






1. 基于用户的协同过滤(User-based Collaborative Filtering)
该方法通过计算用户之间的相似性来推荐物品。例如,假设用户A和用户B在过去的行为中有相似的偏好,那么我们可以推荐用户A没有看过但用户B喜欢的物品。
计算方式:
-
皮尔逊相关系数(Pearson Correlation):衡量两个用户评分行为的线性关系。公式如下:
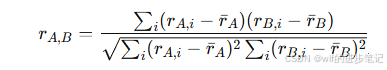
其中,rA,ir_{A,i}rA,i 和 rB,ir_{B,i}rB,i 是用户A和B对物品i的评分,rˉA\bar{r}_ArˉA 和 rˉB\bar{r}_BrˉB 是用户A和B的评分均值
-
余弦相似度(Cosine Similarity):通过计算用户评分向量之间的夹角来衡量相似性。公式如下:
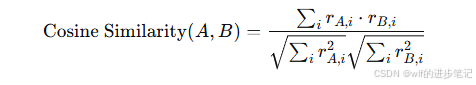
这种方法忽略评分的绝对值,关注评分的方向性。
2. 基于物品的协同过滤(Item-based Collaborative Filtering)
该方法计算物品之间的相似性,如果用户喜欢某个物品,系统会推荐与该物品相似的其他物品。
计算方式:
-
余弦相似度(Cosine Similarity):物品之间也可以通过余弦相似度来计算,相当于用户之间的计算方式,公式如下:
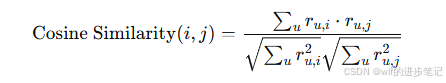
其中,ru,ir_{u,i}ru,i 是用户u对物品i的评分,ru,jr_{u,j}ru,j 是用户u对物品j的评分。
3. 基于内容的推荐(Content-based Filtering)
基于物品的特征来计算相似度。例如,对于电影推荐,可以根据电影的类型、导演、演员等特征来计算相似度。
计算方式:
-
余弦相似度:如果每个物品都表示为一个特征向量,可以使用余弦相似度来计算两个物品之间的相似度。
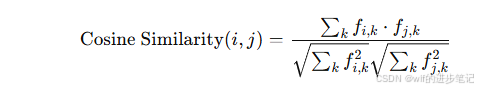
其中,fi,kf_{i,k}fi,k 和 fj,kf_{j,k}fj,k 是物品i和物品j在特征k上的值。
4. 基于模型的推荐(Model-based Filtering)
该方法使用机器学习模型(如矩阵分解)来发现隐藏在用户和物品之间的潜在因素。例如,使用**奇异值分解(SVD)**来降低维度,进而计算用户和物品之间的相似性。
计算方式:
-
矩阵分解:通过将用户-物品评分矩阵分解为两个低维矩阵,得到用户和物品的潜在特征向量,再通过计算这些潜在向量的相似性来进行推荐。
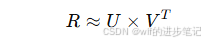
其中,RRR是评分矩阵,UUU和VVV是用户和物品的潜在特征矩阵。
5. 基于邻域的推荐(Neighborhood-based Filtering)
邻域方法使用用户或物品的相似度来构建一个“邻居”,然后推荐邻居的行为。这个方法是协同过滤的基本思想。
6. 基于深度学习的推荐(Deep Learning-based)
使用神经网络模型来学习用户和物品之间的复杂关系,例如通过**神经协同过滤(Neural Collaborative Filtering, NCF)**模型来预测评分。

















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









