







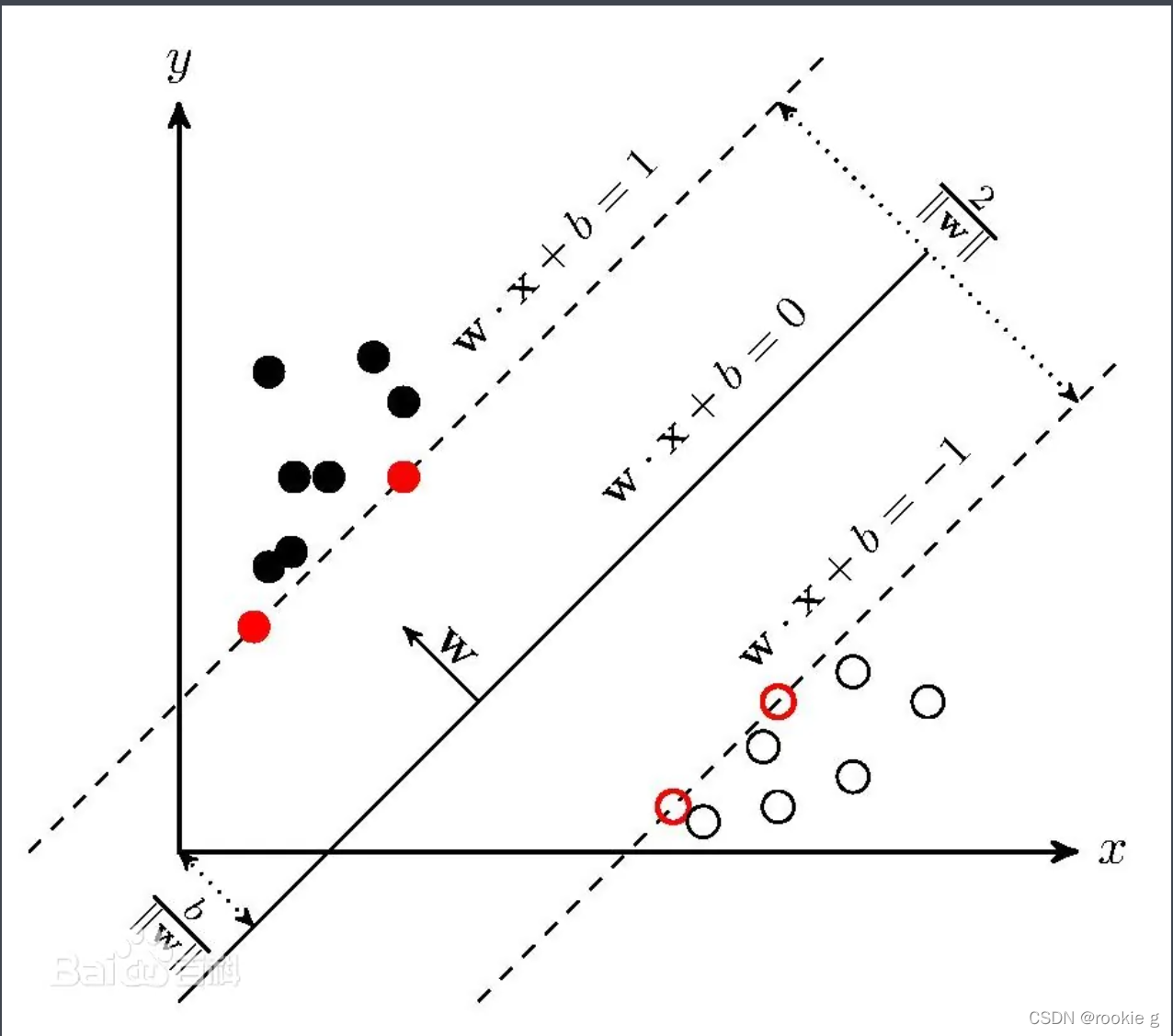
 本文深入探讨支持向量机(SVM)的基础概念,包括超平面的公式推导、最大间隔的优化以及如何寻找最优超平面。通过数学公式和几何解释,阐述了硬间隔情况下的SVM模型,指出支持向量在模型中的关键作用。
本文深入探讨支持向量机(SVM)的基础概念,包括超平面的公式推导、最大间隔的优化以及如何寻找最优超平面。通过数学公式和几何解释,阐述了硬间隔情况下的SVM模型,指出支持向量在模型中的关键作用。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包


 1094
710
482
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
1094
710
482
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






