







一、MR中的Counter计数器
计数器在MR中都是全局的,主要用于监控一些数据有无出入;
主要的:1、Map-Reduce FrameWork(主要是MR的输入输出等信息) 2、jobs
而如果说业务有需求,用户可以自定义计数器来统计程序执行过程中的某种情况的出现次数
自定义计数器的使用:
1、通过context.getCounter(group name,counter name)方法获取到一个全局计数器,创建的时候需要指定计数器所属的组名和计数器的名字
![]()
2、在需要用到计数器的地方进行计数器的操作
最常用的:给计数器增加指定的数值--------counter.increment(int num)
二、MR的DB操作--------对数据库的操作
1、读取mysql操作------------DBInputFormat类(这里以最简单的输出数据库信息到指定文件中为例)
Ⅰ创建对应数据库对象类(bean):
实现两个接口:Writable、DBWritable和对应方法的重写(以下是DBWritable的对应方法的重写)
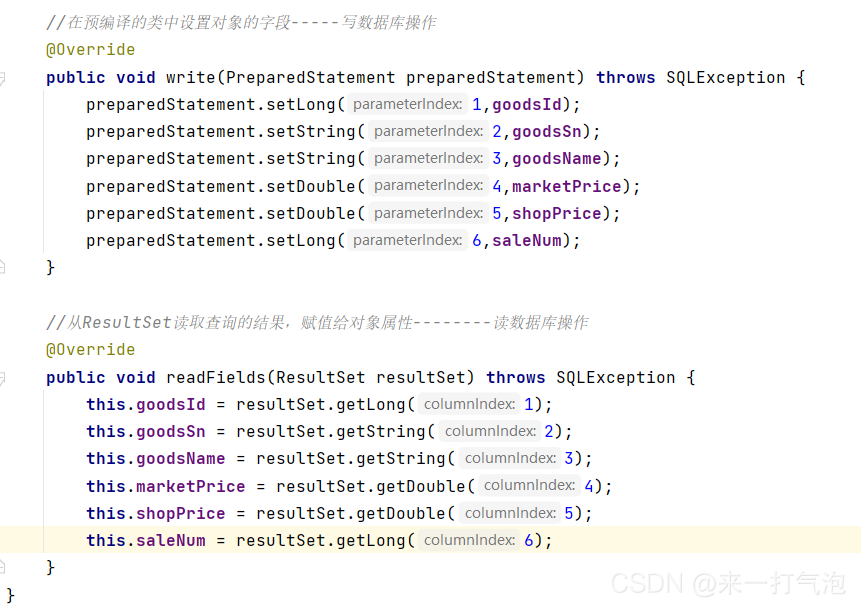
Ⅱ 根据业务需求分析得知,不需要reducer类,只需要mapper类将数据库中的表的数据读取出来并以<k,v>键值对的形式输出到定向文件中,因此编写mapper类(goodsbean里面已经实现了toString的方法):
/**
* DBInputFormat类用于从数据库中读取数据。底层一行一行读取表中的数据,返回<k,v>键值对
* k是LongWritable类型,表中数据的偏移量
* todo v是DBWritable类型,表示该行数据的对象类型
*/
public class ReadDB_Mapper extends Mapper<LongWritable,GoodsBean, Text, NullWritable> {
Text outkey = new Text();
NullWritable outvalue = NullWritable.get();
@Override
protected void map(LongWritable key, GoodsBean value, Context context) throws IOException, InterruptedException {
outkey.set(value.toString());
context.write(outkey,outvalue);
}
}
//将表中的数据输出到文件中,没有reduce阶段--------具体看Dirver类Ⅲ 在Driver类中,需要配置当前的jdbc信息(jdbc即java对数据库的一系列操作的API,详情请见:JDBC详细介绍_Jungle_Rao的博客-优快云博客_jdbc),还有对reducetask的设置(这里为0)
public class ReadDB_Driver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//配置文件对象
Configuration conf = new Configuration();
//todo 配置当前作业需要用到的jdbc信息
DBConfiguration.configureDB(
conf,
"com.mysql.jdbc.Driver", //jdbc的驱动
"jdbc:mysql://192.168.223.134:3306/ljh", //指定数据库
"root", //用户名
"123456" //密码
);
//创建作业的job类
Job job = Job.getInstance(conf, ReadDB_Driver.class.getSimpleName());
//设置MR程序的驱动类
job.setJarByClass(ReadDB_Driver.class);
//设置Mapper类
job.setMapperClass(ReadDB_Mapper.class);
//设置程序最终输出的k,v类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置输出路径
FileOutputFormat.setOutputPath 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4507
4507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









