包含 残差连接 和 层归一化,帮助信息在网络中稳定流动,防止梯度消失。每个编码器层的计算过程如下:输入通过 自注意力机制(Multi-Head Self-Attention)。然后通过 前馈神经网络(Feed-Forward Network)。残差连接和层归一化会在每个步骤中应用,确保信息流动稳定。多个编码器层堆叠后,得到序列的上下文相关表示,这个表示会传递给解码器部分。
解码器流程(Decoder)(右边灰色框):解码器的结构与编码器类似,但在每个解码器层中,会额外有一个 编码器-解码器注意力层(Encoder-Decoder Attention),用于将编码器的输出与解码器的输入进行结合。解码器的每一层主要包括以下部分:Masked Multi-Head Self-Attention:类似编码器中的自注意力层,但为了保证解码器的生成是自回归的(即当前位置只能依赖于之前的输出),当前时间步的输出不能看到未来的信息,因此需要对未来的信息进行遮盖(masking)。Encoder-Decoder Attention:解码器的每个位置都会计算一个与编码器输出的注意力权重。这样,解码器的每个位置可以根据编码器产生的上下文信息生成对应的输出。前馈神经网络(Feed-Forward Network):和编码器一样,解码器的每一层也会有一个前馈神经网络,对每个位置的表示进行非线性变换。残差连接与层归一化:同样,在解码器的每个子层后也会应用残差连接和层归一化。
输出生成:在解码器的最后一层输出之后,通常会经过一个线性变换(Linear Transformation)层,将解码器输出的维度映射到词汇表的大小。接着通过Softmax 层计算每个位置的词汇概率,选择具有最高概率的词作为输出(如机器翻译中的翻译词)。 疑问:对output的嵌入,按理来说output为之前信息的生成,不存在未来信息,为什么Transformer中还要使用掩码多头注意力机制:分析了一下觉得是training时,把正确结果当做decoder的输入,在testing时,把上一个时刻decoder的结果当做当前时刻的输入。

















 7819
7819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









