







目录
Preliminary: Stable Diffusion.
**IRControlNet-**条件编码 (Condition Encoding)
**IRControlNet-**条件网络 (Condition Network)
**IRControlNet-**特征调制 (Feature Modulation)
Abstract
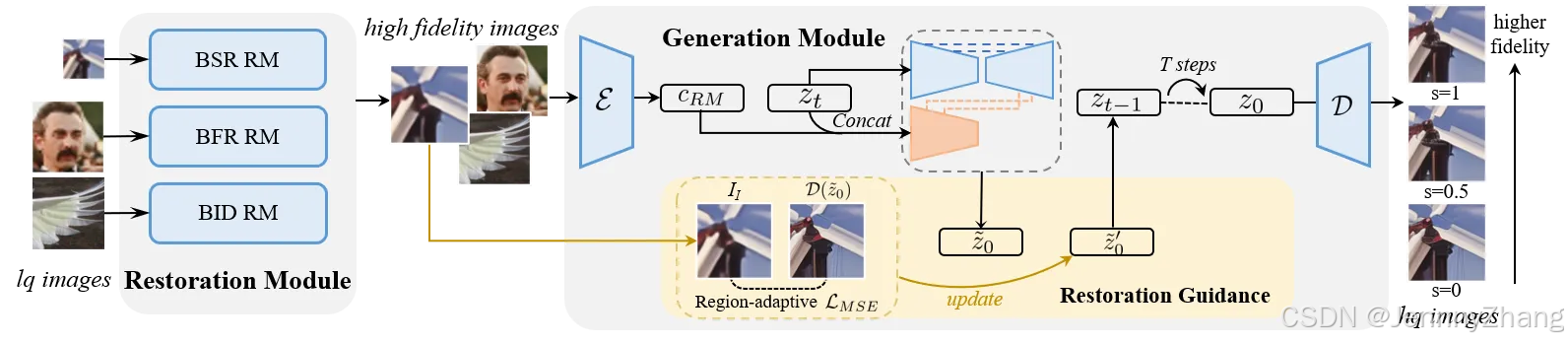
我们提出了DiffBIR,一个通用的恢复管道,可以处理不同的盲图像恢复任务,采用统一框架。DiffBIR将盲图像恢复问题分解为两个阶段:1)降级去除:去除与图像无关的内容;2)信息再生:生成缺失的图像内容。每个阶段都独立开发,但它们以级联的方式无缝协作。在第一阶段,我们使用恢复模块去除退化,获得高保真的恢复结果。在第二阶段,我们提出了IRControlNet,它利用潜在扩散模型的生成能力来生成真实的细节。具体而言,IRControlNet基于特别生成的条件图像进行训练,这些图像没有干扰性的噪声内容,从而实现稳定的生成性能。此外,我们设计了一种区域自适应恢复指导,可以在推理过程中修改去噪过程,而无需重新训练模型,允许用户通过可调的指导尺度来平衡真实感和保真度。大量实验表明,DiffBIR在盲图像超分辨率、盲人脸恢复和盲图像去噪任务上,相较于现有的最先进方法表现出明显的优越性,适用于合成和真实世界数据集。
Contribution
1. DiffBIR的设计
- 解耦BIR问题:DiffBIR将盲图像恢复(BIR)问题分为两个阶段:
- 恢复模块:负责去除图像中的退化成分。
- 生成模块:负责再生丢失的图像信息。
- 统一框架:这种两阶段的设计使DiffBIR能够在一个统一的框架内,首次在盲图像超分辨率(BSR)、盲面部恢复(BFR)和盲图像去噪(BID)任务中达到了最先进的性能。
2. IRControlNet的提出
- 利用扩散先验:论文提出了IRControlNet,它借助文本到图像的扩散先验来实现真实的图像重建。
- IRControlNet用于控制生成扩散先验,具体做法是使用预训练的变分自编码器(VAE)进行条件编码,并借鉴ControlNet的结构,通过附加和复制的编码器实现高效控制。
3. 可控模块的引入
- 无训练的可控模块:引入了一种区域自适应恢复指导模块,通过区域自适应恢复指导,利用设计的区域自适应MSE损失,在每个采样步骤中将生成结果与高保真指导图像进行比较,实现保真度与质量之间的权衡。低频区域更受高保真指导图像的影响,而高频区域则保持更多的生成能力。
- 用户偏好的灵活性:这种设计使得用户可以根据个人需求,在生成的图像质量和真实感之间找到平衡,提供了更高的控制能力。
Method
Restoration Module
- 去除降质:RM的主要目标是去除低质量(LQ)图像中的干扰性降质,恢复出高质量(HQ)图像,而不生成任何新的内容。
- 条件图像生成:RM不仅负责恢复图像,还生成适合用于训练生成模块的条件图像。这一过程确保生成模块可以在训练时获得可靠的输入。
采用均方误差(MSE)损失:RM模块使用经典的降质模型进行训练,目标是最小化恢复图像与高质量图像之间的MSE损失。具体的损失函数为:
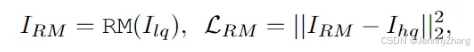
Generation Module
Preliminary: Stable Diffusion.
基于SD,Stable Diffusion 是一种潜在扩散模型,包含一个自动编码器(Autoencoder)。该自动编码器由编码器E和解码器D组成,主要功能是将图像x转换为潜在表示z,并能够将其重建回原始图像。
优化目标:潜在扩散模型的优化过程定义为:
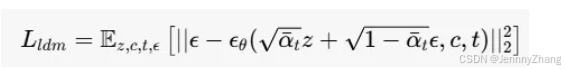
x 和 c 从数据集中采样,z=E(x),t 是均匀采样的时间步,ϵ 是从标准高斯分布采样的噪声。
**IRControlNet-**条件编码 (Condition Encoding)
-
VAE编码器:在IRControlNet中,我们使用预训练的变分自编码器(VAE)编码器 E 来将可靠的条件图像 IRM 编码到潜在空间中。公式为:
-
-
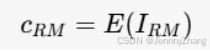
- 输出:cRM 是获得的条件潜在表示。由于VAE是在大规模数据集上训练的,因此可以保留足够的图像信息。
-
**IRControlNet-**条件网络 (Condition Network)
-
复制的UNet结构:条件网络采用了ControlNet的方法,创建了一个可训练的预训练UNet编码器和中间块的副本(记作 Fcond)。该副本接收条件信息,并输出控制信号。
- 权重初始化:这种复制策略为条件网络提供了良好的权重初始化。
-
输入处理:将条件潜在表示 cRM 和在时间 t 的噪声潜在表示 zt 进行连接,形成输入:
-
-
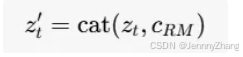 通道增加:连接操作(cat)会增加通道数,因此在 Fcond 的第一层引入了一些参数并将其初始化为零。零初始化的作用类似于ControlNet中的零卷积,旨在避免在训练初期随机噪声作为梯度。
通道增加:连接操作(cat)会增加通道数,因此在 Fcond 的第一层引入了一些参数并将其初始化为零。零初始化的作用类似于ControlNet中的零卷积,旨在避免在训练初期随机噪声作为梯度。
-
**IRControlNet-**特征调制 (Feature Modulation)
- 多尺度特征输出:条件网络输出多尺度特征,这些特征用于调制冻结的UNet去噪器的中间特征。
- 调制方法:仅调制中间块特征和跳跃特征,通过加法操作实现调制。
- 连接稳定性:为了提高模型训练的稳定性,引入零卷积将条件网络与固定的UNet去噪器连接。
- 训练过程:在训练期间,仅更新条件网络和特征调制的参数。
**IRControlNet-**优化目标
- 目标函数:优化的结果在这一阶段被表示为 *IGM,*生成模块的优化目标定义为:
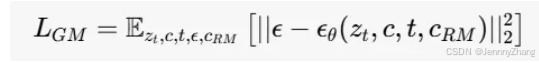
<aside> 💡
IRControlNet通过条件编码、条件网络和特征调制三个关键部分,有效地利用了稳定扩散模型(Stable Diffusion)来提升生成模块的性能。每个部分的设计都旨在提高模型的训练稳定性和生成效果,使其在处理图像恢复任务时更加高效和准确。
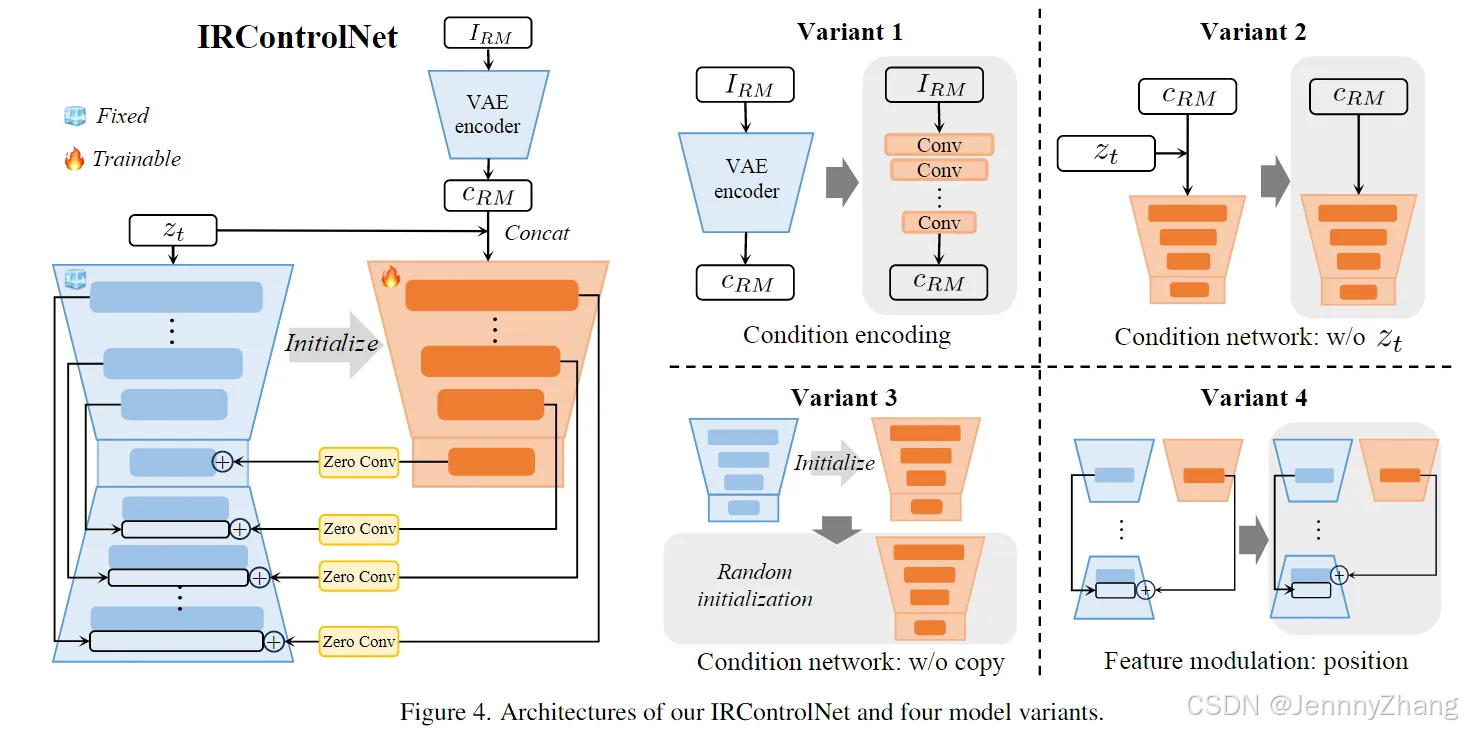
变体1(与ControlNet相同)
- 条件编码:使用一个小型的从零开始训练的网络替换IRControlNet的条件编码器 E,该网络由多个堆叠的卷积层和一个零卷积层组成。
- 输入处理:将编码后的条件添加到条件网络第一层的输出特征中。
- 表现:与IRControlNet进行比较,发现变体1无法保持输入低质量图像的原始颜色,其定量结果在PSNR(峰值信噪比)上显著低于IRControlNet,平均下降约3dB。
变体2(不使用 zt)
- 条件网络:移除噪声潜在表示 zt,仅使用条件潜在表示 cRM 作为条件网络的输入。
- 训练损失:变体2的训练损失在所有训练轮次中始终高于IRControlNet。这表明,添加噪声潜在表示 zt 有助于模型的收敛,因为它使条件网络在每个时间步都能感知随机性,从而提高模型预测的准确性。
- 性能对比:
- 在测量保真度的指标上,变体2表现最佳,但其图像质量评估(IQA)得分低于IRControlNet。
- 定性结果显示,变体2通常生成平滑的结果,但缺乏足够的纹理细节。
变体3(随机初始化条件网络)
- 条件网络:不从UNet去噪器复制原始权重,而是从随机初始化开始训练条件网络。
- 训练损失收敛:变体3在训练损失收敛方面表现较差,且在所有指标中表现最差。
- 结论:条件网络的良好权重初始化对生成模块至关重要。
变体4(控制中间块特征和解码器特征)
- 特征调制:控制中间块特征和解码器特征,而不是跳跃连接的特征。
- 收敛速度和性能:变体4在收敛速度和定量结果上与IRControlNet相当,表明对跳跃连接特征或解码器特征的控制具有类似的效果。
- 参数和计算开销:由于解码器特征的通道数约为对应跳跃特征的两倍,这将引入更多参数和计算负担。因此,IRControlNet在跳跃特征上的特征调制已足够。
观察结论:条件编码在控制潜在扩散先验方面起着至关重要的作用。因为图像生成过程是在潜在空间中进行的,因此条件信息也必须投影到同一空间中。
Restoration Guidance
1. 设计目标
- 可控模块:恢复指导模块允许用户根据需求调整生成图像的细节程度。在高频区域(如纹理、边缘)中,用户通常希望生成更多细节;而在平坦区域(如天空、墙壁)中,希望生成的内容较少。
2. 区域自适应恢复指导
- 指导过程:该模块通过区域自适应的方式,指导去噪过程朝着高保真度的条件图像 IRM 进行,引导生成的结果。
- 可调节的指导尺度:用户可以控制指导的强度,适用于每个采样步骤,且该过程是无训练的。
3. 去噪过程
-
噪声预测:在时间步 t 时,UNet去噪器首先预测噪声 ϵt:
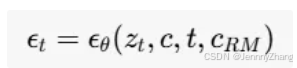
-
去除噪声:然后,从噪声潜在表示 zt 中去除预测的噪声,以获得干净的潜在表示 z~0:
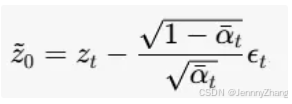
4. 区域自适应均方误差(MSE)损失函数
- 损失函数目标:在这一阶段的目标是引导去噪器的输出 D(z~0) 向高保真度条件图像 IRM 靠近。
- 计算梯度:计算梯度幅值使用了Sobel算子。由于图像中强梯度信号的像素非常稀少,故将 IRM 划分为多个不重叠的补丁,以计算每个补丁的梯度幅值 G(IRM) 以更好地估计梯度密度。
5. 权重映射和损失函数
-
权重映射:利用梯度幅值计算权重映射:
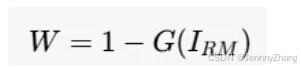
-
自适应损失函数:调整后的MSE损失函数定义为:其中 H、W、C 分别表示图像的空间尺寸。
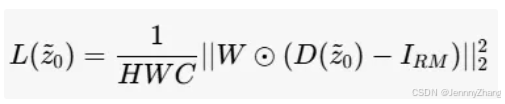
6. 影响机制
- 低频区域:在梯度信号较弱的区域,赋予更大的权重,意味着低频区域会诱导更高的损失,因此更受高保真度条件图像的影响。
- 高频区域:相反,高频区域受到的影响较小,可以在采样过程中保留更多生成内容。
7.优化过程
-
梯度下降算法:在每个采样步骤 t 中,使用梯度下降算法优化区域自适应均方误差(MSE)损失。更新公式为:
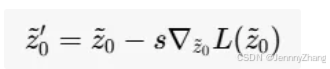
- 参数说明:
- z~0′z~0′:更新后的干净潜在表示。
- ss:指导尺度,控制从指导图像 IRM 中保留的信息量。
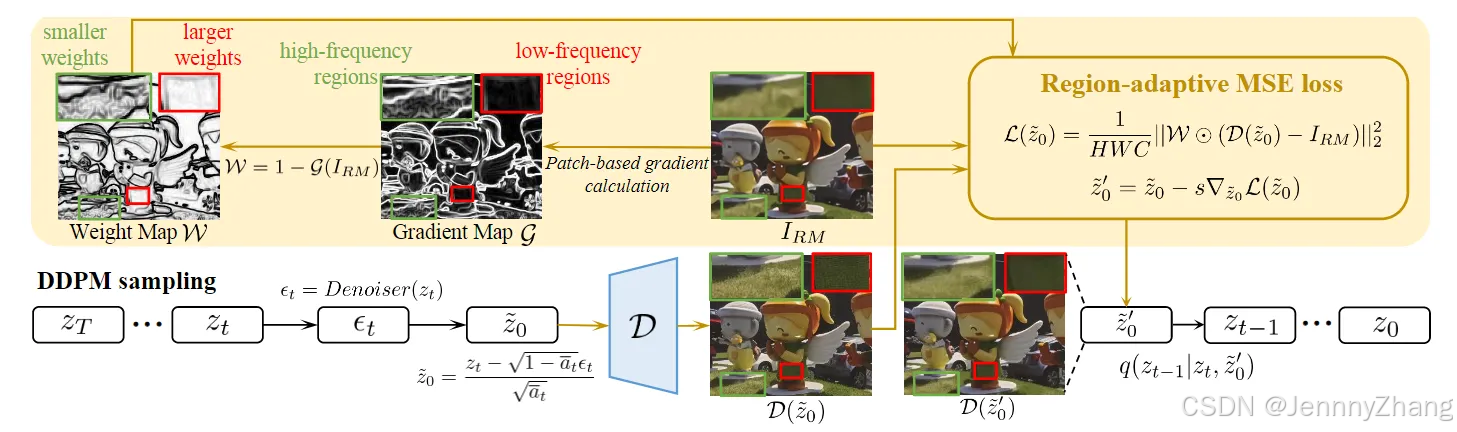
- 参数说明:
恢复指导模块通过区域自适应的方式,有效地平衡了生成图像的质量和细节。通过调整损失函数,使得低频和高频区域在生成过程中得到不同的关注,从而实现更高质量的图像恢复。这一设计为用户提供了更大的控制权,能够根据具体需求生成满足期望的图像。
Experiment
1. 数据集
- 训练数据集:DiffBIR在过滤后的laion2b-en数据集上训练,该数据集包含约150万张高质量图像。训练时,所有图像均随机裁剪为512 × 512的尺寸。
- 评估任务:
- BSR任务:在三个合成数据集(DIV2K-Val、DRealSR、RealSR)和两个真实世界数据集(RealSRSet和自收集数据集)上进行评估。
- BFR任务:在真实世界数据集(LFW-Test和WIDER-Test)上进行评估。
- BID任务:在一个混合真实世界数据集上评估,该数据集包含来自real3、real9和RNI15的数据。
2. 实现细节
- 训练过程:
- 恢复模块:训练150k次迭代(批量大小为96)。
- IRControlNet微调:采用Stable Diffusion 2.1-base作为生成先验,微调IRControlNet 80k次迭代(批量大小为256)。
- 优化器:使用Adam优化器,前30k次迭代的学习率设置为10⁻⁴,之后降低到10⁻⁵,持续50k次迭代。
- 硬件:训练在8个NVIDIA A100 GPU上进行,分辨率为512 × 512。
- 推理过程:
- 在推理时,使用特定任务的现成恢复模型替换训练好的恢复模块:
- BSR:使用BSRNet。
- BFR:使用在DifFace中使用的SwinIR。
- BID:使用SCUNet-PSNR。
- IRControlNet保持不变,负面提示使用“low quality”和“blurry”等文本,正面提示设置为空。
- 恢复指导尺度:在合成数据集上设置为0、0.5和1进行比较,真实场景中设置为0以获得更高质量。
- 采样过程:采用间隔DDPM采样调度,需要50个采样步骤。对于边长大于512的图像,直接输入DiffBIR;对于边长小于512的图像,先将短边放大到512,然后在恢复后调整回原始尺寸。
- 在推理时,使用特定任务的现成恢复模型替换训练好的恢复模块:
3. 评估指标
- 合成数据评估:采用传统指标:
- PSNR(峰值信噪比)
- SSIM(结构相似性指数)
- LPIPS(感知图像差异)
- 无参考图像质量评估:
- MANIQA
- MUSIQ
- CLIP-IQA
- BFR评估:采用广泛使用的感知指标FID(Fréchet Inception Distance)。
VS StableSR
-
额外多了一个SwinIR 作为第一阶段的网络结构,第一阶段先把退化(噪声,artifacts)去掉得到一个相对干净的图片,然后用diffusion模型的先验信息去做细节补充(超分)。
-
StableSR使用的是自己设计的支路去做LR信息的注入,DIffBIR使用的是controlNet, ControlNet的是复制了Diffusion的unet的encoder部分(Parallel Module),增加几层zeroConv(初始化为0 的1x1卷积),然后加到decoder的特征里去。这样的做法是Parallel Module是一个预训练好的模型,finetune能很快出一个很好的结果。
-
Parallel Module 会额外把 zt 作为额外输入,感觉能让Parallel Module支路的给的信息更合理
-
保真度-真实性权衡的潜在图像引导
Idea
DiffBIR的第一个阶段,先把图像退化去掉一部分,这样的好处是后续的diffsion网络看到的图像的退化没那么严重,一致性较好,训练起来难度变小。但是这样一来,前面的网络的计算代价也不小,而且有可能导致一些信息的损失。实测看, DiffBIR的保真度要比StableSR好一些,但是仍然有比较多的乱生成的现象,解决方案如下:
1. **多尺度处理:**在第一阶段引入多尺度特征提取,分别处理不同尺度的信息,以保留更多细节和全局上下文。这样可以在去噪的同时尽量减少信息损失。
2. **增强训练数据:**使用数据增强技术,比如随机裁剪、旋转、亮度调整等,增加模型的鲁棒性。这样可以帮助模型更好地学习多样化的图像特征,从而减少乱生成的现象。
3. 改进损失函数:设计更复杂的损失函数,如结合感知损失和对抗损失,以提高生成图像的质量。感知损失可以帮助模型关注图像的高层次特征,而对抗损失则可以提高生成图像的真实感。
4. 引入注意力机制:在网络中引入注意力机制,让模型能够关注重要的特征区域,从而减少无关信息的干扰。这可以提高生成图像的细节保留。
5. 逐步恢复:将图像恢复任务分解为多个小任务,逐步恢复图像的细节。比如,先恢复低频细节,再逐步引入高频细节,这样可以控制生成的复杂性,减少不必要的乱生成。
6. 后处理步骤:在生成图像后,应用后处理步骤,比如使用去噪算法或超分辨率模型进一步增强图像质量。这可以帮助修复在恢复过程中产生的伪影和细节损失。
7. 调整模型架构:考虑改进网络结构,比如增加深度或宽度,以提升模型的表达能力。这可能有助于捕捉更复杂的特征,从而减少生成的混乱。


















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









