







 本文提出了一种基于Adaboost的视频文本定位方法,通过灰度处理和Sobel算子边缘检测提取文本区域。利用5种特征构建CART弱分类器,并通过Adaboost构建强分类器,实现对不同字体、大小和颜色文本的准确定位。实验结果显示,该方法在精度和效率上优于支持向量机(SVM)。
本文提出了一种基于Adaboost的视频文本定位方法,通过灰度处理和Sobel算子边缘检测提取文本区域。利用5种特征构建CART弱分类器,并通过Adaboost构建强分类器,实现对不同字体、大小和颜色文本的准确定位。实验结果显示,该方法在精度和效率上优于支持向量机(SVM)。
目录
2.The candidate TEXT areas detection(检测候选文本区域)
3.Design of video text localization based ON Adaboost
3.2 Features extractions(特征提取)
3.3 Construction of strong classifier based on Adaboost
4. Experimental results and analysis
4.2 Edge detection result(边缘检测)
4.3 The construction of database
4.4 Text localization experiment result and analysis
写在前面:
知识补充:
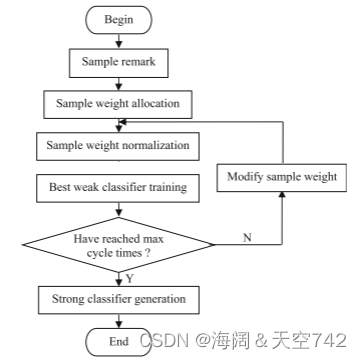
AdaBoost是Adaptive Boosting(自适应增强)的缩写,它的自适应在于:被前一个基本分类器误分类的样本的权值会增大,而正确分类的样本的权值会减小,并再次用来训练下一个基本分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或预先指定的最大迭代次数再确定最后的强分类器。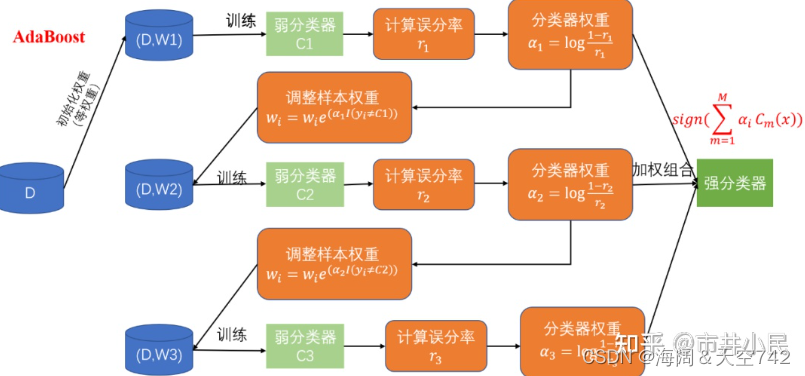
从上图来看,AdaBoost算法可以简化为3个步骤:
首先,是初始化训练数据的权值分布D1。假设有N个训练样本数据,则每一个训练样本最开始时,都会被赋予相同的权值:w1 = 1/N。
训练弱分类器Ci。具体训练过程:如果某个训练样本点,被弱分类器Ci准确地分类,那么再构造下一个训练集中,它对应的权值要减小;相反,如果某个训练样本点被错误分类,那么它的权值就应该增大。权值的更新过的样本被用于训练下一个弱分类器,整个过程如此迭代下去。
最后,将各个训练得到的弱分类器组合成一个强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。
换而言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
0.Abstract
视频文本定位是监控系统、自动导航系统、基于内容的图像分析系统等视频文本识别系统中的重要环节。因此,如何从视频图像中准确、快速地提取文本是十分必要的。本文提出了一种基于Adaboost 的视频文本定位方法。首先,利用基于梯度特征的 Sobel 算子进行边缘检测,提取图像中的文本区域;通过对视频图像区域特征的分析,提取出 5 种特征,形成 5 个弱分类器,然后对这些特征进行分类,利用 CART (Classification And Regression Tree)构造Adaboost 强分类器,并将候选文本区域发送给该分类器,得到正确的文本区域检测结果。实验结果表明,该方法不仅能对不同字体、大小和颜色的视频图像中的文本实现良好的定位效果,而且能快速、准确地实现满足视频文本定位要求的文本。
1.Introduction
随着计算机技术的飞速发展,数字图像处理也在不断的更新换代。越来越多的技术,如可视电话和智能交通系统融入世界。视频图像中的文本信息对图像的分类、识别和理解起着重要的作用。视频文本识别主要包括两个步骤。第一步是定位视频图像中的文本区域。其次,将文本从图像中提取出来后,送入 OCR或其他文本识别系统。因此,如何准确、快速地从视频中提取文本内容成为研究人员研究的热点问题。
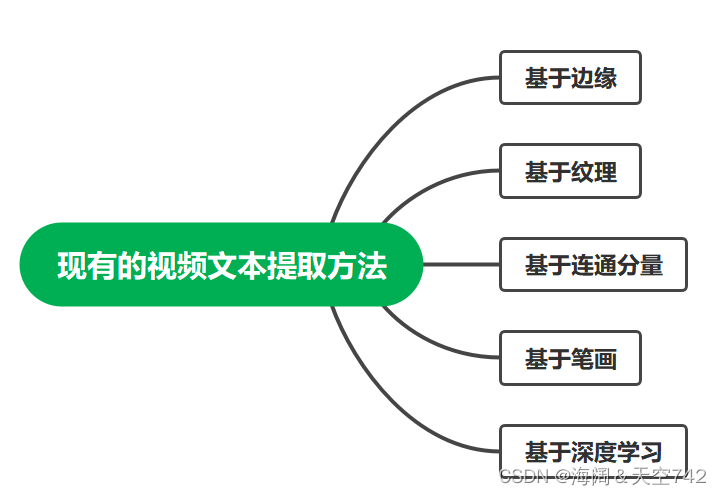
目前,视频文本提取方法大致可以分为基于边缘、纹理、连通分量、笔画和深度学习等六种算法。Cho提出了一种基于 Canny 算子的场景文本检测算法,考虑到图像边缘与文本的相似性,采用双阈值和滞后跟踪对文本进行检测。但在阴影和光照的影响下,很难提取出满意的边缘轮廓。Zhao采用稀疏表示模型进行纹理分割和特征提取,对图像进行小波变换,边缘检测后利用滑动窗口将图像分割成小块。利用纹理特征可以准确定位文本,但算法运行缓慢,对文本的对齐和方向很敏感。Hua通过检测高对比度视频帧中的 b统一颜色块来定位文本区域。然而,颜色并不是一个稳定的特征。当字符的颜色与背景颜色相似时,很难区分目标。因此,该方法鲁棒性差,不适合处理复杂背景的图像。SWT (stroke width transform)与适当的学习方法相结合,在参考文献[14]中获得了良好的性能。但背景复杂时,容易产生错误的结果。
上述方法的问题:以上方法可以在一定程度上定位视频中的文本,但当视频分辨率较低、背景复杂或文本的颜色、大小、字体变化时,很难获得满意的结果。
启发与动机:基于Adaboost 的学习方法在人体器官识别的应用中得到了广泛的应用。近年来,许多研究者将其应用于文本识别,并取得了良好的效果。例如 Chen 和 Yuille使用Adaboost 学习X和Y导数、灰度直方图和连接边缘的特征来定位文本。
2.The candidate TEXT areas detection(检测候选文本区域)
候选区域检测的主要任务是提取包括文本区域和非文本区域在内的连通区域。通过Adaboost 将这些连接的区域发送到强分类器中,以剔除非文本区域,从而提取出正确的文本区域。
2.1 Gray processing(灰度处理)
在本文中彩色图像通过参考文献[11]的方法转换为灰度图像。由于 RGB图像的每个像素由 R,G, B三个分量组成,每个像素的每个分量的取值范围为 0~255 * 255 * 255。而灰度图像中每个像素的取值范围仅为 0 ~ 255。因此,对RGB视频图像进行灰度处理后,后续图像处理的计算量减少。
目前的灰度处理方法有以下几种。
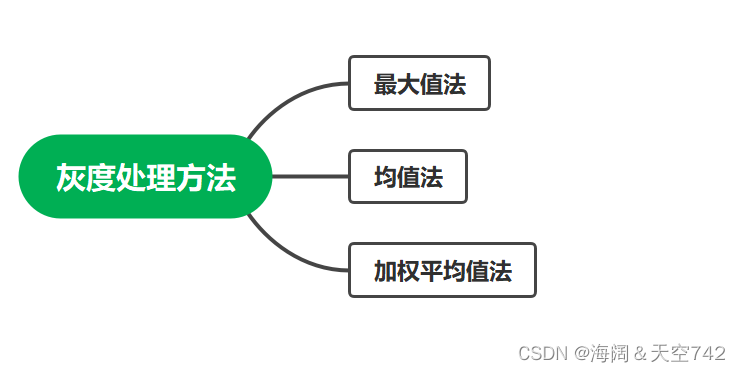
然而,用最大值法和均值法处理灰度图像会使灰度图像的亮度变弱。因此本文采用加权平均
的方法对RGB视频图像进行处理。将每个像素的R、G、B分量加权后,得到三个分量的加权平均,如下式所示
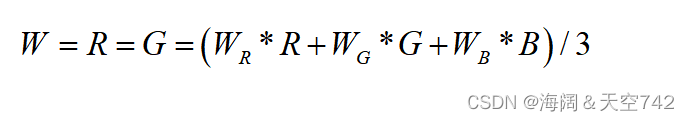
,
和
分别为R、G、B的加权值。根据先验知识,当
= 0.30,
= 0.11。
2.2 Edge detection(边缘检测)
视频文本多为叠加文本,其作用是为读者提供有关视频的信息,帮助读者理解视频。所以为了达到这一目的,视频文本与视频背景有明显的区别,视频背景易于观看。我们可以利用梯度特征得到边缘区域。基于图像梯度的边缘检测方法根据 X方向或Y方向滤波器的梯度估计不同而有不同的类型。如Roberts operater、Sobel operater、Prewitt operater等。本文通过实验比较,选择Sobel operater进行边缘提取。结果如图2所示。
3.Design of video text localization based ON Adaboost
完整算法主要分为三个阶段:预处理阶段、视频文本特征提取阶段和基于Adaboost 构建CART的强分类器阶段。
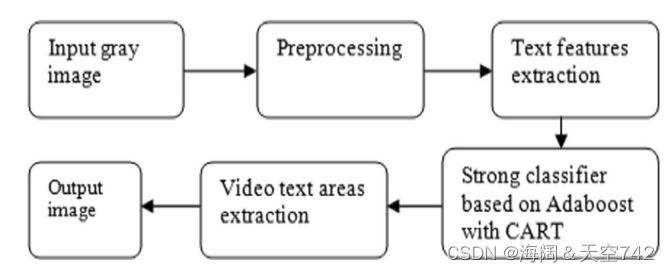
Adaboost算法流程图如下
3.1 Preprocessing(预处理)
由于视频类型和视频播放工具的不同,采集到的视频图像大小不同。因此,我们的视频文本定位系统将不同尺寸的数字图像转换为统一的标准尺寸 64*32像素。首先,通过边界扫描得到视频图像的尺寸。然后利用差分算法将整个图像的大小调整为 64*32像素。因此,图像大小统一,由统一大小的图像训练的分类器具有较好的分类能力(数据归一化)。
3.2 Features extractions(特征提取)
Adaboost 通过组合弱分类器构造了一个强分类器。我们为CART弱分类器提取了5种类型的
视频文本特征集。
3.2.1 Gabor feature
在视频中,具有一定周期性的文本笔划特征非常丰富。所以我们可以把视频文本当作一种特
殊的纹理。我们可以用 Gabor 来提取这个纹理特征。本文采用二维 Gabor 滤波器对视频文本
进行分析,其函数定义如下式。
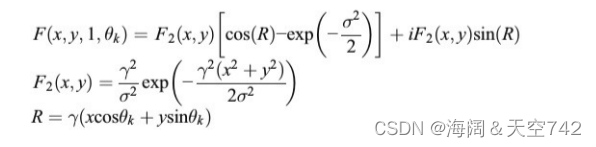
3.2.2 Connected domain analysis
Shilin Gao[3]利用连通域分析剔除非文本区域。本文通过对文本区域的分析来提取特征。
3.2.3 Stroke density(笔划密度)
文字由 π/4、π/2、3π/4和π这四个方向的笔画组成。文本笔画是一种双向结构,其宽度总是小于一定的限制。根据这一特点,笔画密度称为由式(3)(4)计算。
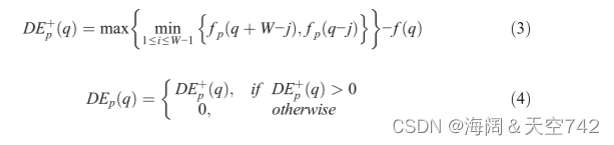
p= 0, 1, 2, 3 表示 π/4, π/2, 3π/4, π 四个方向。W是视频文本笔画的最大宽度。fp(q + j)是在方向。p 上距像素 q 距离为 j 的像素的灰度值。视频文本笔画密度特征称为为四个方向的最大值
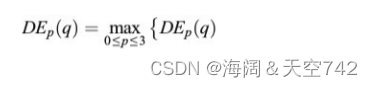
3.2.4 Statistical texture(统计性纹理)
统计纹理信息通常用于文本定位。这里使用四种统计纹理度量来区分文本区域和非文本区域。设 p(i, d, j, θ)为特征图像中像素(i, j)关于距离 d和方向θ的分离联合概率。将能量、熵、对比度、Inverse difference moment等四种统计纹理特征定义为式(6):
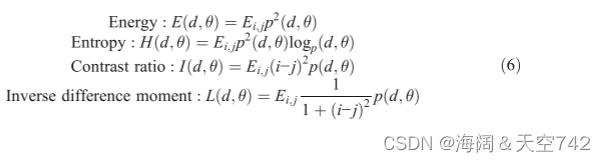
3.2.5 Variance and expectation ofXand Y derivatives(X和Y导数的方差和期望)
文献[1]中使用了基于X和Y导数的标准差和均值的特征提取文本特征。我们可以根据视频文本的X导数局部最大值,Y导数局部最小值来分割块区域。然后我们可以计算每个分离区域的方差和期望,从而得到一组特征。
提取了CART 弱分类器的 5 种视频文本特征Gabor 特征、连通域分析、笔画密度特征和统计纹理特征,并将弱分类器与Adaboost 相结合构造了一个强分类器。
3.3 Construction of strong classifier based on Adaboost
Adaboost 算法通过将多个弱分类器按照一定的方法组合,构造出具有较强分类能力的强分器。与其他机器学习算法相比,Adaboost 算法具有一些优点比如构造弱分类器比直接构造高精度强分类器更容易、不会过拟合、生成能力不会随着迭代次数的增加而降低。第四节给出Adaboost 的流程图。
我们利用非对称Adaboost 为文本样本和非文本样本分配适当的权重。将弱分类器重新定义为h j
由式(7)得到。

CART (Classification and Regression Trees)利用从1860个正样本和 8000个负样本中提取
的5组特征,构建了最大深度为 4的决策树。分支显示为真和假。利用这些训练样本构建
CART节点,并将其作为 Adaboost 的单个弱分类器。经过训练,我们得到了 Adaboost 的
强分类器。
4. Experimental results and analysis
4.1 Gray processing result
三种方法的实验结果如图 3 所示。从结果可以看出,图像(d)的亮度过高,图像(c)的亮度过软?,因此加权平均值法优于其他方法。

4.2 Edge detection result(边缘检测)
图3b的边缘检测分别采用Sobel 算子、Roberts 算子和Prewitt 算子进行,检测结果如图4所示。很明显,Sobel的作用比另外两个好。其主要原因是 Sobel 算子是一种离散微分算子。它可以更准确地计算出图像边缘方向的差值,具有原理简单、计算量小、运行速度快的特点。

4.3 The construction of database
由于目前还没有统一标准的视频文本数据库,我们自行构建了一个视频文本数据库来测试文本本地化的效果。我们从互联网上收集了 300个视频图像,包括新闻、电影、广告等。除了我们的视频图像数据库中有一些英文字符和数字外,大部分的文本都是中文的。而且大小、颜色、对比度和字体都不一样。我们从 300幅图像中选择200幅作为训练样本,将剩下的100幅图像作为测试样本进行测试。
| 训练集 | 测试集 |
| 200幅图像 | 100幅图像 |
我们使用精度(提取的文本区域的数量/提取的整个区域的数量)、召回率(提取的文本区域的数量/整个文本区域的数量)和 f (2*precision*recall / (precision + recall)),它是一个单一标量,是调和平均值作为性能指标。我们用 100个测试图像样本对 f进行比较,以阐明5个弱分类器的贡献,如下图所示。
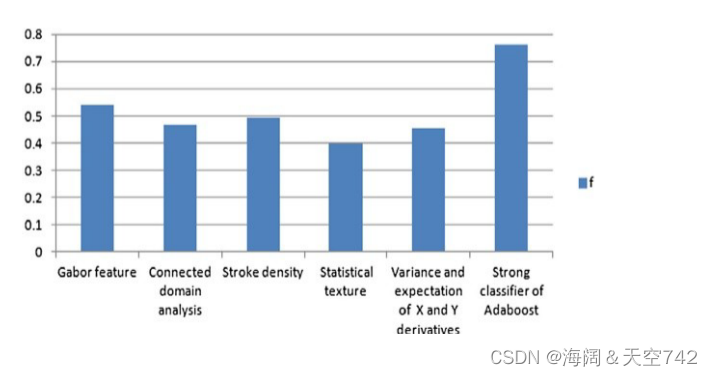
通过AdaBoost 将这些弱分类器组合在一起,尽管使用一组特征构建的分类器在图6中表现较弱,但总体上表现较强。
4.4 Text localization experiment result and analysis
我们使用相同的特征集和训练样本来训练 SVM(支持向量机),以证明我们的方法的优越性。为了比较它的性能,我们使用 SVM和我们的方法在相同的测试样本中定位文本区域。部分实验结果如图6所示,性能指标对比如表1所示。从表 1可以看出,本文方法的准确率和召回率都高于 SVM分类器。在实验过程中,我们发现在同一实验平台上,我们的方法比基于 SVM的方法具有更高的效率,正好满足了视频文本定位速度的特殊要求。
| Precision | Recall | |
| Adaboost | 0.761 | 0.740 |
| SVM | 0.682 | 0.636 |
5. Conclusion
针对视频文本识别中的关键环节文本定位问题,本文提出了一种基于 Adaboost 的视频文本定位方法,该方法将文本定位转化为二值分类问题。基于 Adaboost 的强分类器采用CART算法,由5种特征组成,提取文本区域。实验结果表明,该方法在精度、效率等方面都是令人满意的。下一步工作的主要重点是解决噪声干扰问题,提高系统的鲁棒性。
6.启发
1.定位问题可以转化为二分类问题。
2.随机森林与Adaboost两者均归属于集成学习算法,随机森林是Bagging方法,Adaboost是Boosting方法。是否可以采用随机森林算法实现文本定位,与本文Adaboost效果进行对比。对影响文本和非文本分类区域的Gabor 特征、连通域分析、笔画密度特征和统计纹理特征进行决策树建立,对输入向量进行"投票",随机森林按照所有树中少数服从多数树的分类值来决定因变量的预测值。进而得到最终的类型。而且随机森林采用Bagging各个预测函数可以并行生成,是否可以进一步提高视频文本定位的速度。
7.问题
1.Fig3的(c)图亮度too soft是什么意思?
2.本文中评价分类器性能指标 f (2*precision*recall / (precision + recall))是怎么提出的?

















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









