







- 目的与要求
通过完成LL(1)语法分析程序分析和调试,了解自顶向下语法分析的思路,熟悉判断LL (1)文法的方法,学会构造LL(1)文法的预测分析表以及对某一个输入串的分析过程。本实验在培养编程能力的同时培养自主学习和团队协作能力。
- 实验内容
- 从键盘读入要分析的文法,并判断正误;若无误,由程序自动构造FIRST、FOLLOW 集以及SELECT集合,判断是否为LL (1)文法;
分析的文法为G[E]:(0)E→ TE’ (1)E’→ +TE’ (2)E’→ε (3)T→ FT’
(4)T’→ *FT’ (5)T’→ε (6)F→ (E) (7)F→a
- 若符合LL (1)文法,由程序自动构造LL (1)分析表;
- 由算法判断给定的输入符号串a*(a+a)是否为该文法的句型。
/**
* Created by kovic on 2023/4/26.
* Use IntelliJ IDEA 2022.2.2
*/
import java.util.*;
public class LL1 {
public static void main(String[] args) {
Test test = new Test();
test.getNvNt();
test.Init();
test.createTable();
test.ouput();
System.out.println("");
test.analyzeLL();
}
}
class Test {
public HashMap<Character, HashSet<Character>> firstSet = new HashMap<Character, HashSet<Character>>();
public HashMap<String, HashSet<Character>> firstSetX = new HashMap<String, HashSet<Character>>();
public Character S = 'E';
public HashMap<Character, HashSet<Character>> followSet = new HashMap<Character, HashSet<Character>>();
public HashSet<Character> VnSet = new HashSet<Character>();
public HashSet<Character> VtSet = new HashSet<Character>();
public HashMap<Character, ArrayList<String>> experssionSet = new HashMap<Character, ArrayList<String>>();
public String[][] table;
public Stack<Character> analyzeStatck = new Stack<Character>();
public String strInput = "a*(a+a)$";
public String action = "";
int index = 0;
Scanner scanner = new Scanner(System.in);
public String[] inputExperssion={};
public void Init() {
for (String e : inputExperssion) {
String[] str = e.split("->");
char c = str[0].charAt(0);
ArrayList<String> list = experssionSet.containsKey(c) ? experssionSet.get(c) : new ArrayList<String>();
list.add(str[1]);
experssionSet.put(c, list);
}
for (Character c : VnSet)
getFirst(c);
for (Character c : VnSet) {
ArrayList<String> l = experssionSet.get(c);
for (String s : l)
getFirst(s);
}
getFollow(S);
for (Character c : VnSet) {
getFollow(c);
}
}
public void getNvNt() {
System.out.println("注意:@ 为空, E‘->K T'->M");
System.out.print("请输入文法产生式的个数:");
int num =scanner.nextInt();
inputExperssion=new String[num];
System.out.println("请输入文法的"+num+"个产生式,并以回车分割每个产生式:");
for(int i=0;i<num;i++){
System.out.print("第"+ (i) +"个:");
inputExperssion[i]= scanner.next();
}
for (String e : inputExperssion) {
String[] str = e.split("->");
VnSet.add(str[0].charAt(0));
}
for (String e : inputExperssion) {
String[] str = e.split("->");
String right = str[1];
for (int i = 0; i < right.length(); i++)
if (!VnSet.contains(right.charAt(i)))
VtSet.add(right.charAt(i));
}
}
public void getFirst(Character c) {
ArrayList<String> list = experssionSet.get(c);
HashSet<Character> set = firstSet.containsKey(c) ? firstSet.get(c) : new HashSet<Character>();
// c为终结符 直接添加
if (VtSet.contains(c)) {
set.add(c);
firstSet.put(c, set);
return;
}
// c为非终结符 处理其每条产生式
for (String s : list) {
// c 推出空串 直接添加
if (s == Character.toString('@')) {
set.add('@');
}
// X -> Y1Y2Y3… 情况
else {
// 从左往右扫描生成式右部
int i = 0;
while (i < s.length()) {
char tn = s.charAt(i);
//先处理防止未初始化
getFirst(tn);
HashSet<Character> tvSet = firstSet.get(tn);
// 将其first集加入左部
for (Character tmp : tvSet)
set.add(tmp);
// 若包含空串 处理下一个符号
if (tvSet.contains('@'))
i++;
// 否则退出 处理下一个产生式
else
break;
}
}
}
firstSet.put(c, set);
}
public void getFirst(String s) {
HashSet<Character> set = (firstSetX.containsKey(s)) ? firstSetX.get(s) : new HashSet<Character>();
// 从左往右扫描该式
int i = 0;
while (i < s.length()) {
char tn = s.charAt(i);
HashSet<Character> tvSet = firstSet.get(tn);
// 将其非空 first集加入左部
for (Character tmp : tvSet)
if (tmp != '@')
set.add(tmp);
// 若包含空串 处理下一个符号
if (tvSet.contains('@'))
i++;
// 否则结束
else
break;
// 到了尾部 即所有符号的first集都包含空串 把空串加入
if (i == s.length()) {
set.add('@');
}
}
firstSetX.put(s, set);
}
public void getFollow(char c) {
ArrayList<String> list = experssionSet.get(c);
HashSet<Character> setA = followSet.containsKey(c) ? followSet.get(c) : new HashSet<Character>();
//如果是开始符 添加 $
if (c == S) {
setA.add('$');
}
//查找输入的所有产生式,确定c的后跟 终结符
for (Character ch : VnSet) {
ArrayList<String> l = experssionSet.get(ch);
for (String s : l)
for (int i = 0; i < s.length(); i++)
if (s.charAt(i) == c && i + 1 < s.length() && VtSet.contains(s.charAt(i + 1)))
setA.add(s.charAt(i + 1));
}
followSet.put(c, setA);
//处理c的每一条产生式
for (String s : list) {
int i = s.length() - 1;
while (i >= 0) {
char tn = s.charAt(i);
//只处理非终结符
if (VnSet.contains(tn)) {
// 都按 A->αBβ 形式处理
//若β不存在 followA 加入 followB
//若β存在,把β的非空first集 加入followB
//若β存在 且 first(β)包含空串 followA 加入 followB
//若β存在
if (s.length() - i - 1 > 0) {
String right = s.substring(i + 1);
//非空first集 加入 followB
HashSet<Character> setF = null;
if (right.length() == 1) {
if (!firstSet.containsKey(right.charAt(0)))
getFirst(right.charAt(0));
setF = firstSet.get(right.charAt(0));
} else {
//先找出右部的first集
if (!firstSetX.containsKey(right))
getFirst(right);
setF = firstSetX.get(right);
}
HashSet<Character> setX = followSet.containsKey(tn) ? followSet.get(tn) : new HashSet<Character>();
for (Character var : setF)
if (var != '@')
setX.add(var);
followSet.put(tn, setX);
// 若first(β)包含空串 followA 加入 followB
if (setF.contains('@')) {
if (tn != c) {
HashSet<Character> setB = followSet.containsKey(tn) ? followSet.get(tn) : new HashSet<Character>();
for (Character var : setA)
setB.add(var);
followSet.put(tn, setB);
}
}
}
//若β不存在 followA 加入 followB
else {
// A和B相同不添加
if (tn != c) {
HashSet<Character> setB = followSet.containsKey(tn) ? followSet.get(tn) : new HashSet<Character>();
for (Character var : setA)
setB.add(var);
followSet.put(tn, setB);
}
}
i--;
}
//如果是终结符往前看 如 A->aaaBCDaaaa 此时β为 CDaaaa
else i--;
}
}
}
public void createTable() {
Object[] VtArray = VtSet.toArray();
Object[] VnArray = VnSet.toArray();
// 预测分析表初始化
table = new String[VnArray.length + 1][VtArray.length + 1];
table[0][0] = "Vn/Vt";
//初始化首行首列
for (int i = 0; i < VtArray.length; i++)
table[0][i + 1] = (VtArray[i].toString().charAt(0) == '@') ? "$" : VtArray[i].toString();
for (int i = 0; i < VnArray.length; i++)
table[i + 1][0] = VnArray[i] + "";
//全部置error
for (int i = 0; i < VnArray.length; i++)
for (int j = 0; j < VtArray.length; j++)
table[i + 1][j + 1] = "error";
//插入生成式
for (char A : VnSet) {
ArrayList<String> l = experssionSet.get(A);
for (String s : l) {
HashSet<Character> set = firstSetX.get(s);
for (char a : set)
insert(A, a, s);
if (set.contains('@')) {
HashSet<Character> setFollow = followSet.get(A);
if (setFollow.contains('$'))
insert(A, '$', s);
for (char b : setFollow)
insert(A, b, s);
}
}
}
}
public void analyzeLL() {
System.out.println("****************LL分析过程**********");
System.out.println(" Stack Input Action");
analyzeStatck.push('$');
analyzeStatck.push('E');
displayLL();
char X = analyzeStatck.peek();
while (X != '$') {
char a = strInput.charAt(index);
if (X == a) {
action = "match " + analyzeStatck.peek();
analyzeStatck.pop();
index++;
} else if (VtSet.contains(X))
return;
else if (find(X, a).equals("error"))
return;
else if (find(X, a).equals("@")) {
analyzeStatck.pop();
action = X + "->@";
} else {
String str = find(X, a);
if (str != "") {
action = X + "->" + str;
analyzeStatck.pop();
int len = str.length();
for (int i = len - 1; i >= 0; i--)
analyzeStatck.push(str.charAt(i));
} else {
System.out.println("error at '" + strInput.charAt(index) + " in " + index);
return;
}
}
X = analyzeStatck.peek();
displayLL();
}
System.out.println("该文法符合LL(1)文法");
System.out.println("****************LL分析过程**********");
}
public String find(char X, char a) {
for (int i = 0; i < VnSet.size() + 1; i++) {
if (table[i][0].charAt(0) == X)
for (int j = 0; j < VtSet.size() + 1; j++) {
if (table[0][j].charAt(0) == a)
return table[i][j];
}
}
return "";
}
public void insert(char X, char a, String s) {
if (a == '@') a = '$';
for (int i = 0; i < VnSet.size() + 1; i++) {
if (table[i][0].charAt(0) == X)
for (int j = 0; j < VtSet.size() + 1; j++) {
if (table[0][j].charAt(0) == a) {
table[i][j] = s;
return;
}
}
}
}
public void displayLL() {
// 输出 LL1
Stack<Character> s = analyzeStatck;
System.out.printf("%23s", s);
System.out.printf("%13s", strInput.substring(index));
System.out.printf("%10s", action);
System.out.println();
}
public void ouput() {
System.out.println("*********first集********");
for (Character c : VnSet) {
HashSet<Character> set = firstSet.get(c);
System.out.printf("%10s", c + " -> ");
for (Character var : set)
System.out.print(var);
System.out.println();
}
System.out.println("**********first集**********");
System.out.println("");
System.out.println("**********follow集*********");
for (Character c : VnSet) {
HashSet<Character> set = followSet.get(c);
System.out.print("Follow " + c + ":");
for (Character var : set)
System.out.print(var);
System.out.println();
}
System.out.println("**********follow集**********");
System.out.println("");
System.out.println("**********LL1预测分析表********");
for (int i = 0; i < VnSet.size() + 1; i++) {
for (int j = 0; j < VtSet.size() + 1; j++) {
System.out.printf("%6s", table[i][j] + " ");
}
System.out.println();
}
System.out.println("**********LL1预测分析表********");
}
}
- 结果分析(包括实验结果截图)
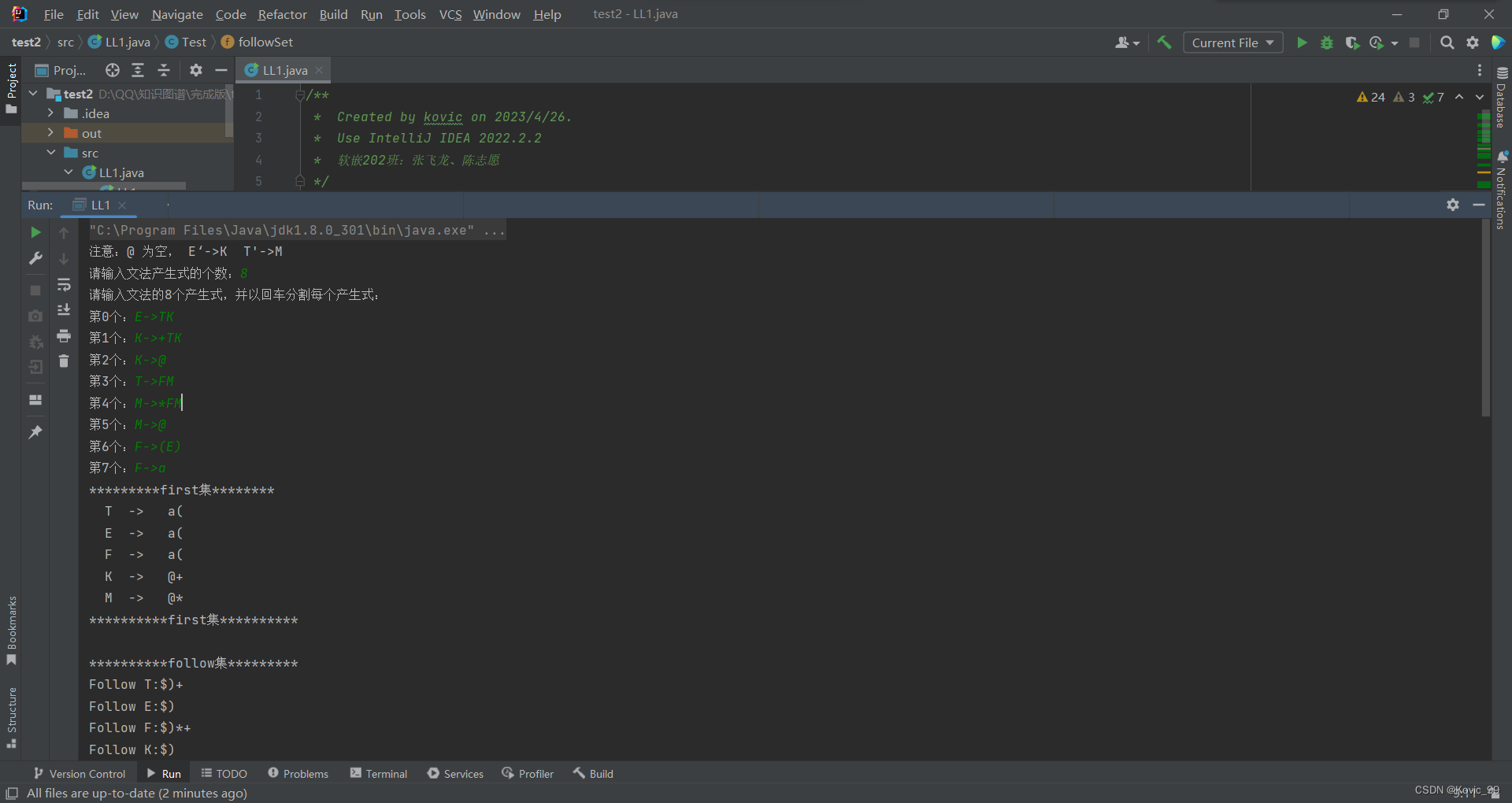
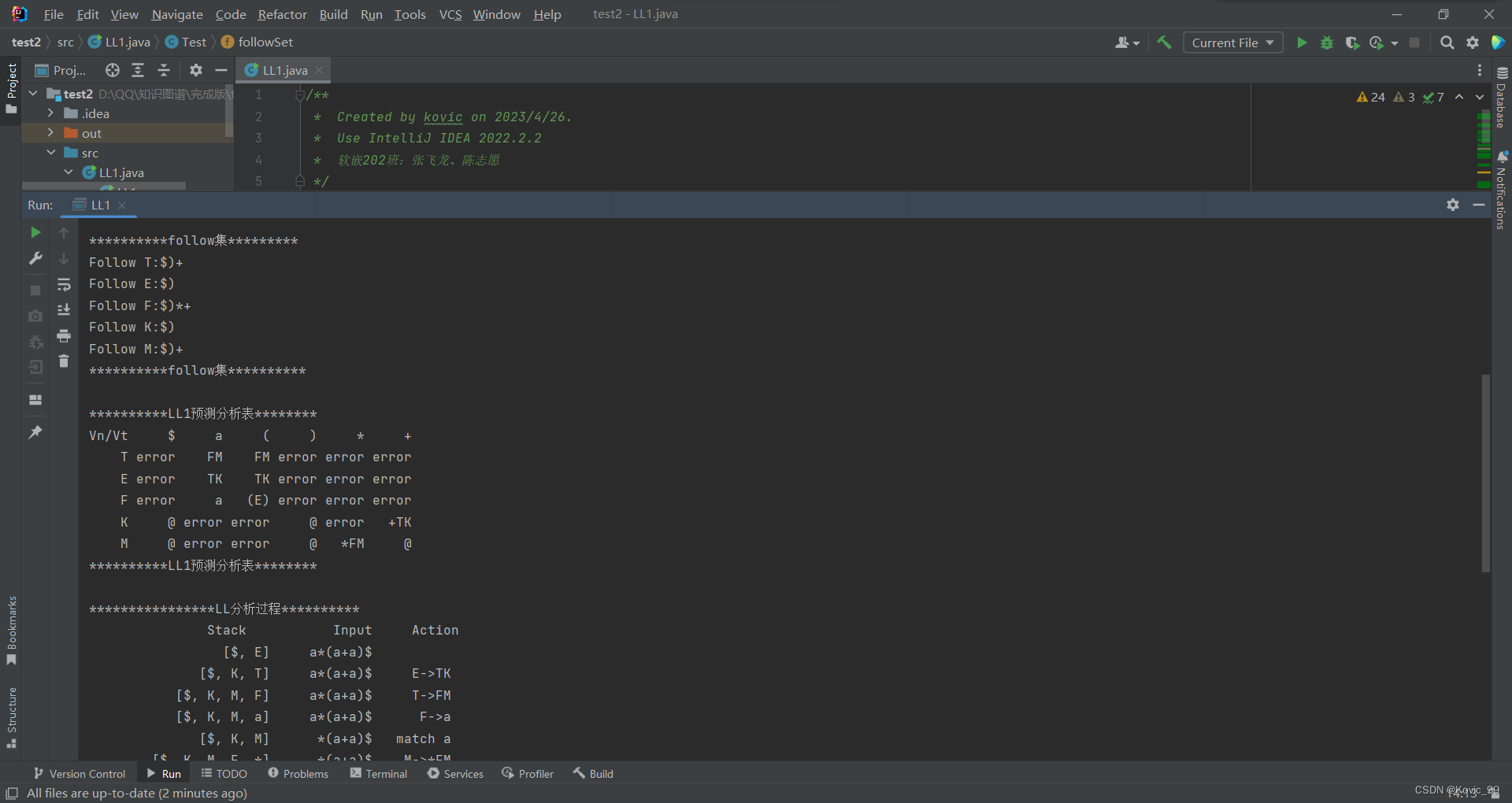
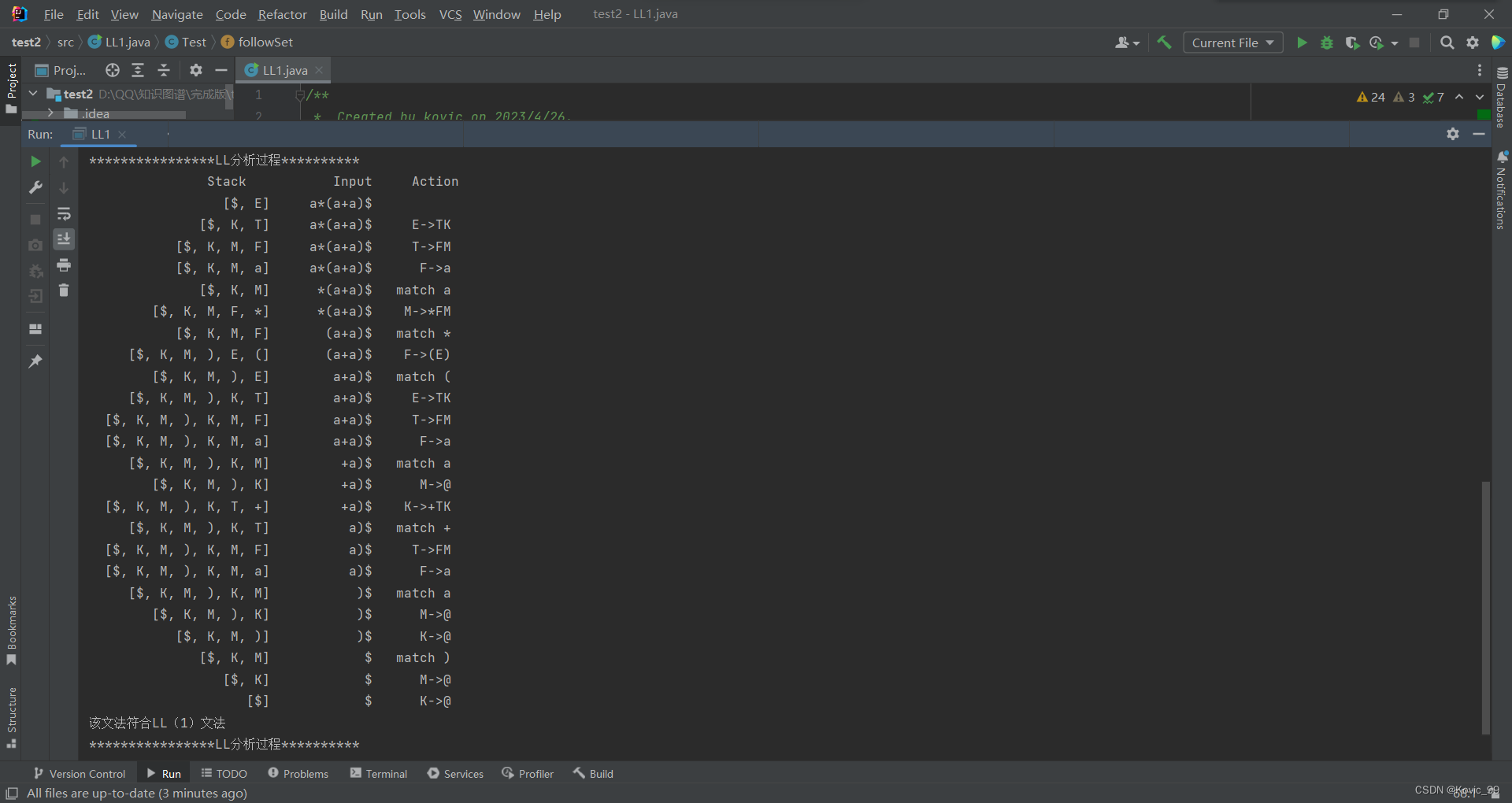
实验结果分析:经分析,文法G[E]符合LL(1)文法,且给定的输入符号串a*(a+a)是该文法的句型。


















 1947
1947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









