







一、实验目的
编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的内部编码及单词符号自身值。
二、实验题目
如源程序为C语言。输入如下一段:
int main()
{
int a=-5,b=4,j;
if(a>=b)
j=a-b;
else j=b-a;
}
要求输出如下:
(2,"void") (2,"main") (5,"(")
(5,")") (5,"{") (1,"int")
(2,"a") (4,"=") (3,"-5")
(5,",") (2,"b") (4,"=")
(3,"4") (5,",") (2,"j")
(5,";") (1,"if") (5,"(")
(2,"a") (4,">=") (2,"b")
(5,")") (2,"j") (4,"=")
(2,"a") (4,"-") (2,"b")
(5,";") (1,"else") (2,"j")
(4,"=") (2,"b") (4,"-")
(2,"a") (5,";") (5,"}")
三、实验理论依据
(一)识别各种单词符号
1.程序语言的单词符号一般分为五种:
(1)关键字(保留字/ 基本字)if 、while 、begin…
(2)标识符:常量名、变量名…
(3)常数:34 、56.78 、true 、‘a’ 、…
(4)运算符:+ 、- 、* 、/ 、〈 、and 、or 、….
(5)界限符:, ; ( ) { } /*…
2.识别单词:掌握单词的构成规则很重要
(1)标识符的识别:字母| 下划线+( 字母/ 数字/ 下划线)
(2)关键字的识别:与标识符相同,最后查表
(3)常数的识别
(4)界符和算符的识别
3.大多数程序设计语言的单词符号都可以用转换图来识别,如图1-1
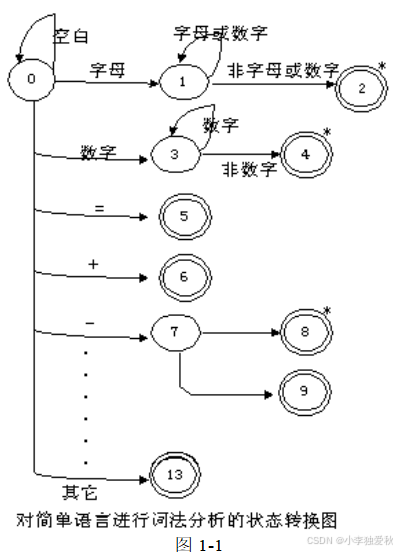
4.词法分析器输出的单词符号常常表示为二元式:(单词种别,单词符号的属性值)
(1)单词种别通常用整数编码,如1 代表关键字,2 代表标识符等
(2)关键字可视其全体为一种,也可以一字一种。采用一字一种得分法实际处理起来较为方便。
(3)标识符一般统归为一种
(4)常数按类型(整、实、布尔等)分种
(5)运算符可采用一符一种的方法。
(6)界符一般一符一种的分法。
(二)超前搜索方法
1.词法分析时,常常会用到超前搜索方法。
如当前待分析字符串为“a>+” ,当前字符为“>” ,此时,分析器倒底是将其分析为大于关系运算符还是大于等于关系运算符呢?
显然,只有知道下一个字符是什么才能下结论。于是分析器读入下一个字符’+’ ,这时可知应将’>’ 解释为大于运算符。但此时,超前读了一个字符’+’ ,所以要回退一个字符,词法分析器才能正常运行。又比如:‘+’ 分析为正号还是加法符号
-
(三)预处理
-
预处理工作包括对空白符、跳格符、回车符和换行符等编辑性字符的处理,及删除注解等。由一个预处理子程序来完成。
-
四、词法分析器的设计
-
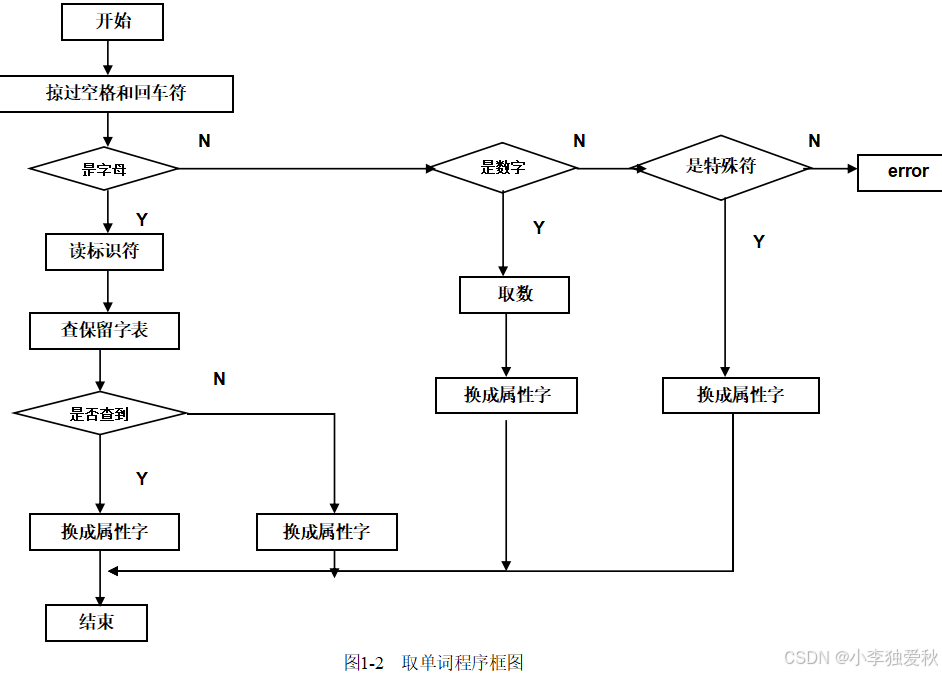
1.设计方法:
(1)写出该语言的词法规则。
(2)把词法规则转换为相应的状态转换图。
(3)把各转换图的初态连在一起,构成识别该语言的自动机
(4)设计扫描器
2.把扫描器作为语法分析的一个过程,当语法分析需要一个单词时,就调用扫描器。 扫描器从初态出发,当识别一个单词后便进入终态,送出二元式 。
五、实例代码+运行结果
1.实例代码(一):
不使用操作文件系统的代码,在main函数里面直接定义const char *类型,把想要输入的直接装在里面
(1)源代码文件:
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#include <stdlib.h>
#define MAX_TOKENS 100
#define MAX_LEX_LEN 50
typedef struct {
int type;
char value[MAX_LEX_LEN];
} Token;
Token tokens[MAX_TOKENS];
int token_count = 0;
int last_token_type = 0; // 新增:跟踪上一个token类型
const char *keywords[] = {"int", "if", "else"};
const char *operators[] = {"=", "+", "-", ">=", "<=", ">", "<", "==", "!=", "++", "--"};
const char delimiters[] = {'(', ')', '{', '}', ',', ';'};
int is_keyword(const char *str) {
for (int i = 0; i < sizeof(keywords)/sizeof(keywords[0]); i++) {
if (strcmp(keywords[i], str) == 0) return 1;
}
return 0;
}
int is_operator(const char *str) {
for (int i = 0; i < sizeof(operators)/sizeof(operators[0]); i++) {
if (strcmp(operators[i], str) == 0) return 1;
}
return 0;
}
int is_delimiter(char c) {
for (int i = 0; i < sizeof(delimiters)/sizeof(delimiters[0]); i++) {
if (delimiters[i] == c) return 1;
}
return 0;
}
void add_token(int type, const char *value) {
if (token_count >= MAX_TOKENS) {
fprintf(stderr, "Token数组已满\n");
exit(EXIT_FAILURE);
}
Token *t = &tokens[token_count++];
t->type = type;
strncpy(t->value, value, MAX_LEX_LEN);
last_token_type = type; // 更新上一个token类型
}
void lexer(const char *code) {
int i = 0;
int len = strlen(code);
while (i < len) {
if (isspace(code[i])) {
i++;
continue;
}
char buffer[MAX_LEX_LEN] = {0};
int buf_pos = 0;
// 处理数字(需要先于运算符处理)
if (isdigit(code[i]) || (code[i] == '-' && (last_token_type == 4 || last_token_type == 5) && i+1 < len && isdigit(code[i+1]))) {
int has_minus = 0;
if (code[i] == '-') {
buffer[buf_pos++] = code[i++];
has_minus = 1;
}
while (i < len && isdigit(code[i])) {
buffer[buf_pos++] = code[i++];
}
if (has_minus && buf_pos == 1) {
fprintf(stderr, "无效的数字格式: %s\n", buffer);
exit(EXIT_FAILURE);
}
add_token(3, buffer);
continue;
}
// 处理标识符和关键字
if (isalpha(code[i]) || code[i] == '_') {
while (i < len && (isalnum(code[i]) || code[i] == '_')) {
buffer[buf_pos++] = code[i++];
}
buffer[buf_pos] = '\0';
if (is_keyword(buffer)) {
add_token(1, buffer);
} else {
add_token(2, buffer);
}
continue;
}
// 处理运算符
if (strchr("=+-<>!&|", code[i])) {
buffer[buf_pos++] = code[i++];
// 尝试匹配双字符运算符
if (i < len) {
char temp[3] = {buffer[0], code[i], '\0'};
if (is_operator(temp)) {
buffer[buf_pos++] = code[i++];
} else {
// 尝试匹配单字符双运算符
temp[1] = '\0';
if (is_operator(temp) && (temp[0] == '+' || temp[0] == '-')) {
if (i < len && code[i] == temp[0]) {
buffer[buf_pos++] = code[i++];
}
}
}
}
// 精确匹配最长运算符
while (buf_pos > 0) {
buffer[buf_pos] = '\0';
if (is_operator(buffer)) {
add_token(4, buffer);
break;
} else {
i--;
buf_pos--;
}
}
continue;
}
// 处理分隔符
if (is_delimiter(code[i])) {
buffer[buf_pos++] = code[i++];
add_token(5, buffer);
continue;
}
fprintf(stderr, "无法识别的字符: %c\n", code[i]);
exit(EXIT_FAILURE);
}
}
void print_tokens() {
for (int i = 0; i < token_count; i++) {
printf("(%d,\"%s\")", tokens[i].type, tokens[i].value);
if ((i+1) % 3 == 0) printf("\n");
else printf(" ");
}
if (token_count % 3 != 0) printf("\n");
}
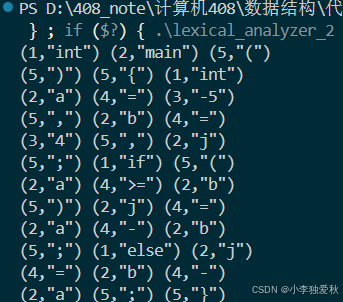
int main() {
const char *test_code =
"void main()\n"
"{\n"
"int a=-5,b=4,j;\n"
"if(a>=b) \n"
"j=a-b; \n"
"else j=b-a;\n"
"}\n";
lexer(test_code);
print_tokens();
return 0;
}
(2) 代码分析
代码的具体注释与分析可移步至资源区下载,包含源文件与分析。
(3)输出结果截图
2.实例代码(二):
(1)源代码文件
使用操作文件系统的代码,在输入文件写上自己想词法分析的代码即可,比实例代码(一)更加灵活。
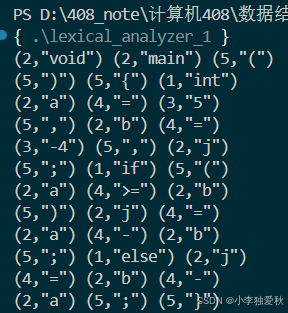
输入文件example.c:
void main()
{
int a=5,b=-4,j;
if(a>=b)
j=a-b;
else j=b-a;
}
主文件lexical_analyzer.c:
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#include <stdlib.h>
#define MAX_LEX_LEN 50
typedef enum {
KEYWORD = 1,
IDENTIFIER,
CONSTANT,
OPERATOR,
DELIMITER
} TokenType;
// 全局变量
FILE *fp;
int token_count = 0;
int last_token_type = 0; // 新增:记录上一个token类型
// 保留字表
const char *keywords[] = {"int", "if", "else", "for", "while", "do", "return", "break", "continue"};
void print_token(int type, const char *value) {
printf("(%d,\"%s\") ", type, value);
last_token_type = type; // 记录当前token类型
if (++token_count % 3 == 0) printf("\n");
}
int search(const char *word) {
for (int i = 0; i < sizeof(keywords)/sizeof(keywords[0]); i++) {
if (strcmp(keywords[i], word) == 0) return i + 1;
}
return 0;
}
char alpha_process(char buffer) {
char lexeme[MAX_LEX_LEN] = {0};
int pos = 0;
do {
lexeme[pos++] = buffer;
buffer = fgetc(fp);
} while (isalnum(buffer) || buffer == '_');
lexeme[pos] = '\0';
int kw_type = search(lexeme);
if (kw_type > 0) {
print_token(KEYWORD, lexeme);
} else {
print_token(IDENTIFIER, lexeme);
}
return buffer;
}
char digit_process(char buffer) {
char lexeme[MAX_LEX_LEN] = {0};
int pos = 0;
// 处理负数(只有当上一个token是运算符或分隔符时)
if (buffer == '-' && (last_token_type == OPERATOR || last_token_type == DELIMITER)) {
lexeme[pos++] = buffer;
buffer = fgetc(fp);
}
while (isdigit(buffer)) {
lexeme[pos++] = buffer;
buffer = fgetc(fp);
}
lexeme[pos] = '\0';
print_token(CONSTANT, lexeme);
return buffer;
}
char other_process(char buffer) {
char ch[3] = {0};
ch[0] = buffer;
// 处理分隔符
if (strchr("(),;{}", buffer)) {
print_token(DELIMITER, ch);
return fgetc(fp);
}
// 处理多字符运算符
if (strchr("=+-<>!=", buffer)) {
char next = fgetc(fp);
// 处理 >=, <=, ==, !=
if (next == '=' && strchr("=><!", buffer)) {
ch[1] = next;
buffer = fgetc(fp);
print_token(OPERATOR, ch);
return buffer;
}
// 处理 ++, --
else if ((buffer == '+' || buffer == '-') && next == buffer) {
ch[1] = next;
buffer = fgetc(fp);
print_token(OPERATOR, ch);
return buffer;
}
// 处理单个运算符
else {
print_token(OPERATOR, ch);
return next;
}
}
// 处理其他运算符
if (strchr("+-*/%", buffer)) {
print_token(OPERATOR, ch);
return fgetc(fp);
}
fprintf(stderr, "\n非法字符: %c\n", buffer);
exit(EXIT_FAILURE);
}
int main() {
if ((fp = fopen("example.c", "r")) == NULL) {
perror("无法打开文件");
return EXIT_FAILURE;
}
char cbuffer = fgetc(fp);
while (cbuffer != EOF) {
if (isspace(cbuffer)) {
cbuffer = fgetc(fp);
continue;
}
if (isalpha(cbuffer) || cbuffer == '_') {
cbuffer = alpha_process(cbuffer);
}
else if (isdigit(cbuffer) || (cbuffer == '-' && (last_token_type == OPERATOR || last_token_type == DELIMITER))) {
cbuffer = digit_process(cbuffer);
}
else {
cbuffer = other_process(cbuffer);
}
}
if (token_count % 3 != 0) printf("\n");
fclose(fp);
return 0;
}
(2) 代码分析
代码的具体注释与分析可移步至资源区下载,包含源文件与分析。
(3)输出结果截图
六、实验总结
一、心得与收获
-
深入理解词法分析的核心逻辑
1.通过实现状态转换图,掌握了如何将字符流分解为独立单词符号的过程,尤其是对保留字、标识符、运算符的分辨逻辑。
2.实践了超前搜索方法,理解了多字符运算符(如>=、==)的识别机制,体会到编译过程中“预判与回退”的重要性。 -
理论与实践的紧密结合
- 将课堂中学习的词法规则(如标识符命名规范、运算符优先级)转化为代码逻辑,加深了对编译原理底层实现的理解。
- 通过处理负数常数(如
-5)的边界情况,认识到词法分析需兼顾语法规则与实际代码的复杂性。
-
代码设计与调试能力提升
- 优化了字符处理流程,例如通过
isalpha()和isdigit()函数高效分离字母、数字和其他符号。 - 调试过程中,发现并修复了因未正确处理分隔符(如
;、,)导致的逻辑漏洞,增强了代码鲁棒性。
- 优化了字符处理流程,例如通过
-
对编译器的敬畏与兴趣
- 意识到即使是最基础的词法分析,也需要严谨的逻辑和细致的边界处理,进一步激发了探索语法分析、语义分析等后续阶段的兴趣。
二、改进方向
-
错误处理机制
- 当前程序未对非法字符(如
@、$)进行报错,未来需增加错误检测模块,提示用户输入中的非法符号位置。
- 当前程序未对非法字符(如
-
扩展性优化
- 支持更多数据类型(如浮点数、字符串常量),需改进
digitprocess函数以识别科学计数法(如3.14e-5)。 - 增加对注释(
//、/* */)的过滤功能,完善预处理模块。
- 支持更多数据类型(如浮点数、字符串常量),需改进
-
性能与代码结构
- 使用哈希表替代线性遍历,加速保留字的查找效率(如将
key[8]改为哈希表存储)。 - 拆分函数模块,避免
alphaprocess和otherprocess函数过于臃肿,提升代码可维护性。
- 使用哈希表替代线性遍历,加速保留字的查找效率(如将
-
用户交互与测试
- 增加对多文件输入的支持,提供命令行参数读取功能(如
./lexer test.c)。 - 设计更全面的测试用例,覆盖边界情况(如
a1_、0x1F等),确保程序健壮性。
- 增加对多文件输入的支持,提供命令行参数读取功能(如
三、结语
本次实验不仅巩固了词法分析的理论知识,更让我体会到编译器设计的精妙与挑战。通过实践,我认识到编译原理并非“纸上谈兵”,而是需要将严谨的逻辑转化为代码细节。未来希望在此基础上,逐步实现完整的编译器前端,探索从字符流到抽象语法树的全流程构建!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











