







1.本次实验使用的是威斯康辛州乳腺癌数据集(原件)。
数据来源UCI:
http://archive.ics.uci.edu/dataset/15/breast+cancer+wisconsin+original
2.加载、查看、预处理数据集
import pandas as pd
# 从csv文件中加载数据
data = pd.read_csv('wisconsin.csv')
# 删除不需要的特征
data = data.drop(["id"], axis=1)
# 将列的值替换为平均值
data['Bare Nuclei'] = pd.to_numeric(data['Bare Nuclei'], errors='coerce')
data['Bare Nuclei'] = data['Bare Nuclei'].fillna(data['Bare Nuclei'].mean())
# 查看数据的详细信息
data.info()
print(data)输出结果:
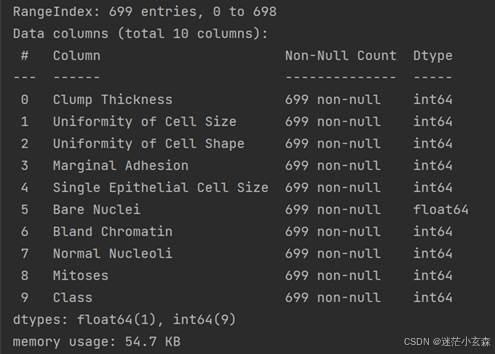
数据处理
#将列的coerce值替换为平均值
# 从csv文件中加载数据
data = pd.read_csv('wisconsin.csv')
# 删除不需要的特征
data = data.drop(["id"], axis=1)
# 将列的值替换为平均值
data['Bare Nuclei'] = pd.to_numeric(data['Bare Nuclei'], errors='coerce')
data['Bare Nuclei'] = data['Bare Nuclei'].fillna(data['Bare Nuclei'].mean())
# 将数据分割为特征和目标变量
X = data.drop('Class', axis=1)
y = data['Class']
# 数据预处理:标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)3 决策树与随机森林
3.1决策树
3.1.1 模型建立与优化
使用决策树默认参数,全部列作为特征时
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载数据集,将'?'替换为NaN
dataset = pd.read_csv('wisconsin.csv', na_values='?')
# 处理缺失值,假设使用均值填充
dataset['Bare Nuclei'].fillna(dataset['Bare Nuclei'].mean(), inplace=True)
# 划分特征和目标变量
X = dataset.drop('Class', axis=1)
y = dataset['Class']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建决策树模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X_train, y_train)
# 在训练集上进行预测
y_train_pred = model.predict(X_train)
# 在测试集上进行预测
y_test_pred = model.predict(X_test)
# 计算训练集和测试集上的准确率
accuracy_train = accuracy_score(y_train, y_train_pred)
accuracy_test = accuracy_score(y_test, y_test_pred)
print(f'Training Accuracy: {accuracy_train}')
print(f'Testing Accuracy: {accuracy_test}')输出结果如下
![]()
看上去模型在训练集上表现良好,在未见过的测试数据上表现也不错,为了保证使用默认参数的决策树没有过拟合现象,加上测试每个特征重要程度的代码,进行特征提取后再训练,因为考虑过多特征容易导致模型过拟合,所以要进行特征提取。
使用互信息方法进行特征提取
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.feature_selection import mutual_info_classif
# 加载数据集,将'?'替换为NaN
dataset = pd.read_csv('wisconsin.csv', na_values='?')
# 处理缺失值,假设使用均值填充
dataset['Bare Nuclei'].fillna(dataset['Bare Nuclei'].mean(), inplace=True)
# 划分特征和目标变量
X = dataset[['Clump Thickness',
'Uniformity of Cell Size',
'Uniformity of Cell Shape',
'Marginal Adhesion',
'Single Epithelial Cell Size',
'Bare Nuclei',
'Bland Chromatin',
'Normal Nucleoli'
]]
y = dataset['Class']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 计算互信息
mi = mutual_info_classif(X, y)
# 选择互信息较高的特征
selected_features = X.columns[mi.argsort()[::-1][:5]]
print('选择作为特征的列:', selected_features)
print('特征数:',len(selected_features) )
# 构建决策树模型,使用选择的特征
model = DecisionTreeClassifier()
model.fit(X_train[selected_features], y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test[selected_features])
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')输出结果如下



可以看到,特征数为5的时候准确率比4和6高,可以认为5的时候是一个峰值,故选择5
但此时准确率只有0.94,不如一开始的默认参数,即使用默认参数的决策树(以全部列作为特征)
下面进行调参,使用网格搜索找最佳参数
# 设置参数网格
param_grid = {
'max_depth': [3, 5, 7, None],
'min_samples_split': [2, 5, 10]
}
# 使用网格搜索
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# 输出最佳参数
print('最佳参数:', grid_search.best_params_)
# 在测试集上进行预测
y_test_pred = grid_search.best_estimator_.predict(X_test)
# 计算测试集上的准确率
accuracy_test = accuracy_score(y_test, y_test_pred)
print(f'优化后的模型在测试集上的准确率: {accuracy_test}')输出结果如下:
![]()
可以看到相比一开始默认参数的0.964准确率,现在的准确率有所提高,达到0.9714
尝试其他优化方法
标准化
# 使用StandardScaler进行标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)![]()
归一化
# 使用MinMaxScaler进行归一化
scaler = MinMaxScaler()
X_train_normalized = scaler.fit_transform(X_train)
X_test_normalized = scaler.transform(X_test)![]()
多次调整训练集和测试集的比例
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
![]()
都没有一开始的模型好,认为0.971已经是最好的模型结果了
3.1.2 模型评估
决策树ROC和AUC评价模型性能
# 计算 ROC 曲线和 AUC
y_prob = grid_search.best_estimator_.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
auc = roc_auc_score(y_test, y_prob)
plt.rcParams['font.sans-serif']=['simhei']
# 绘制 ROC 曲线
plt.figure(figsize=(8, 8))
plt.plot(fpr, tpr, label=f'Decision Tree (AUC = {auc:.2f})')
plt.plot([0, 1], [0, 1], linestyle='--', color='gray', label='Random Guess')
plt.xlabel('假正例率')
plt.ylabel('真正例率')
plt.title('ROC Curve')
plt.legend()
plt.show()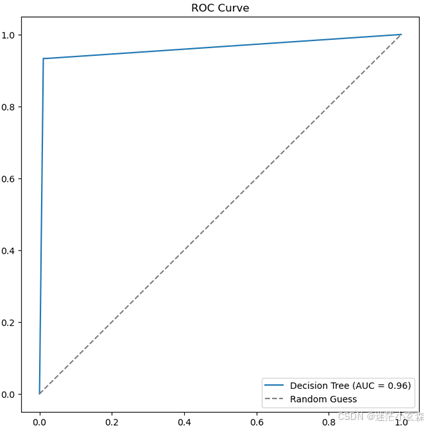
可以看见AUC指标为0.96,认为模型性能较优,可能是因为数据集数量较少,所以简单的模型拟合效果更好,数据特征量不大数据较为简单,故模型准确率始终处于较高水平
学习曲线查看模型过拟合情况
# 绘制学习曲线图
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=None, train_sizes=np.linspace(0.1, 1.0, 10)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("训练样本比例")
plt.ylabel("得分")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, scoring='accuracy')
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b",
label="训练集得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="验证集得分")
plt.legend(loc="best")
return plt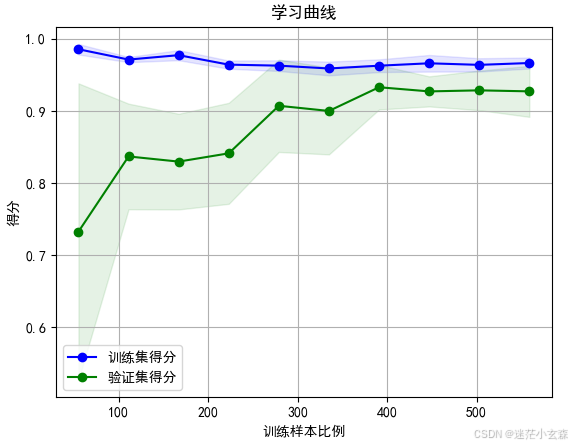
可以看到决策树的学习曲线中,训练集和验证集曲线趋于收敛,且收敛于0.95左右的较高水平,即模型在训练集和验证集的得分都比较高,且最后两者的得分差别不超过0.05,认为模型不存在过拟合现象
3.2随机森林
下面使用随机森林,方法步骤同上,同样是默认参数的效果最好,下面是最佳模型的结果
# 构建随机森林模型
model = RandomForestClassifier()
# 设置参数网格
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [3, 5, 7, None],
'min_samples_split': [2, 5, 10]
}输出结果如下
![]()
随机森林ROC和AUC评价模型性能
# 计算 ROC 曲线和 AUC
y_prob = grid_search.best_estimator_.predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
auc = roc_auc_score(y_test, y_prob)
# 绘制 ROC 曲线
plt.figure(figsize=(8, 8))
plt.plot(fpr, tpr, label=f'Random Forest (AUC = {auc:.2f})')
plt.plot([0, 1], [0, 1], linestyle='--', color='gray', label='Random Guess')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend()
plt.show()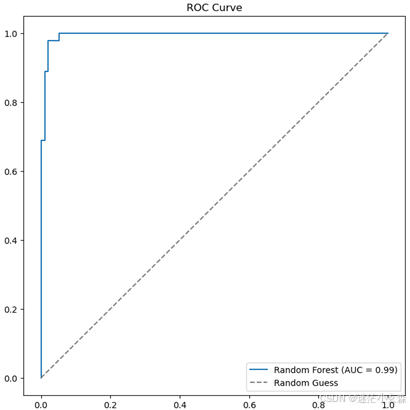
可以看见AUC指标为0.99,非常高,出现原因同上决策树一样,可能是数据量较少模型性能比较强大,不需要太复杂的模型也能拟合出好的结果
学习曲线查看模型过拟合情况
# 绘制学习曲线图的函数
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=None, train_sizes=np.linspace(0.1, 1, 10)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("训练样本比例")
plt.ylabel("得分")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, scoring='accuracy')
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="b")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="b",
label="训练集得分")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="验证集得分")
plt.legend(loc="best")
return plt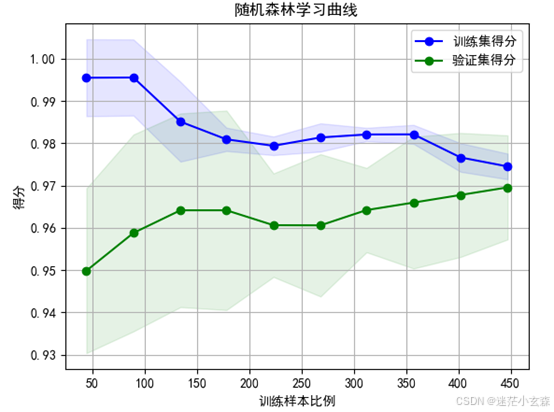
训练集和验证集曲线趋于收敛,且收敛于0.97左右的较高水平,即模型在训练集和验证集的得分都比较高,且最后两者的得分差别不超过0.05,认为模型不存在过拟合现象
3.3 小结
从准确率看,决策树为:0.9714285714285714 随机森林为:0.9785714285714285
随机森林优于决策树
现在看决策树和随机森林的ROC和AUC,比较两个模型
决策树
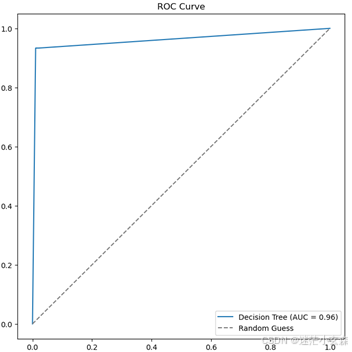
随机森林
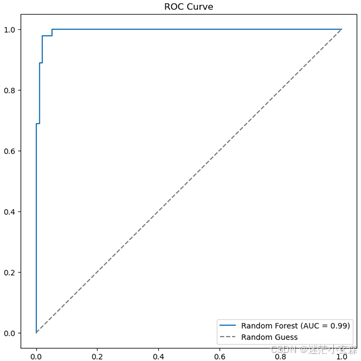
随机森林auc为0.99,决策树为0.96,认为随机森林优于决策树
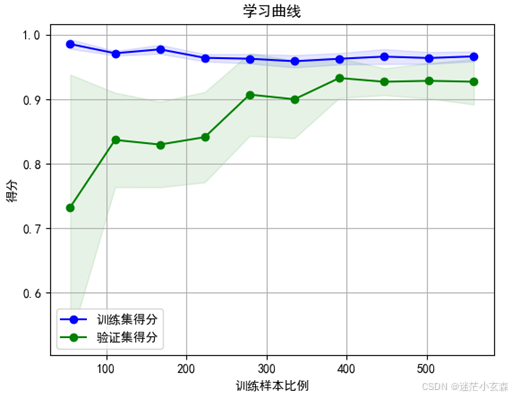
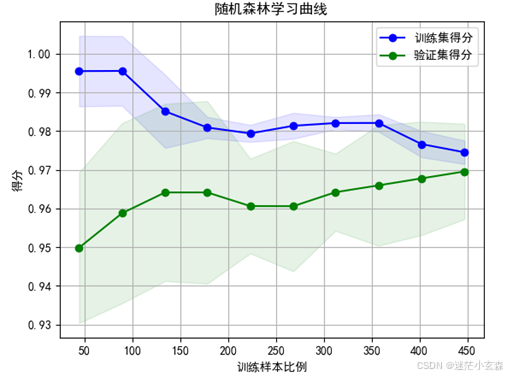
从学习曲线上看,上图为决策树,下图为随机森林的。从收敛速度上看,决策树的收敛速度较慢,大约300训练样本时模型的训练集和验证集得分才趋于稳定,而随机森林的大约170次就趋于稳定收敛了。从波动程度来看,两者均存在微小的波动情况,但是决策树初始验证集得分为0.75,随机森林却能达到0.95。可以认为决策树的优化速度更快,但最终的优化结果不如随机森林,即随机森林性能更优。综上在本项目中随机森林的准确率和性能更好,但模型也更为复杂,训练速度较慢,最终与决策树的模型准确率相差也非常小(<0.01),如果不追求极致的高准确率,使用决策树是一种比较平衡的选择。


















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









