







总结
这周是开启学习的第一周,主要是精读了 GEN-VLKT 和 HOICLIP 这两篇图像 HOI 的经典论文。
主要学习到的是
- HOI 领域的挑战(数据数据较少,从 CLIP 迁移学习。unseen interaction 的检测。双阶段方法的后匹配开销。)、近年的研究方法致力于解决什么问题。
- 对 HOI 任务有了一个大概的了解:
- 自底向上的方法就是先检测人和物,再检测它们之间的交互。
- 自顶向下的方法就是直接从交互的检测入手,再根据规则检测人和物
- 具体的细节要在调试运行代码的过程中再细究。
下周计划: - 运行调试 GEN-VLKT 的代码,捋清楚整一个流程以及其中的细节
- 阅读 HOI 领域近年的综述,对整个领域有个大致的了解,目前最先进的方向是怎么做的。
- 再往后还是要转到视频 HOI 领域,毕业设计计划就是这个,我们月底要交开题报告。
疑问
- 长尾分布
- Unseen interaction:这个大概明白了,在 HOICLIP 中解释了为什么要考虑数据集中没有的交互类型:训练数据可能是只有 A 人物和 B 物体和 C 动作,所以就不可能识别出来 A 人物和 A 物体和 A 动作这么一个组合,但是实际场景中的应用可能就会出现这种情况。
- 为什么是 CLIP
- HOI 的数据标注太昂贵,要从预训练的语言-视觉模型中迁移语义
- CLIP 具备的知识能够解决检测 unseen interaction 问题
开始
这周是开始研究生阶段科研的第一周,老师让我开始学习,每周日向他汇报。
我的研究方向是视频的 HOI(human object interaction)检测,我和研究生学姐交流了一下,可以先从图像的 HOI 开始入门,她给我推荐了两个经典的论文(GEN-VLKT 和 HOICLIP),初步的规划就是先阅读这两篇论文,再阅读它们引用的部分论文,对图像 HOI 有个初步的了解。
视频 HOI 检索文献关键词:Video Relation Detection/Video Visual Relation Detection
GEN-VLKT
摘要
HOI 人物可以被分成两个问题:人物人-物关联和交互理解。
传统的查询驱动(query-driven)的检测器有两方面的不足:
- 对于关联任务,双分支方法需要花费成本来进行后匹配。解决方法:我们提出用 Guided Embedding network 来实现无后匹配的双分支检测任务。在 GEN 中,设计了一个 instance decoder,用两个独立的查询集来检测人和物体,设计了一个 position guided embeding 来标记同一个位置的人和物体。还设计了一个交互解码器(interaction decoder)来对交互进行分类,交互查询由每个 instance decoder layer 输出生成的 instance guided embeding 组成。
- 对于交互理解部分,先前的方法存在长尾分布和零样本发现的问题。本文提出 visual-linguistic knowledge transfer(视觉语言知识迁移)的训练策略,通过从视觉语言预训练模型 CLIP 中迁移知识来增强交互理解。具体的,使用 CLIP 对所有标签提取文本嵌入来初始化分类器,并采用模仿损失最小化 GEN 和 CLIP 之间的视觉特征距离,因此,GEN-VLKT 在多个数据集上的表现均优于当前的先进水平。
介绍
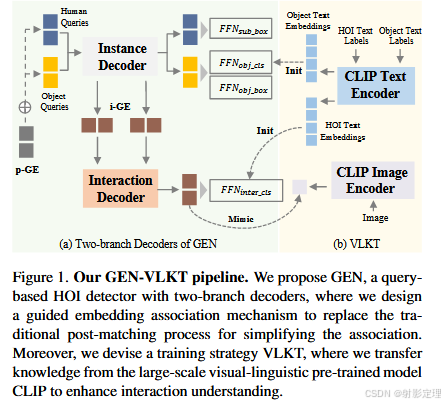
人与物体交互 ( Human-Object Interaction,HOI )检测是使机器在细粒度水平上理解静态图像中人类活动的一项重要任务。在该任务中,人类活动被表示为一系列 HOI 三元组< Human,Object,verb>,因此,需要一个 HOI 检测器来定位人和物体对,并识别它们之间的相互作用。HOI 检测的核心问题是探索如何将交互的人和物体对关联起来,理解它们之间的相互作用。因此,我们考虑从这两个方面对 HOI 检测器进行改进,设计一个统一的、性能优越的 HOI 检测框架。我们首先回顾了传统方法在这两个方面所做的努力。
对于关联任务,主要分为自底向上和自顶向下的两种方法:
- 自底向上的方法先检测人和物,然后通过分类器或图模型将人和物关联起来。
- 自顶向下的方法通常设计一个锚点来表示交互,例如交互点和查询,然后通过预定义的关联规则找到相应的人和物体。
得益于 vision transformer 的发展,基于查询的方法正在引领 HOI 的主流:两分支预测再匹配方式和单分支直接检测方式。 - 双分支方式预测交互,然后与人和物体进行匹配,难以设计有效的匹配规则和复杂的后处理。
- 单分支方式提出以端到端的方式,基于多个头的单个查询来检测人、物体以及相应的交互。
然而,我们认为人体检测、物体检测和交互理解这 3 种任务在特征表征上存在显著差异,其中人体和物体检测主要关注其对应区域的特征,而交互理解则关注人体姿态或情境。
为了改进这一点,如图 1 a 所示,我们提出在去除复杂的后匹配的同时保持双分支结构。为此,我们提出了引导嵌入网络 ( Guided Embedding Network,GEN ),其中我们采用了先视觉编码器后双分支解码器的架构,即实例解码器和交互解码器,并设计了引导嵌入 (guiding embeding)机制来引导事先关联。两个分支均采用基于查询的 transformer decoder 架构。(既要保留双分支结构,又要去除复杂的后匹配机制)
对于实例解码器,我们设计了两个独立的查询集用于人和物体的检测。进一步,我们开发了一个位置引导嵌入 ( position Guided Embedding,p-GE ),通过将人类查询和对象查询分配在同一位置作为一对来区分不同的人-物对。(通过 p-GE 来确定人-物对)
对于交互解码器,我们设计了一个实例引导嵌入 ( i-GE ),在该实例中,我们生成每个由特定的人和对象查询引导的交互查询,以预测其 HOI。因此,GEN 可以为不同的任务提供不同的特征,并在不进行后匹配的情况下引导网络前进过程中的关联。(通过 i-GE 生成交互查询,从而预测 HOI)
对于交互理解问题,大多数传统方法直接应用从数据集中拟合的多标签分类器来识别 HOI。然而,由于现实场景中复杂的人类活动和各种交互对象,这类范式存在长尾分布和零样本发现的问题。
尽管最近的方法提出通过数据增强或精心设计的损失来缓解此类问题,但由于昂贵的 HOI 注释(数据量少),性能增益和扩展能力受限于有限的训练规模。
我们不妨将目光放在图文数据上,图文数据可以很容易地从互联网上获得,而 HOI 三元组可以很自然地转换成文字描述。
得益于视觉-语言预训练模型的发展,尤其是 CLIP 在大约 4 亿个图文对上建立了强大的视觉-语言模型,并在大约 30 个任务上展示了其强大的泛化能力。因此,CLIP 能够覆盖现实生活中的大部分 HOI 场景,为理解 HOI 带来了新的思路。(HOI 专门的数据集缺失,但是 CLIP 等视觉-语言预训练模型的发展,提供了充分的 text-image 特征,能够满足 HOI 场景的需求)
如图 1 b 所示,我们设计了 VLKT 训练策略,将 CLIP 中的知识传递给 HOI 检测器,在不增加额外计算开销的情况下增强交互理解。
我们考虑了 VLKT 中的两个主要问题。一方面,我们设计了一个文本驱动的分类器用于先验知识整合和零样本 HOI 发现。具体来说,我们首先将每个 HOI 三元组标签转换为短语描述,然后基于 CLIP 的文本编码器提取它们的文本嵌入。最后,我们应用所有 HOI 标签的文本嵌入来初始化分类器的权重。通过这种方式,我们可以很容易地扩展一个新的 HOI 类别,只需要将其文本嵌入添加到矩阵中。
同时,我们还采用了 CLIP 初始化的对象分类器来进行新的对象扩展。另一方面,对于文本驱动的分类器和视觉特征对齐,我们提出了一种知识蒸馏方法来指导 HOI 检测的视觉特征来模仿 CLIP 特征。
因此,基于 VLKT,该模型可以很好地捕获 CLIP 中的信息,并且容易扩展到新的 HOI 类别,在推理过程中不会产生额外的成本。
最后,基于以上两个设计,本文提出了一个新的统一的 HOI 检测框架 GEN - VLKT。我们在 HICO - Det 和 V - COCO 两个具有代表性的 HOI 检测基准上验证了我们的 GEN - VLKT 的有效性。我们的 GEN - VLKT 在两个基准数据集和 HICO - Det 数据集的零样本设置上都显著地改进了现有的方法。具体来说,我们的 GEN - VLKT 在 HICO - Det 上取得了 5.05 m AP 的增益,在 V - COCO 上取得了 5.28 AP 的提升。与先前最先进的方法 ATL 相比,对于不可见物体的零样本设置,它的性能也显著提高了108.12 %的相对 mAP 增益。
相关工作
HOI 检测
讲了介绍中提到的两种方法:自底向上和自顶向下。
然而,自底向上的方法要处理大量的人体物体对,这是昂贵的计算消耗,为了缓解这个问题,自上而下的方法变得流行。自上而下的方法主要设计一个额外的锚点来关联人和物体,并预测他们的交互。
随着 vision transformer 的发展,锚点从早期的交互点和联合框,到最近的交互查询。
最近 CDN 提出了一种一阶段的方法使用级联编码器挖掘了上述的两点的好处,然而我们的 GEN 和 CDN 有三方面的不同:
1)解码器的组织:GEN 具有两分支管道,实例和交互解码器,而 CDN 将 HOI 检测分解为两个串行解码器。
2)实例查询设计:GEN 采用位置嵌入的两个隔离的人与物查询,而 CDN 将人与物纠缠成统一的实例查询。
3)动机:GEN 旨在以引导学习的方式取代复杂的后处理,而 CDN 旨在挖掘两者的好处。(对比 CDN 和我们的方法,似乎 CDN 是一篇很关键的论文,需要去读一下)
零样本 HOI 检测
零样本 HOI 检测倾向于检测训练数据中看不见的 HOI。具体来说,通过对动词和物体的解缠图例来分解人和物体的特征,然后再推理过程中产生新的 HOI 三元组。
VCL 通过将分解的宾语和动词特征与成对图像和图像内相结合,组成了新颖的 HOI 样本。
FCL 提出了一个对象制造器来为罕见和看不见的 HOI 生成假对象表示。
ATL 从额外的对象图像中探索对象可供性,以发现新颖的 HOI 类别。
ConsNet 将对象、动作和交互之间的关系显式编码为无向图,以在 HOI 类别及其组成部分之间传播知识。
视觉语言模型将具有先验语言知识的可见视觉短语嵌入转移到不可见的 HOI 中。
方法
Guided Embedding Network
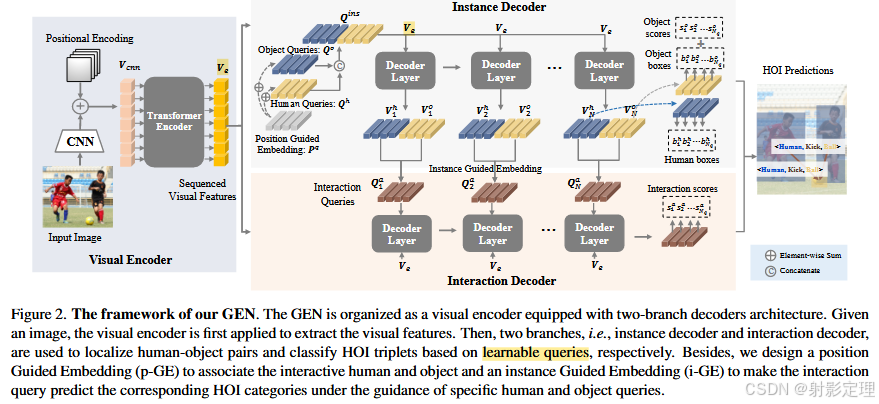
如图 2 所示,GEN 的架构为一个编码器后面跟着两分支解码器。
先用具备 transformer encoder 的 CNN 作为视觉编码器提取视觉特征
V
e
V_e
Ve,然后使用双分支解码器来检测 HOI 三元组(即 instance 解码器和 interaction 解码器)。
在实例解码器中,基于
V
e
V_e
Ve,我们分别通过人类查询集
Q
h
Q_h
Qh 和物体查询集
Q
o
Q_o
Qo,来检测人类和物体。还设计了一个位置引导嵌入 p-GE,将人和物体的查询分配在同一位置的作为一对。
在交互解码器中,我们首先通过计算相应实例解码器层中人类和物体查询的输出都平均值来动态生成每个交互解码器层的交互查询
Q
i
a
Q_i^a
Qia,因此交互解码器可以在人类和物体查询的指导下预测相应的 HOI 类别,最后由解码器的输出生成 HOI 检测结果。
Visual Encoder
我们遵循基于查询的 transformer 检测器,用 CNN-Transformer 作为视觉编码器的架构,对于图像 I 作为输入, CNN 首先提取低分辨率的视觉特征 V c n n V_{cnn} Vcnn H ′ ∗ W ′ ∗ C ′ H' * W' * C' H′∗W′∗C′,之后,我们减少通道数到 C e C_e Ce,将前两项展平,最后,我们将添加余弦位置嵌入的简化特征输入到 transformer encoder 中,并为以下任务提取序列视觉特征 V e V_e Ve ( H ′ ∗ W ′ ) ∗ C e (H' * W') * C_e (H′∗W′)∗Ce.
Decoders
两个分支中的解码器共享相同的架构,我们遵循基于 transformer 的检测器,采用基于查询的 transformer decoder 架构。
首先,我们将一组可学习的查询 Q,最后一层的输出、视觉特征
V
e
V_e
Ve 和位置嵌入提供给 N 个 decoder 层,并在自注意力和共同注意力操作后输出更新的查询,然后使用单独的 FFN 头,将查询转换为其专用任务的嵌入,即分别由第一和第二 decoder 分支进行 instance 和 interaction 表示。
对于 instance decoder,我们首先初始化两组查询来检测人和物体,然后我们为两个查询集设计一个额外的可学习位置引导嵌入 p-GE,以将人类查询和对象查询作为一对分配在同一位置。我们把 p-GE 加入到查询集中。
将
Q
i
n
s
Q^{ins}
Qins 输入到 instance 编码器中可以预测人类-物体边界框对(
b
i
h
,
b
i
o
,
s
i
o
b_i^h, b_i^o, s_i^o
bih,bio,sio),分别表示人类边界框、物体边界框、对象类别分数。提取每个 decoder 解码的中间特征作为 instance decoder 的输入
V
i
n
s
V_{ins}
Vins。
Instance decoder 的目标是预测相应的人-物对的 HOI 类别,因此需要该分支将交互查询和人-物查询对相关联并对交互进行分类。因此我们引入用于关联的 instance Guided embedding iGE。(也就是说,因为预测目标的 HOI 类别需要交互查询和人-物对查询进行相关联,所以设计了一个 iGE 来关联)。
区别于随机初始化的传统可学习嵌入,我们动态生成 i-GE 作为 instance 查询,来知道交互查询匹配人-物对,通过这种方法,我们在中间视觉特征 (
V
h
,
V
o
V^h,V^o
Vh,Vo) 的指导下生成 i-GE。具体来说,对于第 k 层的交互 decoder,交互查询
Q
k
a
Q_k^a
Qka 由第 k 层实例解码器输出得来。
![![[IMAGE_003]]](https://i-blog.csdnimg.cn/direct/50fe8d5482764907b19ea012deccc133.png)
Visual - Linguistic knowledge transfer
介绍 instance decoder 和 interaction decoder 的训练流程,从大规模视觉语言预训练模型(visual-linguistic pretraind model) CLIP 转移(transfer)知识(knowledge),即 VLKT。
首先采用 CLIP 文本嵌入对交互和对象进行分类,然后将视觉知识从 CLIP 图像嵌入转移到交互 decoder。
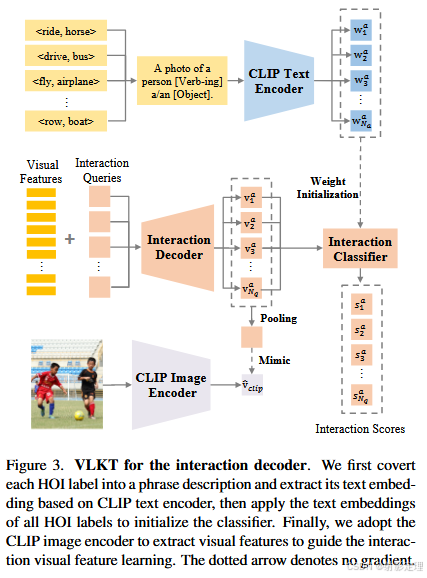
用于分类器初始化的文本嵌入
为了生成 CLIP 文本嵌入,我们首先将 HOI 三元组标签和对象标签转换为文本描述, 此外,“无交互类型"表示为"人和【对象】的照片”。至于对象标签,我们将其转换为短语"一张【对象】的照片"。(如何实现 CLIP 文本嵌入,将 HOI 三元组转换为短语)
我们通过预训练的 CLIP 文本编码器离线生成每个 HOI 和对象文本标签的文本嵌入。最后,得到 HOI 标签
E
a
E^a
Ea 和对象标签
E
o
E^o
Eo。
得到文本嵌入后,我们的目标是在此类文本嵌入的先验知识的指导下对交互和对象进行分类。直观的想法是采用这种嵌入来初始化可学习分类器的权重,并以较小的学习率微调分类器以适应特定的数据集。通过这种方式,每个输出查询特征都与所有微调的文本嵌入计算余弦相似度,并在分类过程中返回相似度得分向量。
视觉嵌入模仿
CLIP 在图像-文本对数据上进行训练,并将视觉嵌入和文本嵌入对齐到统一的空间中。我们设计了一种视觉嵌入模仿机制,通过拉动交互特征和 CLIP 视觉嵌入之间的距离,将视觉特征拉入到这样的同一空间。
CLIP 充当老师,interaction decoder 是学硕,从全局图像级别设计知识蒸馏策略。将调整大小和裁剪的图像输入到预训练的 CLIP 视觉编码器中,提取视觉嵌入
v
c
l
i
p
v_{clip}
vclip,全局学生视觉嵌入是通过对所有输出交互查询特征进行平均池化生成的。L 1 损失用于拉进学生和老师之间的距离,用全局知识蒸馏表述为:
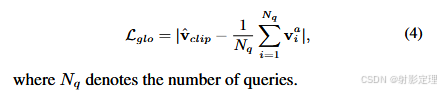
HOICLIP
摘要
CLIP 模型在通过知识蒸馏为 HOI 检测器提供交互先验方面展示了巨大的潜力。
然而,这种方法依赖大规模的训练数据,并且在少/零样本场景表现不好。
所以:本文提出的 HOI 检测框架能够高效的从 CLIP 中提取先验知识并实现更好的泛化。
新颖的交互解码器(interaction decoder):通过交叉注意力机制提取 CLIP 视觉特征图中的信息区域,然后通过知识集成块将其与检测主干进行融合。
利用 CLIP 文本编码器中的先验知识,通过嵌入 HOI 描述生成分类器。
为了区分细粒度的交互,我们通过视觉语义算法和轻量级的动词表示适配器从训练数据中构建了一个动词分类器。
免训练的增强来利用 CLIP 的全局 HOI 预测。
在 HICO-Det 上提高 4.04 mAP
介绍
先介绍 HOI:近年来端到端的目标检测器使得发展迅速,但是人-物对之间的交互类别分类仍然是个挑战。
传统方法的问题:仍然通过训练一个多标签分类器,然而这样需要大规模的数据训练,这样就导致了长尾分布问题以及对于 unseen 交互的泛化能力差。
CLIP 科研用于解决此类开放词汇和零样本学习问题,因为其学习的视觉和语言表示在各种下游任务中的强大的迁移能力。
特别的:最近关于开放词汇检测的工作利用知识蒸馏将 CLIP 的对象标识迁移到对象检测器,这种策略也被用于 HOI 检测的工作。
开放式问题:如何高效的迁移 CLIP 的知识用于 HOI 识别任务中。
- 首先,通常采用的师生蒸馏目标与提高学生模型的泛化性并不一致
- HOI 任务重的知识蒸馏需要大量训练数据,效率较低。
- 零样本泛化中会出现性能下降的问题,缺乏对看不见的类的训练信号。
为了解决上述挑战,提出一个新的策略:HOICLIP。
我们的设计思想:直接从 CLIP 中检索学习到的知识,而不是依赖知识蒸馏,并通过 HOI 识别的组成性质从多方面挖掘先验知识。
应对低数据条件下的动词识别中的长尾和零样本学习问题:开发了一种基于视觉语义算法的动词类别标识。
从三个方面学习从 CLIP 中检索先验知识:
- 空间特征,仅从信息丰富的图像区域提取特征,利用 CLIP 的具有空间维度的特征图,开发了基于 Transformer 的 interaction decoder,学习具有跨模态注意力的局部交互特征
- 动词特征:为了解决长尾动词分类问题,开发了动词分类器,专注于学习动词的更好表示,由动词特征适配器和一组通过视觉语义计算得到的类权重组成。融合动词分类器和普通交互分类器增强 HOI 预测。
- 语义特征:为了应对 HOI 预测中非常罕见和不可见的类别,采用一种基于提示(prompt)的语言表示,构建了一个零样本分类器,不需要训练,在推理时将其输出与 HOI 分类器集成。
贡献:
- 第一个利用基于查询的知识检索来实现预训练的 CLIP 模型到 HOI 检测任务的有效知识迁移工作。
- 开发了一种细粒度迁移策略,通过交叉注意力利用 HOI 的区域视觉特征和通过视觉语义算法获得更有表达力的 HOI 表示。
- 通过利用零样本 CLIP 只是来进一步提高 HOICLIP 性能,无需额外训练。
相关工作
HOI 检测
- Hoi 检测任务主要涉及:目标检测、人-物配对、交互识别。
- 以前的方法:
- 两阶段:用一个独立的检测器获取对象的位置和类别,专门设计人-物关联和交互识别的模块。经典的策略是用基于图的方法提取关系信息来支撑交互理解。
- 一阶段:直接检测具有交互的人-物对,不需要分阶段处理。
- 基于 Transformer 的方法
- GEN-VLKT 进一步设计了一个双分支管道提供并行的转发过程,使用人和对象分离的查询代替 CDN 中的统一查询。
- RLIP 提出了一种基于图像描述的 HOI 与训练策略。
- 我们的方法
- 建立在基于 Transformer 的 HOI 检测策略上,专注于提高交互识别。
视觉语言模型的开发
- 视觉语言模型的突破证明了其在下游人物的迁移能力。从自然语言监督中学到的视觉表示为零样本和开放式词汇任务铺平了道路。
- 先前的工作将 VLM 通过知识蒸馏的方式迁移到开放式物体检测中
- 受上述的启发,最近的研究将相同的策略应用到了 HOI 检测中,可以总结成两个方面:
- 通过文本整合先验知识,利用 CLIP 中的标签文本嵌入初始化分类器。
- 特征或逻辑层级的知识蒸馏,引导学习到的特征和 CLIP 嵌入的图像特征对齐
- 我们提出一种将 VLM 知识迁移到 HOI 检测任务的新策略,与上述方法不同的是:
- 不直接从 CLIP 中检索相关信息,具有更优越的性能和更高的数据效率。
零样本 HOI 检测
- 零样本 HOI 检测的目标:检测并识别训练数据中不存在的 HOI 类别
- 重要性:
- 由于 HOI 的组合型,实现所有可能的 HOI 组合的注释是不切实际的(A 人物和 B 物体…)
- 因此,零样本 HOI 检测设置对于实际场景中的应用非常重要
- 以前的方法:
- 组合的方式解决挑战,在训练的过程中解缠对动作和物体的推理(解开动作和物体之间的关系,独立开,因为训练数据可能是只有 A 人物和 B 物体和 C 动作,所以就不可能识别出来 A 人物和 A 物体和 A 动作这么一个组合),这使得在推理过程中识别看不见的(人、物体、动词)组合成为可能。
- 由于 VLM 的突破,最近的研究聚焦于迁移 VLM 的知识用于识别看不见的 HOI 概念,并在零样本的设置上实现有希望的性能增益
- 我们的工作旨在探索一种更有效的多方面策略,用于零样本 HOI 中 VLM 的知识转移。
方法
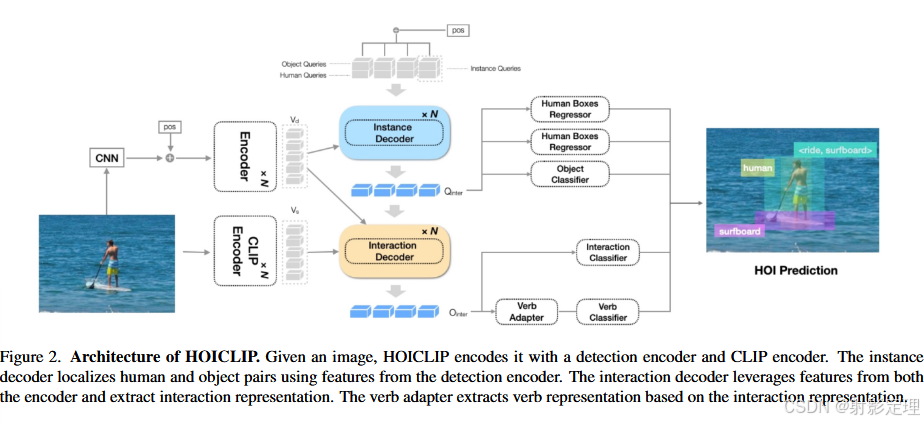
整体架构
-
首先采用基于 transformer 的端到端物体检测器来定位人和物:
- 对于输入图像 I,用 transformer 编码器获得空间图像特征图 V d V_d Vd,然后使用实例解码器和交互解码器完成实例检测和交互识别。
- 受 GEN-VLKT 的启发,实力解码器接受两组查询分别作为人和对象的输入,即人类查询 Q h Q_h Qh 和对象查询 Q o Q_o Qo
- 最后一个解码器层中的输出对象查询
O
o
O_o
Oo 和人类查询
O
h
O_h
Oh 用来预测人物的 bounding box
B
h
B_h
Bh、对象的 bounding box
B
o
B_o
Bo、对象的类别
C
o
C_o
Co
![![[IMAGE_007]]](https://i-blog.csdnimg.cn/direct/521428c8cc0244fe9004e7073fc88b7d.png)
-
对于给定的人和物体特征,我们引入一种全新的交互解码器来执行交互式别:
- 我们利用前面提取的特征图 V d V_d Vd 和 CLIP 生成的空间特征图 V s V_s Vs,并且通过交叉注意力模块实现知识整合
- 动词适配器提取动作信息并增强交互表示和识别
- 线性分类器用交互检测器的输出来预测 HOI 类别,并通过 CLIP 的语义特征的免训练分类器进一步增强
基于查询的知识检索
零样本 CLIP
-
CLIP 通过视觉编码器和文本编码器提取了双模态特征
-
视觉编码器由主干网络 VisEnc 和投影层 Proj 组成
-
视觉主干网络提取视觉空间特征 V s ∈ R H s ∗ W s ∗ C s V_s \in R^{H_s * W_s * C_s} Vs∈RHs∗Ws∗Cs ,并将其输入到投影层中得到全局视觉特征 V g ∈ R D V_g \in R^D Vg∈RD
-
文本编码器 TextEnc 为每个类别提取全局文本表示 T g ∈ R D ∗ K T_g \in R{D * K} Tg∈RD∗K 分类 S ∈ R K S \in R^K S∈RK 计算如下:
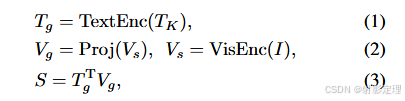
-
其中 T g T_g Tg 和 V g V_g Vg 是 L 2 归一化特征, T K T_K TK 是描述 K 类别的句子。矩阵乘法计算余弦相似度
具有知识集成的交互解码器
-
为了预测一对人类和物体查询的 HOI 类别,我们通过输入人和物体特征 O h O_h Oh 和 O o O_o Oo 到投影层生成一组交互查询 Q i n t e r ∈ R N q ∗ C s Q_{inter} \in R^{N_q * C_s} Qinter∈RNq∗Cs
-
为了充分利用 CLIP 知识,我们提出从CLIP 中检索交互特征,以更好的和分类器权重中的先验知识对齐
- 具体来说,我们保留 CLIP 空间特征
V
s
V_s
Vs 并将检测视觉特征
V
d
V_d
Vd 投影到与
V
s
V_s
Vs 相同的维度:
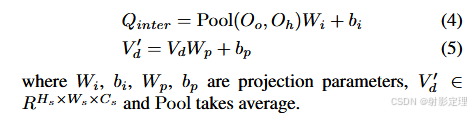
- 具体来说,我们保留 CLIP 空间特征
V
s
V_s
Vs 并将检测视觉特征
V
d
V_d
Vd 投影到与
V
s
V_s
Vs 相同的维度:
-
为了引导 A 交互查询 Q i n t e r ∈ R N q ∗ C s Q_{inter}\in R^{N_q * C_s} Qinter∈RNq∗Cs 探索 V s V_s Vs 和 V d V_d Vd 中的信息区域,我们设计了一个交叉注意力模块如图 3 所示。
- Q i n t e r Q_{inter} Qinter 首先通过自注意力机制更新
- 然后分别输入到带有 V s V_s Vs 和 V d ′ V_d^{'} Vd′ 的交叉注意力机制中并得到两个输出特征
- 最后将两个输出相加并送入到前馈网络
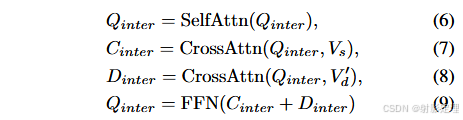
-
为了提取最终的交互表示 O i n t e r ∈ R N q ∗ D O_{inter}\in R^{N_q * D} Ointer∈RNq∗D ,我们采用与 CLIP 相同的投影操作并将交叉注意力的输出转换到 CLIP 的特征空间
-
通过这种方式,我们利用实例解码器中的对象和人类信息从 CLIP 的空间特征图中检索交互表示,并从检测其中检索特征特征,这种基于查询的知识检索涉及使我们能够实现高效的表示学习和强大的泛化能力
动词类型表示
视觉语义算法
-
为了更好的从自然不平衡的 HOI 注解中捕捉细粒度的动词关系,我们通过视觉语义算法构建了一个动词分类器,它代表了数据集的全局动词分布。我们假设动词类别表示可以从 HOI 的全局视觉特征和其对象的全局视觉特征的差别中推导出来
-
![![[IMAGE_011]]](https://i-blog.csdnimg.cn/direct/fd22411d3a61452ea8d671a5da5bea98.png)
-
具体来说,我们使用最小的区域覆盖对象和人梯的边界框来表示 HOI 三元组,然后我们将 O B J j OBJ_j OBJj 定义为一组包含所有 j 类别的所有实例的集合。
-
使用元组 (i, j)来表示 HOI 类别,i 和 j 分别表示动词和宾语的类别。类似的,将 HOI(i, j)定义为一组包含所有 HOI 类别(i, j)的所有实例的集合。
-
对于 HOI 和对象区域,我们使用 CLIP 图像编码器来获得他们的视觉特征,然后应用投影将特征映射到全局特征空间。如下公式所示:
-
动词类别 k 的表示可以通过平均 HOI 和物体区域特征的差异来计算:
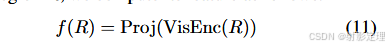

动词适配器
- 为了使用动词类别表示进行分类,我们设计了一个轻量的适配器模块来基于交互特征
O
i
n
t
e
r
O_{inter}
Ointer 来提取动词特征
O
v
e
r
b
∈
R
N
q
∗
D
O_{verb}\in R^{N_q * D}
Overb∈RNq∗D
-
具体来说,使用 MLP 将交互特征映射为动词特征 O v e r b ∈ R N q ∗ D O_{verb} \in R^{N_q * D} Overb∈RNq∗D,并计算动词类别分数如下:
-

-
通过这种方式,我们利用 CLIP 视觉编码器中的先验知识从训练数据中提取动词分类器并设计动词适配器来更好的表达动词。
-
该设计生成细粒度的动词信息,有利于 HOI 预测
-
零样本 HOI 增强
- 最后,我们引入 CLIP 文本编码器中的先验知识生成的 HOI 分类器,为 HOI 分类提供了免训练的增强
-
我们通过利用 CLIP 学习到的语言是绝对起构建了一个零样本 HOI 分类器,其中通过 CLIP 文本编码器 TextEnc 嵌入的标签用来作为分类器权重
-
我们将没一个 HOI 类别转换到手工制作模板的句子"a photo of a person [verb-ing] a [object]"。这个模板会被送入 CLIP 文本编码器 TextEnc 中得到 HOI 分类器 E i n t e r ∈ R K h ∗ D E_{inter}\in R^{K_h * D} Einter∈RKh∗D,其中 K h K_h Kh 是 HOI 类别的数量
-
为了利用零样本 CLIP 知识,我们根据图像的全局视觉特征 V g V_g Vg 和 HOI 分类器 E i n t e r E_{inter} Einter 计算了一组额外 HOI 逻辑。为了过滤掉低置信预测,我们仅仅保留最高的 K 个分数
-
更新后的 S z s S_{zs} Szs 是一种高置信度的免训练 HOI 预测,利用零样本 CLIP 只是有利于尾类预测
-
给定零样本分类器 E i n t e r E_{inter} Einter ,我们还使用它根据 3.2 节中计算的交互表示 O i n t e r O_{inter} Ointer 计算交互分数,它将与其他两个分类分数相结合
-

推理和训练
训练
-
训练过程中,结合 HOI 预测结果 S i n t e r S_{inter} Sinter 和动词预测结果 S v S_v Sv,我们能得到训练 HOI 逻辑 S t S_t St
-
对于二分匹配过程,我们遵循之前基于 DETR 框架的 HOI 检测器,并使用匈牙利算法将真实值分配给预测
-
匹配成本包括人和物体边界框回归损失、物体分类损失、交互联合损失和 HOI 分类损失。腐竹损失用于解码器层的中间输出
![![[IMAGE_016]]](https://i-blog.csdnimg.cn/direct/cb241e51e36144a3a9d7dc7edda56fc6.png)
推理
-
零样本 HOI 预测结果 S z s S_{zs} Szs ,最终的 HOI 逻辑 S i S_i Si 的计算公式:
-
根据之前的方法,我们使用来自实例解码器的对象分数 C o C_o Co 来计算 HOI 三元组分数:
-
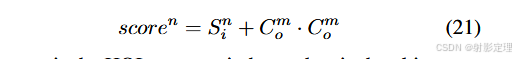
-
N 是 HOI 类别索引,m 是第 n 个 HOI 类别对应的对象类别索引
-
-
最后,根据置信度得分,将三元组 NMS 应用于最高分的 k 个 HOI 三元组
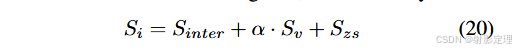

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









