







目录
SparkStreaming/StructuredStreaming
SparkStreaming/StructuredStreaming
- sprark提供实时计算的模块:SparkStreaming、StructuredStreaming
- 实时处理(来一条数据处理一条数据)
- storm
- flink
- event
- 技术选型
- 生产上使用
- SparkStreaming、StructuredStreaming :10%
- flink :90% 【开发角度来说简单】
- storm :2%
- 业务
- 1.实时指标:差不多
- 2.实时数仓
- 1.代码 【不好维护】
- 2.sql文件:flinksql维护实时数仓
- 生产上使用
- 1.流处理/实时计算
- 并非真正的实时处理,是近实时处理,来一批数据处理一批数据 远远不断的来
- 2.批处理/离线计算
- 一次性处理某一个批次的数据 数据是有始有终的
1.SparkStreaming

-
1.数据源
- kafka :流式引擎 + kafka
- flume :可以使用,没有数据缓冲作用,一般不用
- hdfs :很少使用
- tpc sockets :测试 + 运营商数据(很早前使用的)
-
2.SparkStreaming运行:
- 1.receives live input data streams 接收数据
- 2.divides the data into batches 把接收数据 拆分成batches
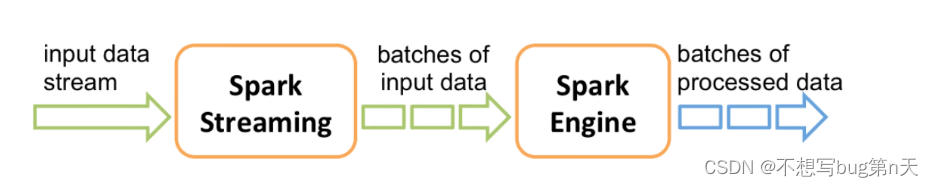
- sparkstreaming=》 kafka
- 1.5s钟处理一次数据
- 2.会5s接收的数据切分成batch
- 3.把batch 交给sparkengine 处理
- 4.处理完结果·也是·batch
-
3.流式处理:
- 对Dstream进行转换操作
- 实际上就是对Dstream里面的rdd进行操作
- 对rdd进行操作就是对rdd里面分区的元素进行操作
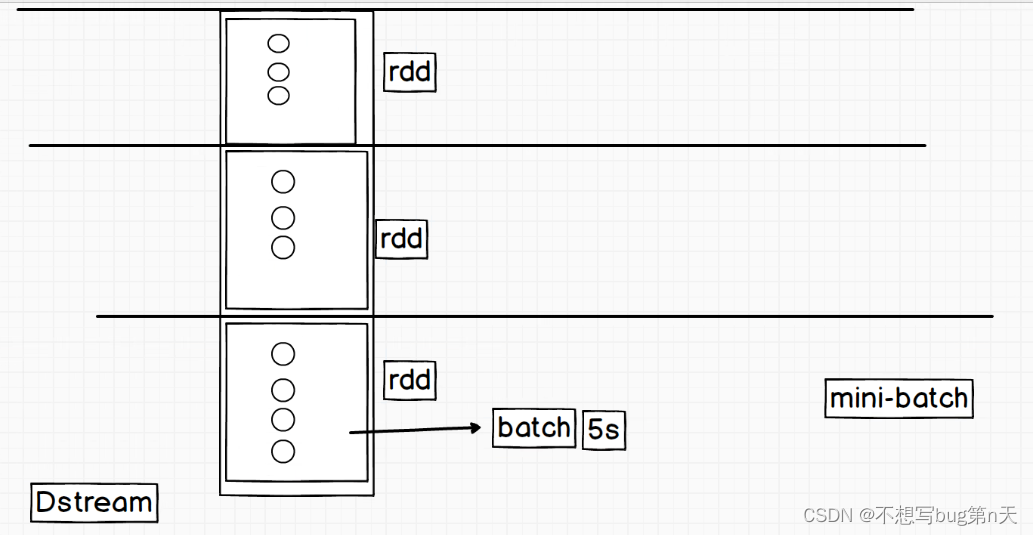
- 总结:程序入口
- sparkstreaming :StreamingContext
- sparkcore: sparkcontext
- sparksql: sparksession
-
4.作业运行
- 官网:spark.apache.org/docs/latest/streaming-programming-guide.html#overview
-
1.idea加依赖
<!--sparkstreaming 依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>3.2.1</version> </dependency> -
2.xshell操作
- 1.进入spark
- 2.导包
import org.apache.spark._ import org.apache.spark.streaming._ import org.apache.spark.streaming.StreamingContext._ - 3.构建StreamingContext
val ssc = new StreamingContext(sc, Seconds(5))// Seconds(5) :每隔5s运行一次

- 4.加载数据源
val lines = ssc.socketTextStream("localhost", 9999) - 5.添加转换操作
val words = lines.flatMap(_.split(" ")) val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _) wordCounts.print() - 6.准备数据源
- [hadoop@bigdata13 ~]$ nc -lk 9999
- 7.作业启动
ssc.start() ssc.awaitTermination()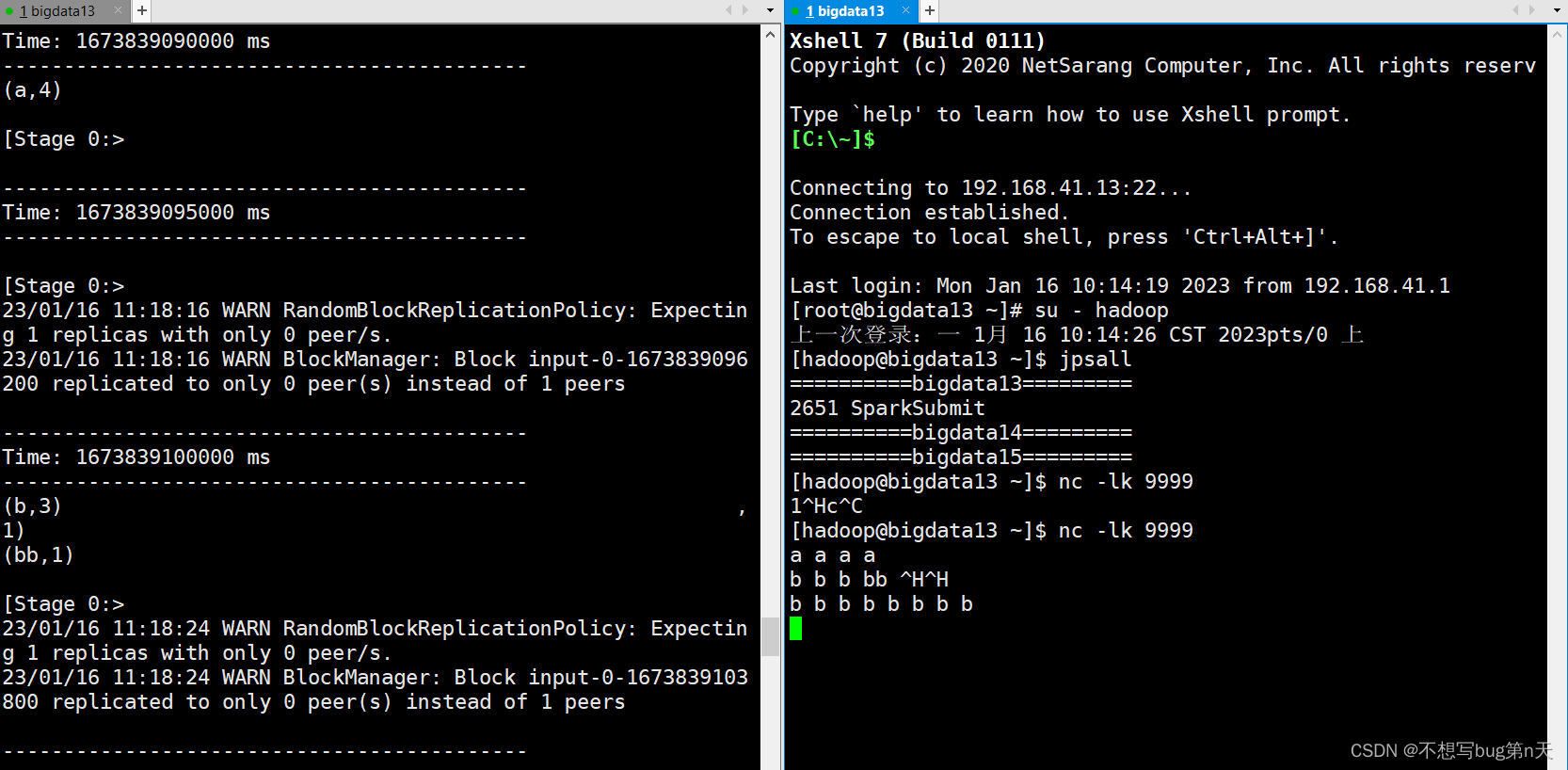
如果没有数据就空跑 - 8.查看job:bigdata13:4040
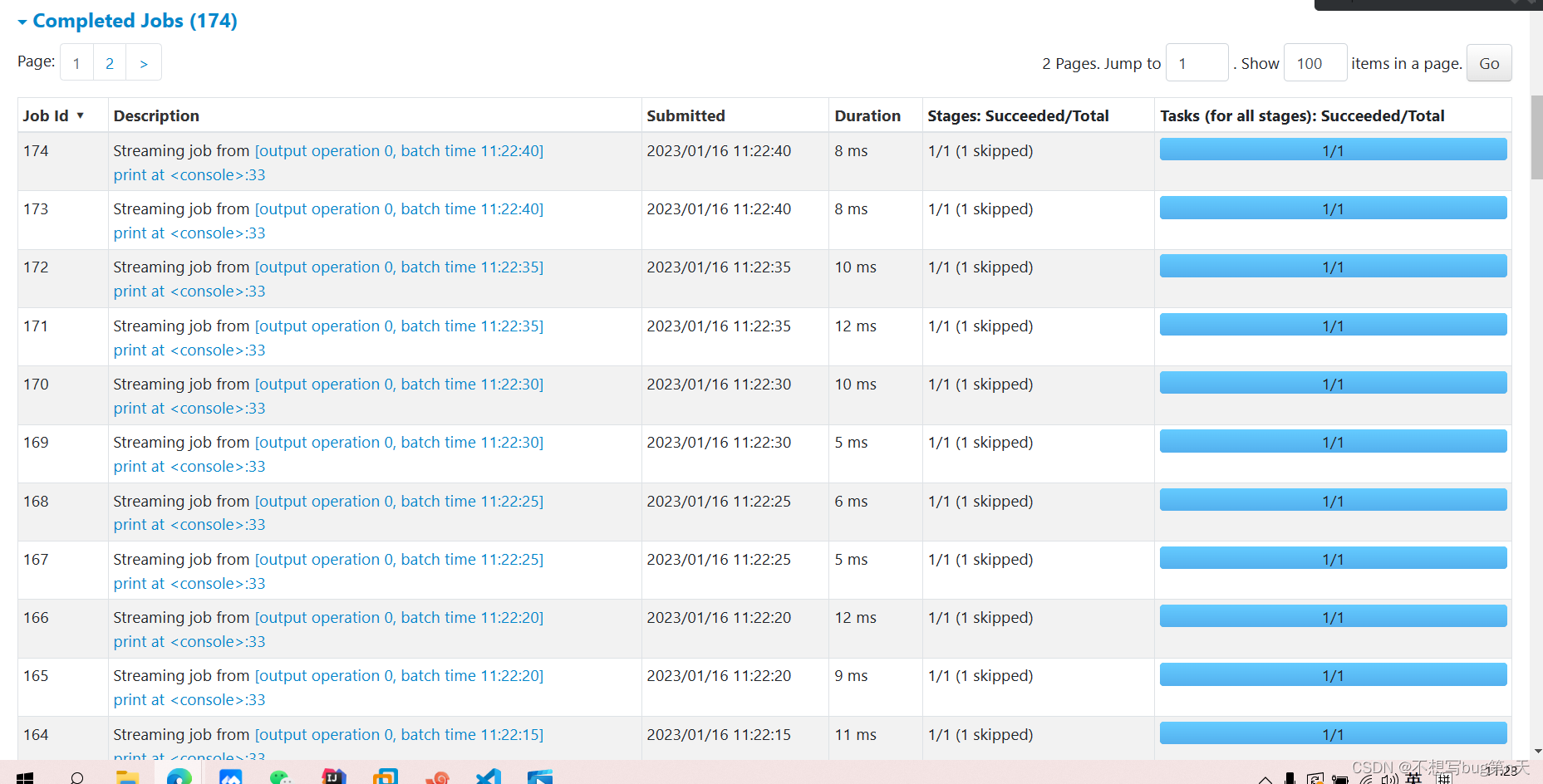
6条有效数据
- 有效数据
- 有效数据
-
3.idea使用
object SSSS { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[2]").setAppName("SSSS") val ssc = new StreamingContext(conf, Seconds(10)) val lines = ssc.socketTextStream("bigdata13",9998) val words = lines.flatMap(_.split(" ")) val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _) wordCounts.print() ssc.start() ssc.awaitTermination() } }[hadoop@bigdata13 ~]$ nc -lk 9998

- 多个端口连接
def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[4]").setAppName("SSSS") val ssc = new StreamingContext(conf, Seconds(10)) val lines = ssc.socketTextStream("bigdata13",9998) val lines1 = ssc.socketTextStream("bigdata13",9997) val lines2 = ssc.socketTextStream("bigdata13",9996) val words = lines.flatMap(_.split(" ")) val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_ + _) wordCounts.print() lines1.print() lines2.print() ssc.start() // Start the computation ssc.awaitTermination() // Wait for the computation to terminate }

- 多个端口连接
2.算子
1.转换算子
-
1.transform
- transform:DStream 和 rdd之间数据进行交换的算子
- 处理需求
- 一个数据来自mysql数据/hdfs上文本数据 【最小】围标
- 一个数据来自于kafka sss读取形成DStream数据【最大】主业务
-
案例:弹幕过滤的功能/黑名单功能
- 离线
object SparkSQLCoreBlockListApp { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder().appName("SparkSQL01").master("local[2]").getOrCreate() val sc = spark.sparkContext val log = sc.parallelize(List( "good", "演技好好", "爱了爱了", "哭死", "真帅", "丑死了", "退出娱乐圈", "黑子" )) val black = sc.parallelize(List( "丑死了", "退出娱乐圈", "黑子" )) val log_kv = log.map(line => (line, 1)) val black_kv = black.map(line => (line, true)) log_kv.leftOuterJoin(black_kv) .filter(_._2._2.getOrElse(false) != true) .map(_._1).foreach(println(_)) spark.stop() } }
- 实时
object SparkStreamingSQLCoreBlockListApp { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[2]").setAppName("SSSS01") val ssc = new StreamingContext(conf, Seconds(10)) val sc = ssc.sparkContext val logs: ReceiverInputDStream[String] = ssc.socketTextStream("bigdata13", 9527) val black = sc.parallelize(List( "丑死了", "退出娱乐圈", "黑子" )) //弹幕显示 val log_kv = logs.map(word => (word, 1)) val black_kv = black.map(line => (line, true)) val result = log_kv.transform(rdd => { rdd.leftOuterJoin(black_kv) .filter(_._2._2.getOrElse(false) != true) .map(_._1) }) result.print() ssc.start() ssc.awaitTermination() } }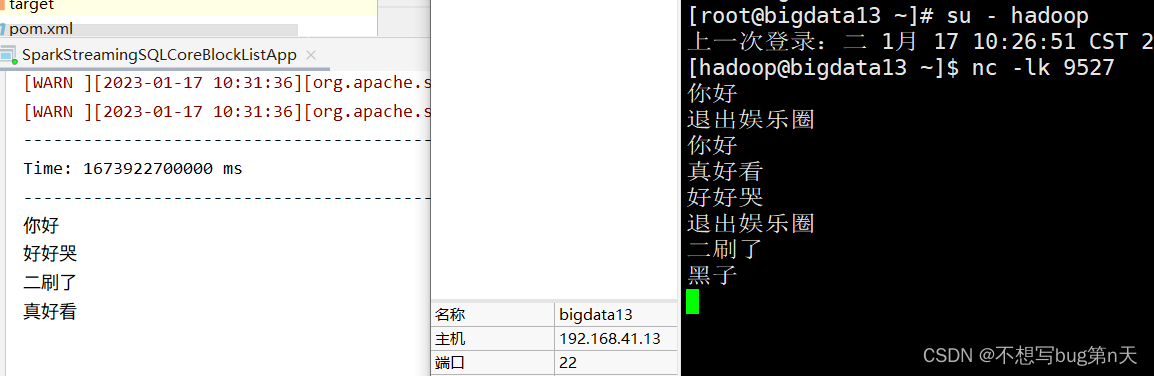
- 离线
-
2.updataStateByKey
- 用于解决有状态问题
-
案例:累计问题
- 统计 从现在时间点开始 b出现的累计次数?
- 代码
object SSS01 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[2]").setAppName("SSSS01") val ssc = new StreamingContext(conf, Seconds(10)) //指定checkpoint ssc.checkpoint("file:///D:\\iccn\\software\\xxl\\untitled3\\untitled5\\Data\\checkpoint") val lines = ssc.socketTextStream("bigdata13", 9999) val words = lines.flatMap(_.split(" ")) val pairs = words.map(word => (word, 1)) val wordCounts = pairs.updateStateByKey(updateFunction) wordCounts.print() ssc.start() ssc.awaitTermination() } def updateFunction(newValues: Seq[Int], preValues: Option[Int]): Option[Int] = { // newValues : (a,1)(a,1)(a,1) => a,<1,1,1> // preValues : none val curr_sum = newValues.sum val pre_sum = preValues.getOrElse(0) Some(curr_sum+pre_sum) } }

- 总结
- 1.指定checkpoint:维护当前批次和以前的累计批次的数据state
- 2.checkpoint目录生产上得指定到hdfs上进行存储
- 存在问题:checkpoint每个批次都会产生文件(hsfs扛不住)
-
checkpoint的作用
- (针对sparkstreaming来说)【生产上不能用】
- 1.作用
- 1.维护状态
- 2.为了容错
- 3.恢复实时计算作业【挂掉之后可以恢复起来】
- 2.两大类数据【checkpoint的存储】
- 1.Metadata 元数据
- Configuration 【作业中的配置文件】
- DStream operations 【作业code中的操作算子】
- Incomplete batches 【未完成的批次】
- 2.Data
- 每个批次中真正传过来的数据和状态
- 1.Metadata 元数据
- 3.使用checkpoint的时间点
- 1.使用带有状态的转换算子
- 2.恢复作业时使用
- 4.checkpoint的使用
object SSS02 { def main(args: Array[String]): Unit = { val checkpointDirectory="file:///D:\\iccn\\software\\xxl\\untitled3\\untitled5\\Data\\checkpoint01" val ssc = StreamingContext.getActiveOrCreate(checkpointDirectory,functionToCreateContext) ssc.start() ssc.awaitTermination() } def functionToCreateContext(): StreamingContext = { val conf = new SparkConf().setMaster("local[2]").setAppName("SSSS02") val ssc = new StreamingContext(conf, Seconds(10)) ssc.checkpoint("file:///D:\\iccn\\software\\xxl\\untitled3\\untitled5\\Data\\checkpoint01") val lines = ssc.socketTextStream("bigdata13", 9999) val words = lines.flatMap(_.split(" ")) val pairs = words.map(word => (word, 1)).map(x=>(x._1,2)) val wordCounts = pairs.updateStateByKey(updateFunction) wordCounts.print() ssc } def updateFunction(newValues: Seq[Int], preValues: Option[Int]): Option[Int] = { // newValues : (a,1)(a,1)(a,1) => a,<1,1,1> // preValues : none val curr_sum = newValues.sum val pre_sum = preValues.getOrElse(0) Some(curr_sum+pre_sum) } }重新启动后数据也还存在
- 6.checkpoint缺点:
- 1.小文件多
- 2.修改代码程序就用不了【修改业务逻辑代码】
- checkpoint 用不了生产上 =>累计批次指标统计问题 updateStateByKey这个算子 也用不了
- 7.实现累计批次统计需求
- 一: 100%来处理
- 1.把每个批次数据 写到外部存储
- 2.然后利用外部存储系统再统计即可
- 二:90%都没有解决
checkpoint 【解决 checkpoint 导致修改代码 报错问题+小文件问题解决】
- 一: 100%来处理
2.输出算子
-
1.print
-
2.foreachRDD 【写出数据】
-
案例:将wc案例结果写到mysql中
- 1.在mysql中建表
create table wc( word varchar(10), cnt int(10) );在bigdata数据库中
- 2.idea中建立与mysql连接
import java.sql.{Connection, DriverManager} object MySQLUtil { /** * 获取mysql 连接 * @return */ def getConnection()={ Class.forName("com.mysql.jdbc.Driver") DriverManager.getConnection("jdbc:mysql://bigdata13:3306/bigdata","root","123456") } /** * 关闭mysql 连接 * @param connection */ def closeConnection(connection: Connection)={ if (connection !=null){ connection.close() } } } - 3.初步写出代码
object SSSS3 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local[2]").setAppName("SSSS3") val ssc = new StreamingContext(conf, Seconds(10)) val lines = ssc.socketTextStream("bigdata13",9998) val words = lines.flatMap(_.split(" ")) val pairs = words.map(word => (word, 1)) val wordCounts = pairs.reduceByKey(_+_) wordCounts.print() //output:data => mysql wordCounts.foreachRDD({ rdd => rdd.foreach(pair => { val conn: Connection = MySQLUtil.getConnection() //val sql = s"inster into wc(word,cnt) values('${pair._1}','${pair._2}')" val sql=s"insert into wc(word,cnt) values('${pair._1}','${pair._2}')" conn.createStatement().execute(sql) //数据写出 conn.close() //关闭连接 }) }) ssc.start() ssc.awaitTermination() } }
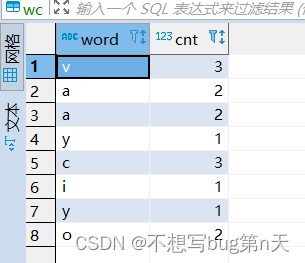
- 4.优化mysql连接次数
- 1.rdd.foreachPartition
- mysql 连接次数 会减少 rdd有多少个分区 就有多少个连接【生产上用它足够】
wordCounts.foreachRDD({ rdd => //减少mysql连接 高效 //rdd.coalesce(10).foreachPartition(规定分区数) rdd.foreachPartition(partion => { val conn: Connection = MySQLUtil.getConnection() partion.foreach(pair =>{ val sql=s"insert into wc(word,cnt) values('${pair._1}','${pair._2}')" conn.createStatement().execute(sql) //数据写出 }) conn.close() //关闭链接 }) })
- mysql 连接次数 会减少 rdd有多少个分区 就有多少个连接【生产上用它足够】
- 2.使用连接池
- 1.rdd.foreachPartition
- 5.sparksql的方式写出【推荐】
//output:data => mysql wordCounts.foreachRDD({ rdd => // sparksql 的方式写出 推荐 val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate() import spark.implicits._ val df = rdd.toDF("word","cnt") df.printSchema() df.show() val url="jdbc:mysql://bigdata13:3306/bigdata" val table="wc" val properties = new Properties() properties.setProperty("user", "root") properties.setProperty("password", "123456") df.write.mode(SaveMode.Append).jdbc(url,table,properties) })

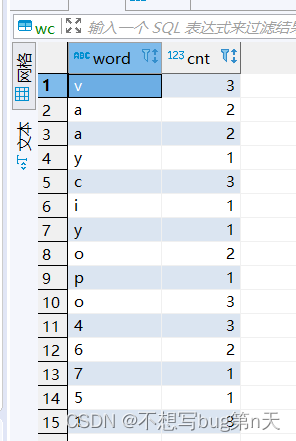
- 1.在mysql中建表
-

















 4514
4514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









