




ZoomNet 是一项针对伪装目标检测任务提出的创新性方法,受人类“放大-缩小”观察行为启发,构建了一个混合尺度三分支网络。该方法通过多尺度特征提取(Triplet Encoder)、尺度融合模块(SIUs)与分层混合尺度解码器(HMUs)协同挖掘微弱语义差异,显著增强模型对低对比度、模糊边界目标的识别能力。同时,引入不确定性感知损失(UAL)以提升对模糊区域的鲁棒性,在多个COD数据集上全面超越现有主流方法,展现出卓越的检测性能与良好的泛化能力。
模型结构:
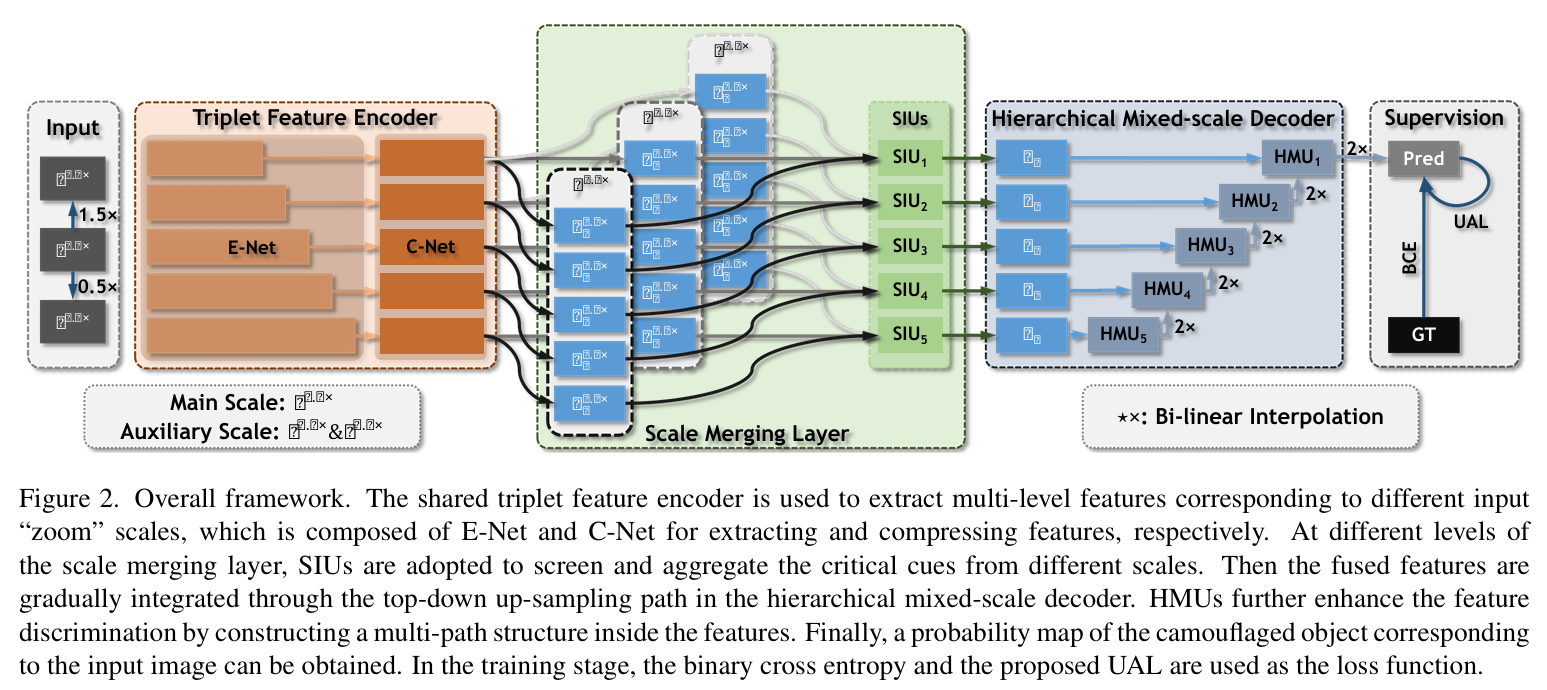
整体流程:
一、输入:Mixed-scale 图像
-
模拟人眼“缩放”观察模糊目标的过程。
-
图像被缩放为三个尺度:
-
主尺度(Main Scale):1.0×
-
辅助尺度(Auxiliary Scales):0.5× 和 1.5×
-
-
三个尺度共享一套编码器结构,统一提取多尺度信息。
二、Triplet Feature Encoder(三分支特征编码器)
-
包含两个子模块:
-
E-Net:特征提取(用的是 ResNet-50 前几层)
-
C-Net:通道压缩(用于降维和减少计算)
-
-
三个尺度图像分别经过 E-Net 和 C-Net,输出多尺度的五层特征金字塔。
三、Scale Merging Layer(尺度融合层)
-
中间的蓝色部分。
-
每一层(共5层)分别包含一个 SIU(Scale Integration Unit),用于融合多尺度特征。
-
融合方式:
-
辅助尺度(0.5×、1.5×)通过插值对齐主尺度(1.0×)的分辨率;
-
计算每尺度的注意力权重;
-
三尺度加权融合 → 输出一个融合特征。
-
四、Hierarchical Mixed-scale Decoder(层级式混合尺度解码器)
-
类似 U-Net 的结构,采用 Top-down 逐层上采样融合。
-
每一层融合模块是一个 HMU(Hierarchical Mixed-scale Unit),作用:
-
通道分组:将通道划分为若干组,组内串联处理;
-
通道调制:自动调节每组通道的重要性;
-
增强多尺度特征表达能力。
-
-
每个 HMU 输出特征都会上采样(×2)与上层融合。
五、Supervision(监督与损失函数)
-
解码器最终输出为预测概率图 Pred。
-
使用两种损失进行训练:
-
BCE(Binary Cross Entropy)Loss:与 GT 标签直接比对;
-
UAL(Uncertainty-aware Loss):增强对模糊/不确定区域的区分能力。
-
-
联合优化,提升目标边缘、低置信度区域的检测质量。
模块:
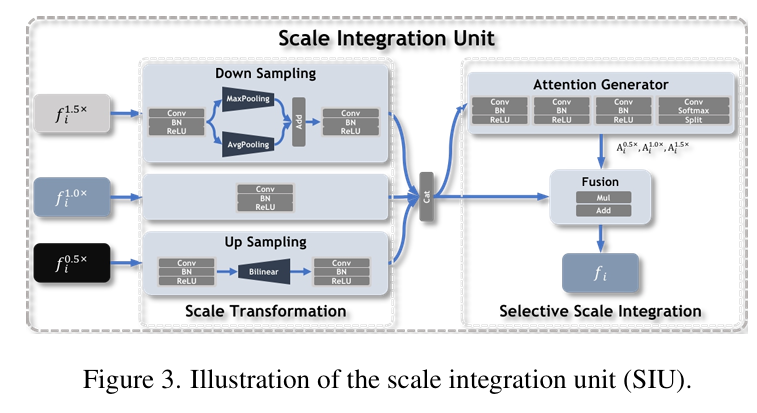
尺度融合单元(Scale Integration Unit, SIU):将三个不同
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









