






 本文介绍了一个Python脚本,通过requests和BeautifulSoup库抓取当当网上关于人工智能书籍的信息,包括书名、价格、评论数、作者、出版年份和出版社,支持并发爬取100页数据并保存为CSV。
本文介绍了一个Python脚本,通过requests和BeautifulSoup库抓取当当网上关于人工智能书籍的信息,包括书名、价格、评论数、作者、出版年份和出版社,支持并发爬取100页数据并保存为CSV。
源码如下,基本不会触发风控,默认爬取100页,可在末尾调整爬取参数:
import re
import concurrent.futures
import pandas as pd
from time import sleep
from bs4 import BeautifulSoup
import requests
def process_book(book):
try:
title = book.find("a", class_="pic").img.get("alt", "")
price = float(book.find("span", class_="search_now_price").get_text(strip=True).replace("¥", ""))
rating_text = book.find("a", class_="search_comment_num").get_text(strip=True)
rating_count = int(re.search(r"\d+", rating_text).group()) if re.search(r"\d+", rating_text) else 0
author_info = book.find("p", class_="search_book_author").get_text(strip=True).split("/")
author = author_info[0] if len(author_info) > 0 else ''
publish_date = author_info[1] if len(author_info) > 1 else ''
publisher = author_info[2].split("加")[0] if len(author_info) > 2 else ''
return [title, price, rating_count, author, publish_date, publisher]
except (AttributeError, ValueError, IndexError):
return None
def fetch_page(page, url_template, headers, keyword, total_pages):
url = url_template.format(page=page, keyword=keyword)
response = requests.get(url, headers=headers)
sleep(5)
soup = BeautifulSoup(response.text, "html.parser")
books = soup.find_all("li", class_=re.compile("line\d+"))
return [process_book(book) for book in books if process_book(book) is not None]
def fetch_data(keyword, total_pages):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"
}
url_template = "http://search.dangdang.com/?key={keyword}&page_index={page}"
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
pages_data = list(executor.map(fetch_page, range(1, total_pages + 1), [url_template] * (total_pages + 1), [headers] * (total_pages + 1), [keyword] * (total_pages + 1), [total_pages] * (total_pages + 1)))
data = [item for sublist in pages_data for item in sublist] # flatten the list
df = pd.DataFrame(data, columns=["书名", "价格", "评论数", "作者", "出版年份", "出版社"])
for _, row in df.iterrows():
print("书名:", row["书名"].encode('gbk', 'ignore').decode('gbk'))
print("价格:", row["价格"])
print("评论数:", row["评论数"])
print("作者:", row["作者"].encode('gbk', 'ignore').decode('gbk'))
print("出版年份:", row["出版年份"])
print("出版社:", row["出版社"].encode('gbk', 'ignore').decode('gbk'))
print("---------------------------------")
df.to_csv(f"{keyword}.csv", index=False)
# 定义要搜索的关键词和总页数
keyword = "人工智能" #爬取的书籍名称
total_pages = 100 # 请将这里替换为您希望爬取的总页数,最大100,因为当当最多100页,一页大概有50本书。
fetch_data(keyword, total_pages)
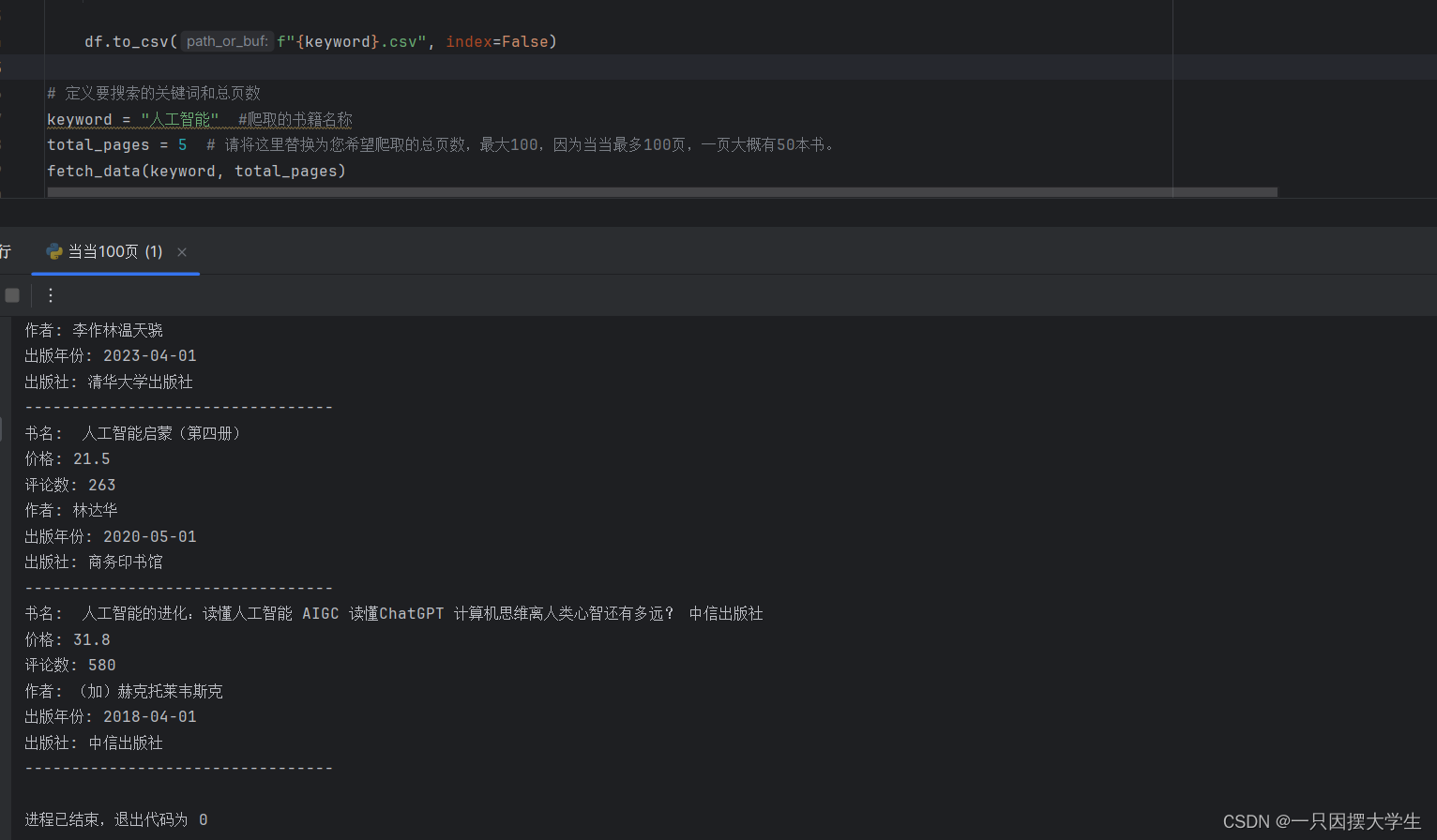
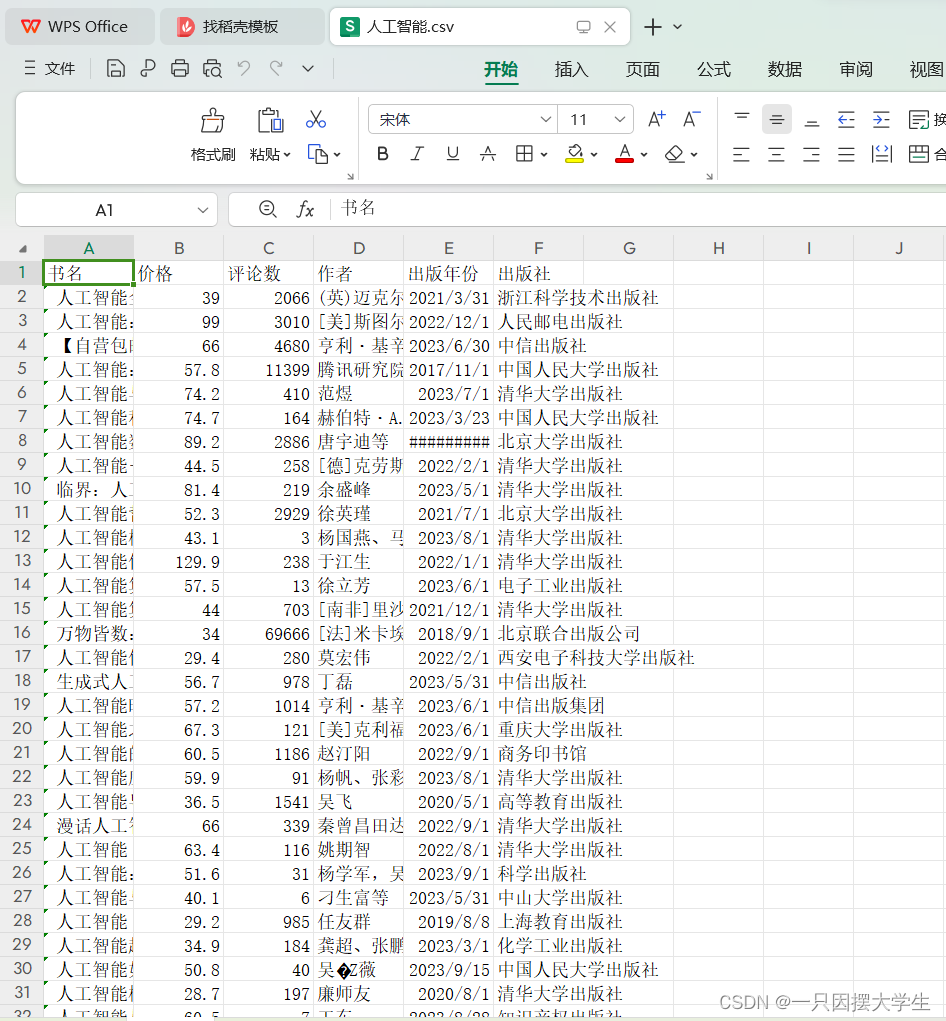
效果如图:
感谢采纳!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









