







关于d2l中multy-head-Attention代码实现的理解
2022/10/19:读了Transformer的原文,发现/num_of_head的实现没有问题
代码实现链接:https://zh-v2.d2l.ai/chapter_attention-mechanisms/multihead-attention.html
贴入其他评论区大佬整理的维度分析:
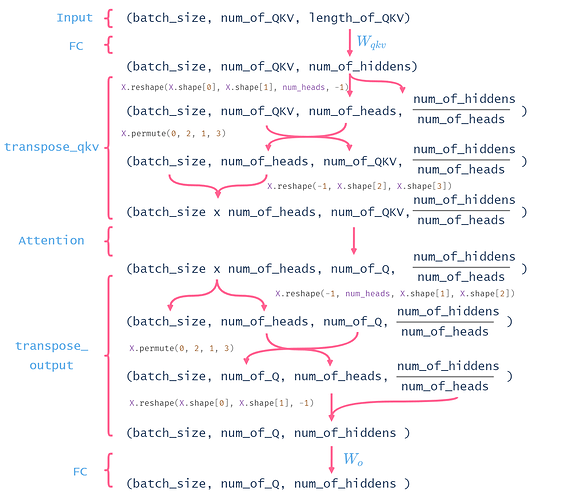
对encoder的多头注意力机制部分代码的理解:
难度主要来自为了做并行计算而对输入矩阵进行的各种维度变换。
这边多头注意力在transpose_qkv那边做的交换维度的操作主要目的是将计算中可并行的多个head“化作batch_size”和batch_size那个维度放在一起,使输入attention的维度变成(batch_sizehead,num_of_QKV,num_of_hiddens),放入d2l.DotProductAttention(dropout)(缩放点积注意力的实现)中去计算。点积注意力计算过程中是没有参数需要学习,所以可以将多个head需要做的计算当作数量为head的多个batch拆出来和原来的beath拼在一起计算,使得batch数量从原batch_size->batch_sizehead

















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









