




代码来源:B站up主蓝斯诺特(如有侵权联系立删)
任务:对于随机生成的一段序列,如abb123mn,模型翻译成NNM654BBA
(适用于对transformer架构有基础的了解,本文主要是代码的理解以及细节解释)
1、数据生成
参考代码,GitHub - lansinuote/Transformer_Example
B站也有这位up的讲解视频Transformer简明教程, 从理论到代码实现到项目实战, NLP进阶必知必会._哔哩哔哩_bilibili
2、词嵌入和位置编码
(1)词嵌入
代码中,输入到模型的数据shape为:[bs, 50],词库中一共有39个词(包含<pad>等),可以使用torch中自带的函数实现。
# 词嵌入层
# 参数39:词库中最大个数(即最大索引+1,从0开始),32:我设定的维度数
self.embed = torch.nn.Embedding(39, 32)
# 初始化参数,对词嵌入层的权重参数进行初始化,将其设置为服从均值为 0、标准差为 0.1 的正态分布(高斯分布)
#有助于模型在训练初期更稳定地更新参数,避免因初始值过大或过小导致的训练困难(如梯度消失 / 爆炸)。
self.embed.weight.data.normal_(0, 0.1)
在词嵌入后需要加上位置编码,具体的公式见下图(豆包生成,原公式见attention is all you need论文)

那这样的话,代码为:
def get_pe(pos, i, d_model):
fenmu = 1e4 ** (i / d_model)
pe = pos / fenmu
if i % 2 == 0:
return math.sin(pe)
return math.cos(pe)
# 初始化位置编码矩阵
pe = torch.empty(50, 32)#为了和先前得到词嵌入后的数据维度对其(实现在下面)
for pos in range(50):
for i in range(32):
pe[pos, j] = get_pe(pos, i, 32)#对于在原序列中pos处的词的第i维度的位置编码
pe = pe.unsqueeze(0)#在0号维度上加一个新维度pe = torch.empty(50, 32) -> [1, 50, 32]其中50是一句话或者一个序列的最大词数,pos是某个词的位置,i是他词b编码后的某一个维度,例如:
序列:abcd,我们将维度设置为2(代码中是32,并且假设他已经到达最大词数且不考虑<SOS>,<EOS>,<PAD>)
假设得到:
那么pe[2,1]代表第三个词c的第2个维度的位置编码(即-1.3处的位置编码)
得到了所有位置编码,那马
embed = embed + self.pe直接相加即可。
2、多头注意力机制(建议提前了解注意力机制)
(1)层归一化
transformer需要对 “单句话内的所有词” 做归一化(消除单句内词向量的数值波动),而 LayerNorm 正好是按 “逐样本、逐序列” 的通道维度(代码里是 32 维词嵌入)做归一化。
例如:3个样本的batch2个词4维的矩阵
样本1:1,2,3,4 样本2:10,20,30,40 样本3:2,4,6,8
5,6,7,8 50,60,70,80 10,12,14,16
层归一化会对每个样本的每个词的所有维度取样做归一化,例如取样本1的第一个词1,2,3,4求均值与方差做归一化,同理对样本1第二个词归一化………
最终

那对于BatchNorm,会对所有样本的所有词的每一个维度取样做归一化(可以理解为将每个样本拼接起来)
具体代码如下(手动计算与torch自动计算)
import torch
import torch.nn as nn
import numpy as np
# 1. 定义输入数据 [3个样本, 每个样本2个词, 每个词4维特征]
x = torch.tensor([
[[1, 2, 3, 4],
[5, 6, 7, 8]],
[[10, 20, 30, 40],
[50, 60, 70, 80]],
[[2, 4, 6, 8],
[10, 12, 14, 16]]
], dtype=torch.float32)
print("原始输入数据形状:", x.shape)
# 2. 初始化LayerNorm(关闭仿射变换,仅做归一化)
layer_norm = nn.LayerNorm(normalized_shape=4, elementwise_affine=False, eps=1e-5)
ln_output = layer_norm(x)
# 3. 手动计算每个词向量的均值、方差并验证
print("\n===== LayerNorm计算验证 =====")
for sample_idx in range(x.shape[0]): # 遍历3个样本
for word_idx in range(x.shape[1]): # 遍历每个样本的2个词
# 获取当前词向量(4维)
word_vec = x[sample_idx, word_idx]
# 计算均值(手动)
mean_manual = torch.mean(word_vec)
# 计算方差(手动,无偏估计,ddof=1)
var_manual = torch.var(word_vec, unbiased=False) # LayerNorm用有偏方差(除以n而非n-1)
# 手动归一化
normalized_manual = (word_vec - mean_manual) / torch.sqrt(var_manual + 1e-5)
# 获取PyTorch LayerNorm的结果
normalized_pytorch = ln_output[sample_idx, word_idx]
# 输出验证结果
print(f"\n样本{sample_idx + 1},词{word_idx + 1}:")
print(f" 原始向量:{word_vec.numpy()}")
print(f" 手动计算均值:{mean_manual.item():.4f}")
print(f" 手动计算方差:{var_manual.item():.4f}")
print(f" 手动归一化结果:{normalized_manual.numpy().round(4)}")
print(f" PyTorch计算结果:{normalized_pytorch.numpy().round(4)}")
print(f" 是否一致:{torch.allclose(normalized_manual, normalized_pytorch, atol=1e-4)}")import torch
import torch.nn as nn
import numpy as np
# 1. 定义输入数据 [3个样本, 每个样本2个词, 每个词4维特征]
x = torch.tensor([
[[1, 2, 3, 4],
[5, 6, 7, 8]],
[[10, 20, 30, 40],
[50, 60, 70, 80]],
[[2, 4, 6, 8],
[10, 12, 14, 16]]
], dtype=torch.float32)
print("原始输入数据形状:", x.shape) # [3, 2, 4]
# 2. 准备BatchNorm输入(需要展平为[batch_size, num_features])
# BatchNorm1d要求输入形状为[批量大小, 特征数, ...],这里合并前两维为批量
bn_input = x.reshape(-1, 4) # 形状变为[6, 4](3×2=6个实例,4个特征)
print("BatchNorm输入形状:", bn_input.shape) # [6, 4]
# 3. 初始化BatchNorm(关闭仿射变换,仅做归一化)
batch_norm = nn.BatchNorm1d(num_features=4, affine=False, eps=1e-5, momentum=0.0)
# 注意:momentum=0.0表示使用当前批次的统计信息,不累积历史均值
bn_output = batch_norm(bn_input)
# 4. 手动计算每个特征维度的全局均值、方差并验证
print("\n===== BatchNorm计算验证 =====")
# 计算每个特征维度(4个)的全局均值和方差(基于所有6个实例)
global_means = torch.mean(bn_input, dim=0) # 在批量维度(dim=0)上求均值
global_vars = torch.var(bn_input, dim=0, unbiased=False) # BatchNorm用有偏方差(除以n)
print(f"所有实例的全局特征均值:{global_means.numpy().round(4)}")
print(f"所有实例的全局特征方差:{global_vars.numpy().round(4)}\n")
# 遍历每个实例验证
for idx in range(bn_input.shape[0]):
instance = bn_input[idx] # 单个实例的4维特征
# 手动归一化:每个特征值减去对应维度的全局均值,除以全局标准差
normalized_manual = (instance - global_means) / torch.sqrt(global_vars + 1e-5)
# 获取PyTorch BatchNorm的结果
normalized_pytorch = bn_output[idx]
# 输出验证结果
print(f"实例{idx + 1}(原始特征):{instance.numpy()}")
print(f" 手动归一化结果:{normalized_manual.numpy().round(4)}")
print(f" PyTorch计算结果:{normalized_pytorch.numpy().round(4)}")
print(f" 是否一致:{torch.allclose(normalized_manual, normalized_pytorch, atol=1e-4)}\n")(2)QKV初始化
代码中直接使用了FC,其实就是矩阵相乘的变化:Q = X · W_Q + b_Q(且有偏置项,我记得原始论文中没有说要加偏置项,但是之后的开源项目中应该是默认包含偏置项,具体有知道的可以评论一下
)
(3)多头的实现
其实就是将QKV按照维度切开,例如代码中就是将32维切成4块
# 拆分成多个头
# b句话,每句话50个词,每个词编码成32维向量,4个头,每个头分到8维向量
# [b, 50, 32] -> [b, 4, 50, 8]
Q = Q.reshape(b, 50, 4, 8).permute(0, 2, 1, 3)
K = K.reshape(b, 50, 4, 8).permute(0, 2, 1, 3)
V = V.reshape(b, 50, 4, 8).permute(0, 2, 1, 3)(5)编码器、注意力
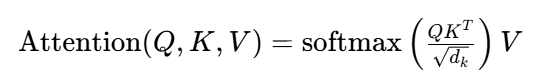
首先为了防止注意力关注序列后无意义的"<PAD>",我们需要引入mask,将注意力分数有关"<PAD>"的部分赋值为无穷小。
def mask_pad(data):
# b句话,每句话50个词,这里是还没embed的
# data = [b, 50]
# 判断每个词是不是<PAD>
mask = data == zidian_x['<PAD>']
# [b, 50] -> [b, 1, 1, 50]
mask = mask.reshape(-1, 1, 1, 50)
# 在计算注意力时,是计算50个词和50个词相互之间的注意力,所以是个50*50的矩阵
# 是pad的列是true,意味着任何词对pad的注意力都是0
# 但是pad本身对其他词的注意力并不是0
# 所以是pad的行不是true
# 复制n次
# [b, 1, 1, 50] -> [b, 1, 50, 50]
mask = mask.expand(-1, 1, 50, 50)
return mask其中的注意力分数是50*50的矩阵,表现为注意力公式中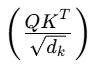 这一部分,所以我们最终得到的mask矩阵也是50*50(每个词对其他词的注意力,后面解码器的mask_tril_y的shape同理)。
这一部分,所以我们最终得到的mask矩阵也是50*50(每个词对其他词的注意力,后面解码器的mask_tril_y的shape同理)。
# 是pad的列是true,意味着任何词对pad的注意力都是0 # 但是pad本身对其他词的注意力并不是0
上面这两行注释需要了解(即为啥直接使用expand函数)
所以编码器的输入有:词编码后的矩阵,以及mask_pad矩阵。
另外,注意力中除以为了缓解内积结果过大导致的梯度消失问题,确保 softmax 函数能更稳定地输出合理的注意力权重。这其实是假设Q和K的元素服从高斯分布,那么其方差就是
,下图为豆包对
求法。

感觉kimi生成简单点。。。(下图,额对吗?我也不会,知道可以在评论区回答一下)

反正论文就是这么说的!(●'◡'●)
然后通过SoftMax得到[b, 4, 50, 50]的注意力概率值(别忘了4是头数),这里的50-50就代表50个词对50个词的注意力概率,然后与V相乘,再把4个头合并一下[b, 50, 32]。
最终在和输入到注意力机制的数据做一下残差(数值相加)即可。
每一个编码器层在做完多头后还需要层归一化并且经过一个全连接层进行线性学习,最终进行一个残差。(即代码中FullyConnectedOutput这个类)
这样从一开始的词嵌入,到位置编码,再到编码器中的多头注意力机制与全连接就完成了!
(6)解码器、cross注意力
首先需要明确的是,解码器的输入分别有:encoder输出的词编码矩阵x,mask_pad矩阵,x对应的翻译y此时y的shape为[bs,50],以及y对应的mask_tril_y矩阵。
(1、原始数据y的shape:[bs,51],y是翻译后的结果,但是模型解码器会预测下一个词,所以y要长一位
2、在训练时,是拿y的每一个字符输入,预测下一个字符,所以不需要最后一个字)
(1)为什么需要mask_tril_y矩阵?
对于解码器,我们需要输入原始数据以及其翻译的结果用于训练,但是在推理阶段解码器是没有完整目标序列的,解码器从起始符<SOS>开始逐个输出字符,所以我们在训练的时候对于已有的翻译结果y,我们希望解码器会确保每个位置只能看到自身及之前的词(防止泄露未来信息),所以需要使用mask将当前预测字符后面的字符掩盖。
所以对于我们的50*50的矩阵,最终得到的应该是一个上三角矩阵。
"""
[[0, 1, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 0, 1, 1],
[0, 0, 0, 0, 1],
[0, 0, 0, 0, 0]]
"""tril = 1 - torch.tril(torch.ones(1, 50, 50, dtype=torch.long))这一步即生成上面的矩阵。
当然,这个mask和之前的mask_pad一样需要对pad也加上掩盖,所以:
# 判断y当中每个词是不是pad,如果是pad则不可见
# [b, 50]
mask = data == zidian_y['<PAD>']
# 变形+转型,为了之后的计算
# [b, 1, 50]
mask = mask.unsqueeze(1).long()
# mask和tril求并集
# [b, 1, 50] + [1, 50, 50] -> [b, 50, 50]
mask = mask + tril最终变为bool值并变化维度以匹配bs。
(2)解码器的第一个att
第一个att是对标签y做的,和decoder里的att一样的逻辑,别忘了上面的mask。
将y:[b, 50, 32] -> [b, 50, 32]
(3)解码器的第二个att(Cross Attention)
这里的KV由x(这里的x是encoder输出的x)提供,即原始序列回答问题;
Q由上一步的输出的y提供,即y问问题;
并且这里的mask是mask_pad.(即y中的每个词对x中pad的注意力权重被softmax压缩到0)
之后就是全连接线性变换了。
最终的最终,这就是整个模型的前向传播:
def forward(self, x, y):
# [b, 1, 50, 50]
mask_pad_x = mask_pad(x)
mask_tril_y = mask_tril(y)
# 编码,添加位置信息
# x = [b, 50] -> [b, 50, 32]
# y = [b, 50] -> [b, 50, 32]
x, y = self.embed_x(x), self.embed_y(y)
# 编码层计算
# [b, 50, 32] -> [b, 50, 32]
x = self.encoder(x, mask_pad_x)
# 解码层计算
# [b, 50, 32],[b, 50, 32] -> [b, 50, 32]
y = self.decoder(x, y, mask_pad_x, mask_tril_y)
# 全连接输出,维度不变
# [b, 50, 32] -> [b, 50, 39]
y = self.fc_out(y)
return y注意fc的维度设置,模型最终会得到50个位置上,每个位置在词库(共39个词)中概率最高的哪一个!


















 925
925


 到【灌水乐园】发言
到【灌水乐园】发言








