






 本文介绍了如何使用Python的Selenium库结合BeautifulSoup进行网页抓取,获取商品名称、价格、作者等信息,并抓取店铺评价数据,包括好评、中评和差评数量。
本文介绍了如何使用Python的Selenium库结合BeautifulSoup进行网页抓取,获取商品名称、价格、作者等信息,并抓取店铺评价数据,包括好评、中评和差评数量。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import random
import csv
from bs4 import BeautifulSoup
# 设置随机User-Agent
def set_user_agent(driver):
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0) Gecko/20100101 Firefox/87.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Firefox/87.0",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:87.0) Gecko/20100101 Firefox/87.0",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Firefox/87.0",
]
user_agent = random.choice(user_agents)
options = Options()
options.add_argument(f'user-agent={user_agent}')
driver = webdriver.Chrome(options=options)
return driver
# 解析商品信息
def get_product_info(driver, div, csv_writer):
name = div.find("div", class_="title").get_text().strip()
price = div.find("span", class_="bold").get_text().strip()
print("书名:" + name)
print("价格: " + price)
isbn_info = div.find("div", class_="zl-isbn-info")
if isbn_info is not None:
spans = isbn_info.find_all("span", class_="text")
author = spans[0].get_text().strip().replace("/", "")
publisher = spans[1].get_text().strip().replace("/", "")
publish_date = spans[2].get_text().strip().replace("/", "")
else:
author = div.find("span", class_="normal-text").get_text().strip()
publisher = div.find_all("span", class_="normal-text")[1].get_text().strip()
publish_date = div.find_all("span", class_="normal-text")[2].get_text().strip()
print("作者:" + author)
print("出版社:" + publisher)
print("出版年份:"+ publish_date)
shop_name = div.find("div", class_="text").find("span").get_text().strip()
print("商店名称: ", shop_name)
link = div.find("div", class_="title").find("a").get("href")
if "http" not in link:
link = "https:" + link
# 在新标签页中打开链接
driver.execute_script(f'''window.open("{link}","_blank");''')
windows = driver.window_handles
driver.switch_to.window(windows[-1])
time.sleep(3)
# 检测新标签页是否成功打开
if len(windows) != len(driver.window_handles):
print("无法打开新标签页")
driver.switch_to.window(windows[0])
return None
try:
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "li[data-page='shop-remark-page']")))
soup_new = BeautifulSoup(driver.page_source, "html.parser")
# 点击“店铺评价”链接
remark_link = driver.find_element_by_css_selector("li[data-page='shop-remark-page']")
driver.execute_script("arguments[0].click();", remark_link)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, "span.total-count")))
time.sleep(3)
remark_page_html = driver.page_source
remark_page_soup = BeautifulSoup(remark_page_html, "html.parser")
comment_num = remark_page_soup.find("span", class_="total-count").get_text() \
if remark_page_soup.find("span", class_="total-count") is not None else '未找到'
print("评论数量:" + comment_num)
good_comment = remark_page_soup.find("li", {"data-lev": "good"})
if good_comment is not None:
good_count = good_comment.find("span", class_="good-count")
if good_count is not None:
good_count = good_count.get_text()
print("好评数:" + good_count)
else:
print("未找到好评数")
else:
print("未找到好评")
common_comment = remark_page_soup.find("span", class_="common-count").get_text() \
if remark_page_soup.find("span", class_="common-count") is not None else '未找到'
print("中评数:" + common_comment)
bad_comment = remark_page_soup.find("span", class_="bad-count").get_text() \
if remark_page_soup.find("span", class_="bad-count") is not None else '未找到'
print("差评数:" + bad_comment)
print("-----------------------")
info = {
"书名": name,
"价格": price,
"作者": author,
"出版社": publisher,
"出版年份": publish_date,
"商店名称": shop_name,
"评论数量": comment_num,
"好评数": good_count,
"中评数": common_comment,
"差评数": bad_comment,
}
# 实时写入CSV文件并查看文件内容
csv_writer.writerow(info)
with open(filename, 'r', encoding='utf-8') as read_file:
content = read_file.read()
print(content)
except Exception as e:
print("获取评论信息失败:", str(e))
info = None
driver.close()
driver.switch_to.window(windows[0])
return info
# 使用Chrome浏览器和无界面模式
chrome_options = Options()
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
# 设置参数
keyword = "人工智能"
page_num = 1 # 从第几页开始
total_pages = 200 # 设置要爬取的总页数
# 打开CSV文件并设置头部
filename = f"{keyword}.csv"
fields = ["书名", "价格", "作者", "出版社", "出版年份", "商店名称", "评论数量", "好评数", "中评数", "差评数"]
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.DictWriter(csvfile, fieldnames=fields)
csv_writer.writeheader()
while page_num <= total_pages:
try:
url = f"https://search.kongfz.com/product_result/?key={keyword}&status=0&_stpmt=eyJzZWFyY2hfdHlwZSI6ImFjdGl2ZSJ9&pagenum={page_num}&ajaxdata=1"
driver.get(url)
time.sleep(3)
print("正在爬取第", page_num, "页:", driver.current_url)
html_content = driver.page_source
soup = BeautifulSoup(html_content, "html.parser")
div_list = soup.find_all("div", class_="item clearfix")
for div in div_list:
info = get_product_info(driver, div, csv_writer)
if info is not None:
pass
page_num += 1
except Exception as e:
print("爬取第", page_num, "页出错:", str(e))
break
# 关闭浏览器
driver.quit()
print("数据已保存到", filename)ps:更新搜索关键词设置以及实时保存爬取信息!以及一些注意事项~~
注意!!!selenium可使用3.141.0版本!!!
安装方法: pip install selenium==3.141.0 ,其他版本或可
报错:ValueError: Timeout value connect was <object object at 0x0000019A00694540>, but it must be an int, float or None.
解决方法: pip uninstall urllib3
pip install urllib3==1.26.2(requests版本为2.31.0,urllib3在1.24到26之间的版本都可,参考下图)

总之各个版本需要匹配(python3.10最新的4.16.0的selenium配上2.1.0的urllib3也能正常运行!)
如遇到其他出错可能是网络问题,可适当添加: time.sleep(3)
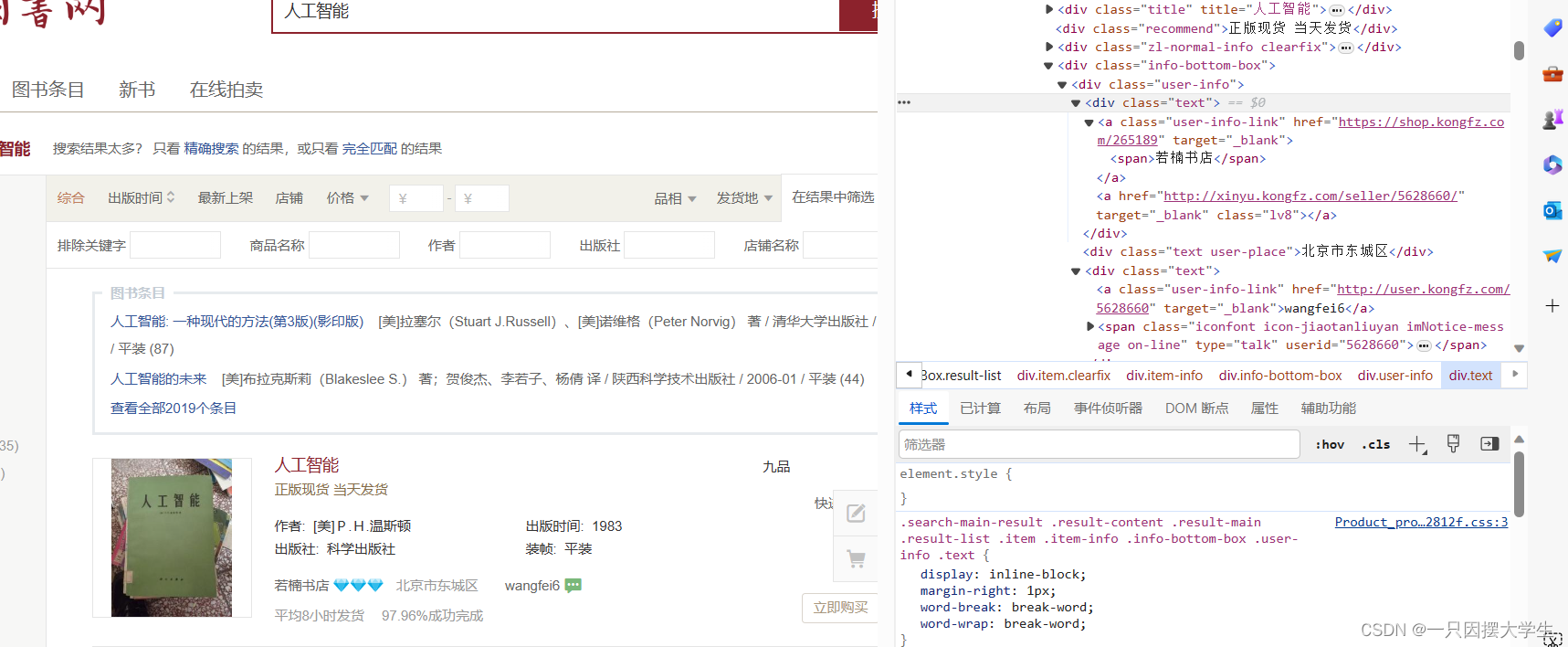


以上图片为爬取商店名称简单示例,爬取其余信息使用类似方法即可!!!
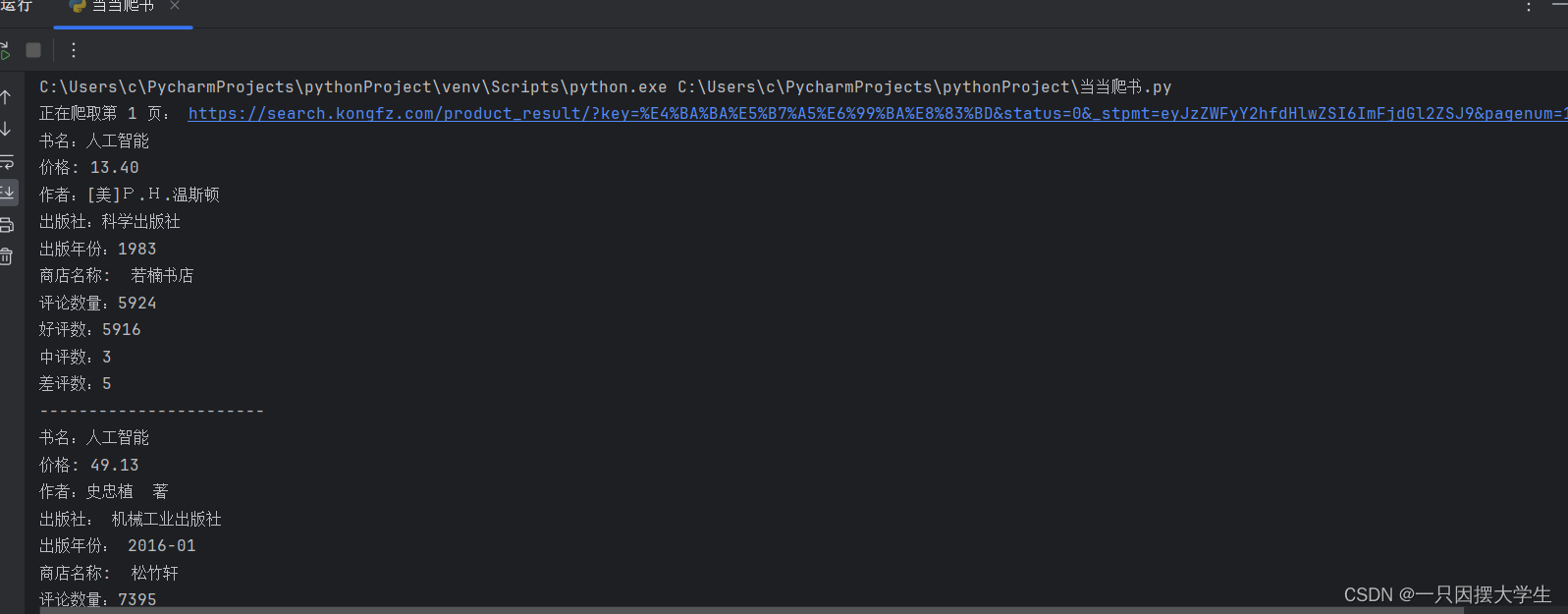
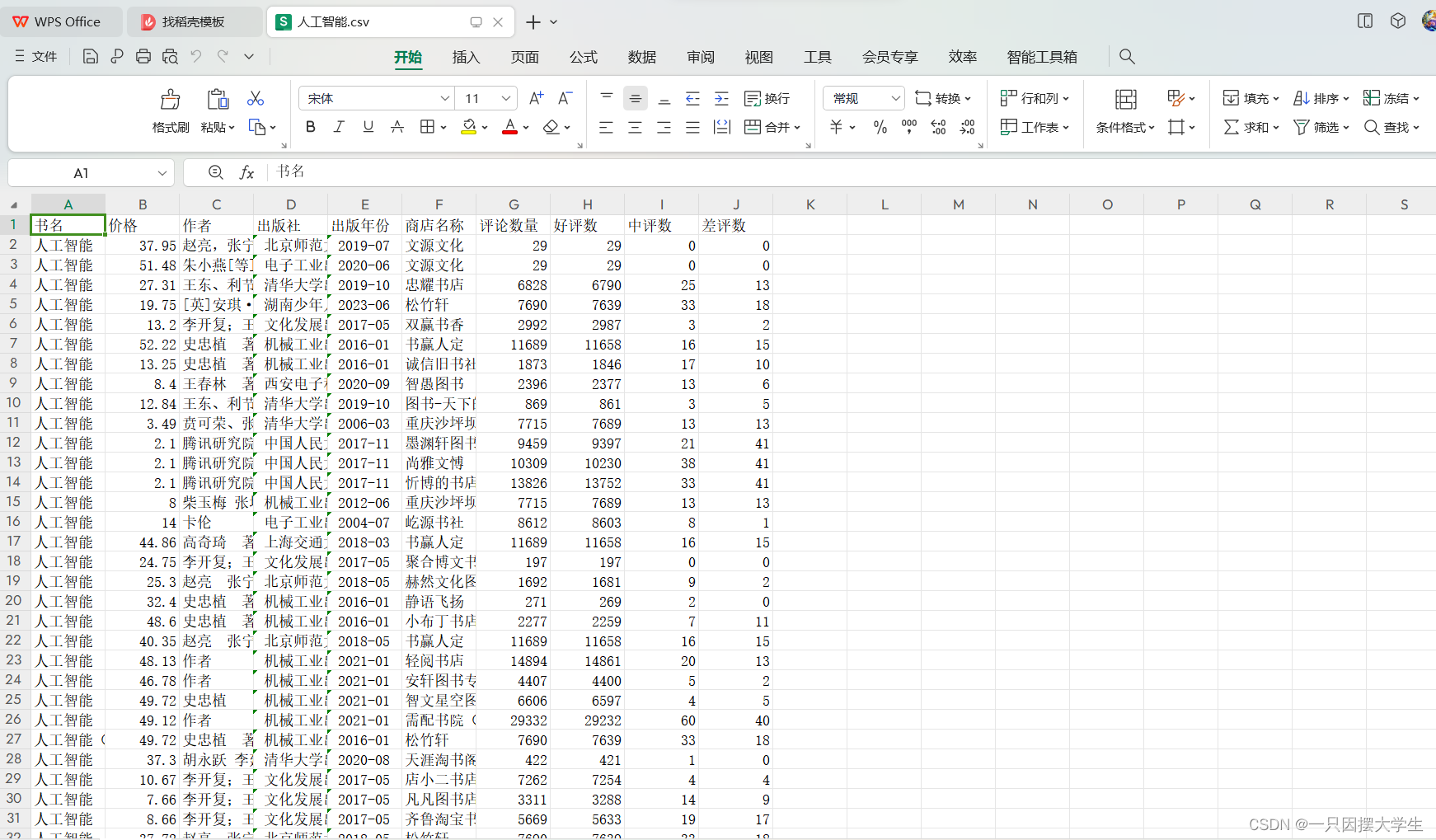
最终效果如图:

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









