







 本文介绍了XGBoost,一种基于GBDT的强化算法,通过二阶泰勒展开和正则化防止过拟合。重点讲解了如何与scikit-learn集成,关键参数如max_depth、learning_rate等的调优策略,以及在竞赛中的应用技巧。
本文介绍了XGBoost,一种基于GBDT的强化算法,通过二阶泰勒展开和正则化防止过拟合。重点讲解了如何与scikit-learn集成,关键参数如max_depth、learning_rate等的调优策略,以及在竞赛中的应用技巧。
一、XGBoost是什么
XGBoost是基于GBDT实现的,但GBDT算法只利用了一阶的导数信息,xgboost对损失函数做了二阶的泰勒展开,并在目标函数之外加入了正则项对整体求最优解,用以权衡目标函数的下降和模型的复杂程度,避免过拟合。
同时XGBoost在许多竞赛上有着非常好的表现
二、XGBboost与scikit-learn结合使用、
XGBoost提供一个wrapper类,允许模型可以和scikit-learn框架中其他分类器和回归器一样对待
XGBoost中的分类器为XGBClassifier
三、sklearn中XGBClassifier参数

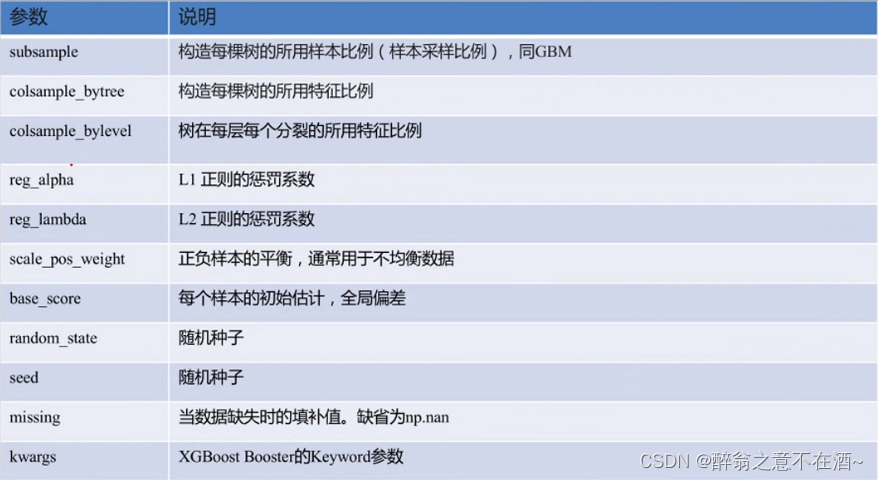
一般需要调的参数有max_depth、learning_rate、n_estimators、reg_alpha、reg_lambda、subsample、colsample_bytree、colsample_bylevel
不需要调的参数(通用参数):booster、slient、nthread
1、booster:弱学习器类型
--可选gbtree(树模型)或gbliner(线性模型)
--默认为gbtree(树模型为非线性模型能更好的处理复杂问题)
2、slient:是否开启静默模式
--1:静默模式开启不输出任何信息
--0:默认值,输出一些中间信息,以助于我们了解模型的状态
3、nthread:线程数
--默认为-1,表示使用系统所有cpu核
对于调参的建议:
--可以设置较小的学习率,然后用交叉验证确定n_estimators
--行(subsample)、列(colsample_bytree、colsample_bylevel)下采样比例,默认值为1,即不进行下采样,建议值:0.3-0.8,加强泛化能力。
--数的最大深度(max_depth):默认为6,建议3-10
竞赛大佬建议:三个最重要的参数为:树的数目、树的深度、学习率,调整策略:
--采用默认参数试一试
--如果系统过拟合,降低学习率
--如果系统欠拟合,加大学习率



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











