




 本文详细介绍了Linux下的三个强大文本处理工具grep(过滤)、sed(增删改查)和awk(按行取列),包括它们的主要作用、选项和用法,以及正则表达式的应用实例。
本文详细介绍了Linux下的三个强大文本处理工具grep(过滤)、sed(增删改查)和awk(按行取列),包括它们的主要作用、选项和用法,以及正则表达式的应用实例。
Linux文本三剑客:
grep、sed、awk
grep
- 作用:过滤文本内容
- 选项
- -m #:匹配几次之后就停止(#的位置填入数字),按行匹配,一行算一次,不是一个字符算一次

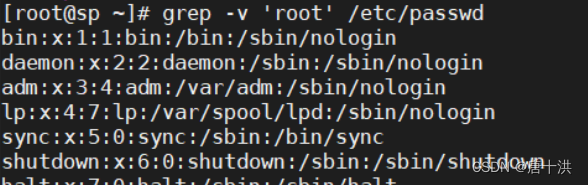
- -v:取反,就是匹配到的不需要
- -n:显示匹配的行号

- -c:显示匹配的行的数量

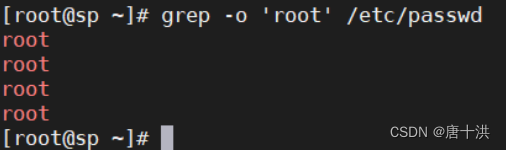
- -o:只显示匹配到的内容,不显示其他内容
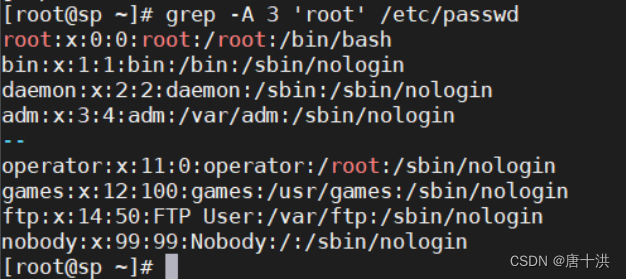
- -A #:after,显示目标行以及之后的几行(#处填入数字)
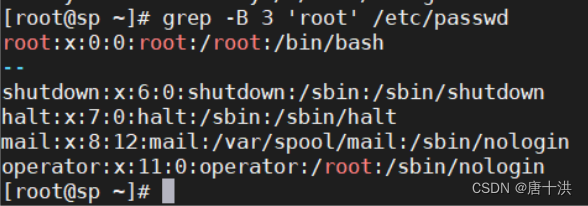
- -B #:before,显示目标行以及之前的几行(#处填入数字)
- -C #:显示目标行以及前后几行(#处填入数字)
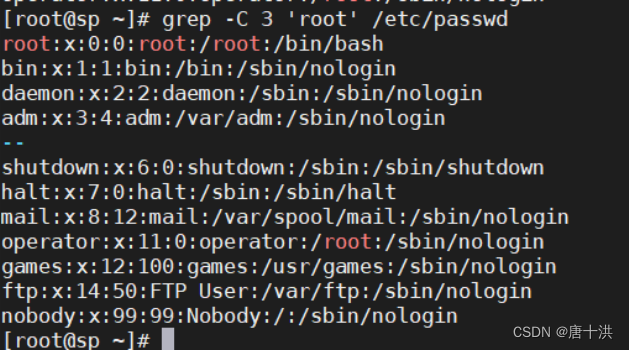
- -e:实现多个过滤条件之间的逻辑或关系
- -w:匹配整个单词

- -E:使用扩展正则表达式
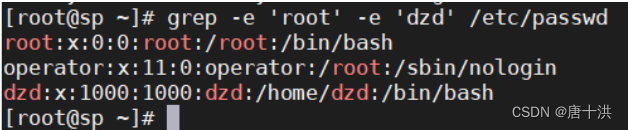
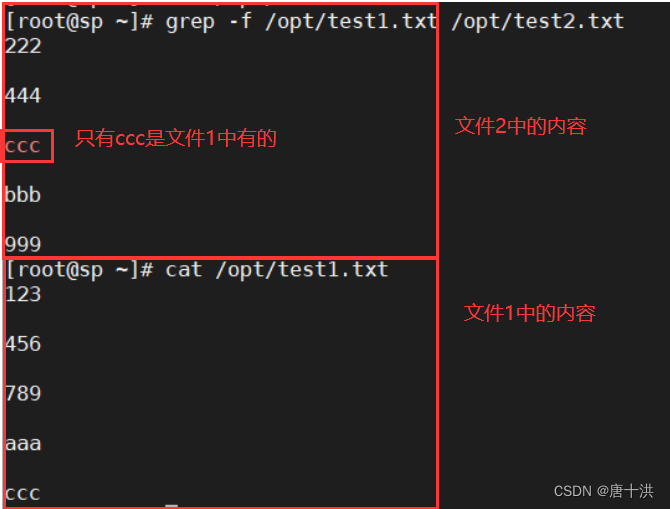
- -f:文件模式进行匹配,匹配两个文件的相同的内容,以第一个文件作为参照,显示第二个文件中相匹配的内容
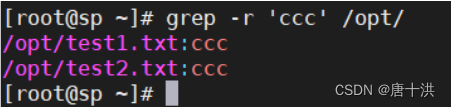
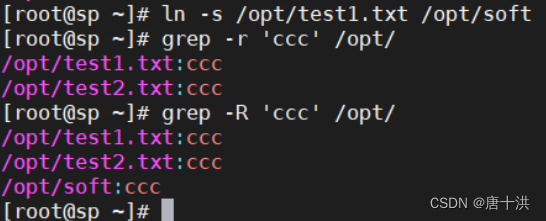
- -r:递归目录,但是不处理软链接。还是匹配目录中的文本的内容
- -R:递归目录,处理软链接
- -m #:匹配几次之后就停止(#的位置填入数字),按行匹配,一行算一次,不是一个字符算一次
sed
- 作用:主要是对文本内容的增删改查
- 注意点:sed是一种流编辑器,除非确认了对文本的操作,否则文件中实际的数据并不会改变。如果不确认操作,展示结束后,缓冲区中的数据会立刻销毁,如果确认了操作,才会实际上对硬盘进行写入。
- 选项
- -e:指定命令来处理输入的文本文件,类似于grep中的-e,只有一个操作命令的话,-e可以不写
- -f:用指定文件中的脚本来对另一个文件进行处理(不常用)
- -i:命令会直接生效,实际上地对硬盘进行写入
- -n:屏蔽默认输出,只显示一条结果
- 操作命令
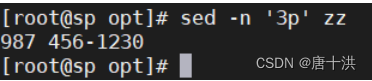
- p:打印,3p表示打印第3行
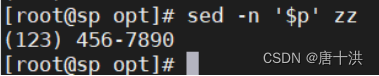
- $p:打印最后一行
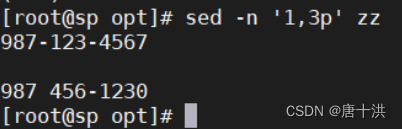
- 2,6p:打印2-6行
- 2p;6p:打印2行和6行
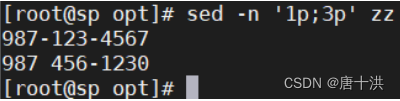
- p;n:打印奇数行
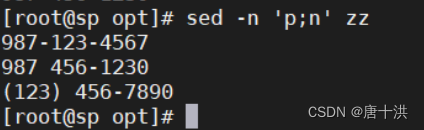
- n;p:打印偶数行
- /hello world/p:打印匹配内容的行
- /^hello/:打印以hello开头的行
- /hello$/:打印以hello结尾的行
- $p:打印最后一行
- r:扩展正则表达式
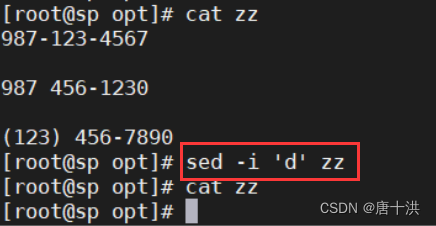
- d:删除指定行
- 免交互删除文件中的内容,但保留文件
当然用黑洞文件也可以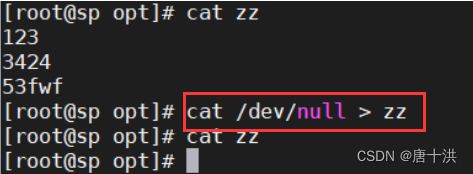
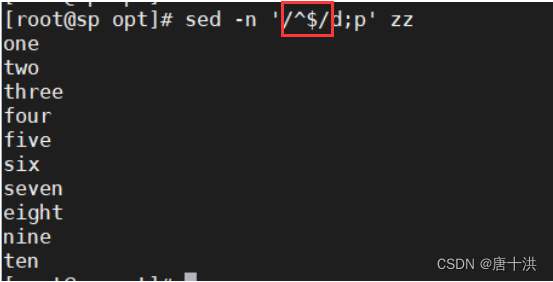
- 删除空行
- 免交互删除文件中的内容,但保留文件
- =:显示行号
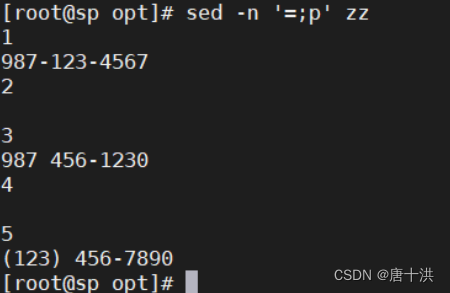
- ;可以使用多个操作命令,比如说=;p,2d;p
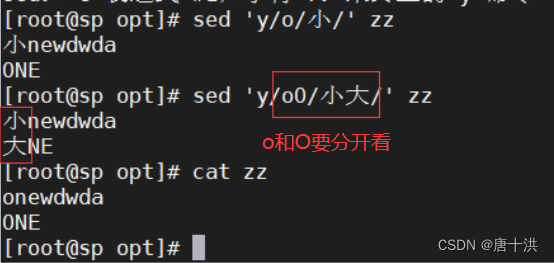
- s:替换字符串
- 不写换第几个默认替换第一个

- 写了换第几个就是替换第几个,如果这一行的原字符不够这么多,那就不替换

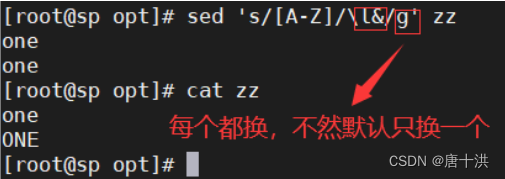
- 写g就是全部替换

- l&:大写换小写(这里的 l 是 L 的小写,不是 i 的大写),注意我这里没有加 -i ,所以文件里的内容并没有真正意义上替换,原先是大写,cat显示出来的还是大写
- u&:小写换大写
- 如何对字符串的位置进行调换

- 不写换第几个默认替换第一个
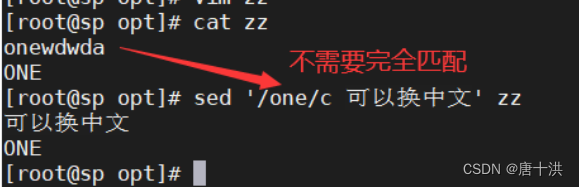
- c:整行替换
- 只要某一行包含目标内容,那么整行都会被替换掉,如下
- 单字符替换,替换前后的字符串长度必须相同,注意并不是整体替换,当有多个字符进行替换时,它们是独立的多个字符,而不是一整个字符串
- 只要某一行包含目标内容,那么整行都会被替换掉,如下
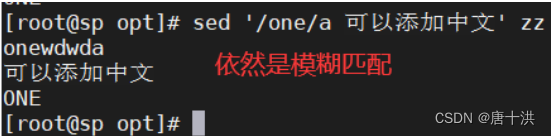
- a:匹配内容的下一行添加
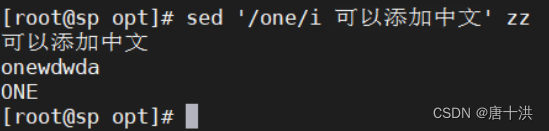
- i:匹配内容的上一行添加
- r:行后追加,读取其他文件的内容,然后在行后追加
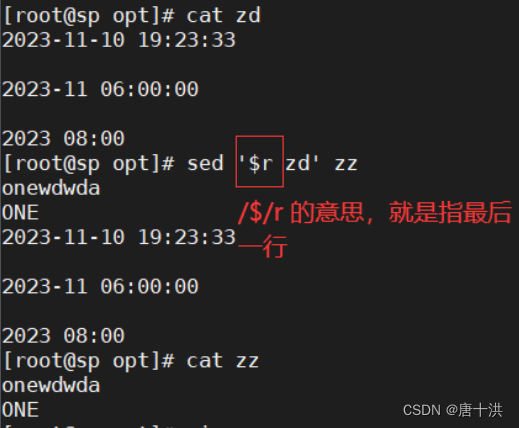
这样写也行,可以指定在具体内容所在行之后添加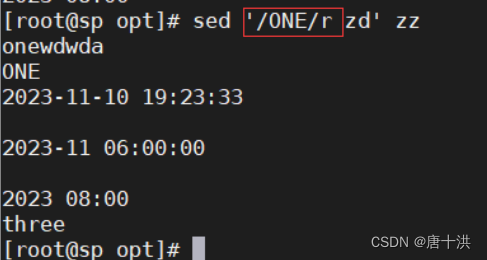
- p:打印,3p表示打印第3行
awk
- 作用:按行取列,这方面和cut类似,cut的默认分隔符是TAB键。awk的默认分隔符是SPACE键或者TAB键,但是多个空格或多个tab会自动压缩成1个,awk可以在免交互的情况下实现复杂的文本操作
- awk一个强大的文本编辑工具,逐行读取文件内容,然后输出结果,它主要由三部分组成
awk 选项 '模式或条件 {操作符 具体动作}' 处理对象 - awk的选项,下面这两个记住就够了
- -F:指定分隔符 默认是空格,可以不加
- -v:变量赋值
- awk的内置变量
- 正常示例
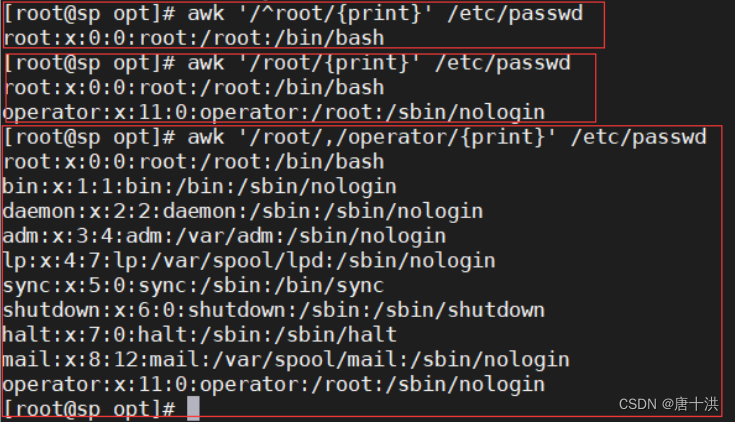
- $0:打印所有
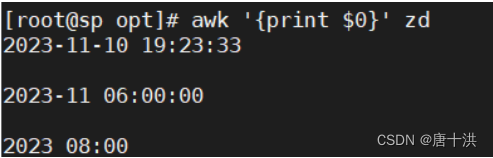
- $0:打印所有
- 按行取列的格式
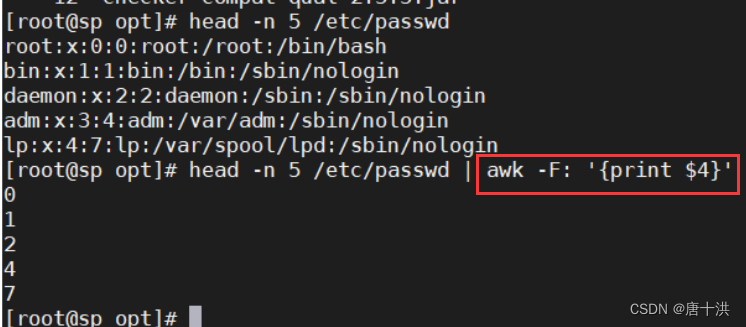
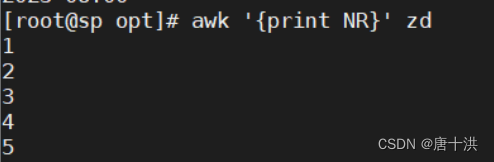
- NR:指定行
- 只有NR就只显示行号
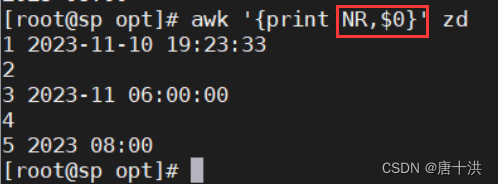
- NR加$0就会显示行号并且显示内容
- NR==指定具体哪行
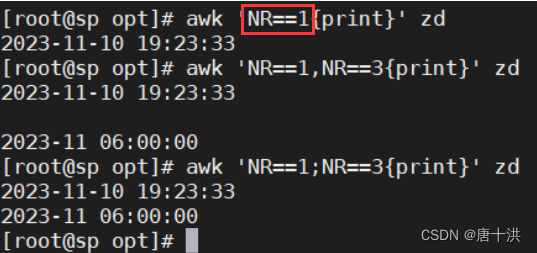
- >和<也可以用
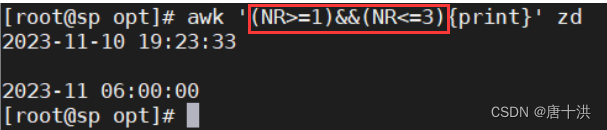
- 偶数行,奇数行
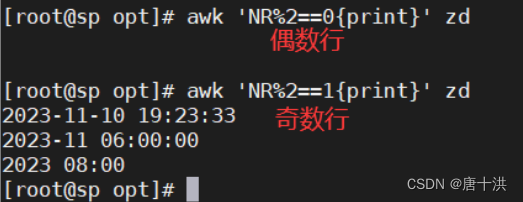
- 只有NR就只显示行号
- NF:处理行的字段个数,$NF代表最后一个字段
- awk作为运算器的格式
awk 'BEGIN{print 3^2}'
- awk的精确筛选
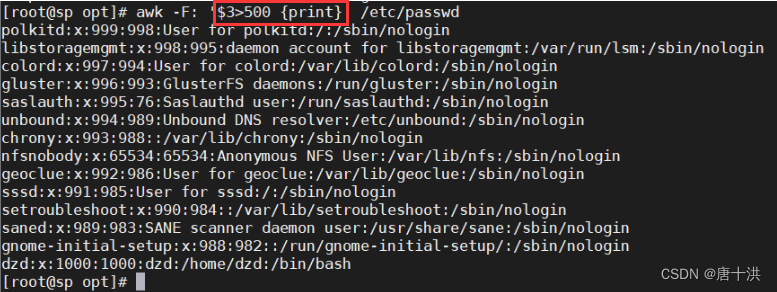
- $n(</>/=):用于对比数值
- $n~"字符串" 代表第n个字段包含某个字符串
- $n!~"字符串" 代表第n个字段不包含某个字符串
- $n=="字符串" 代表第n个字段为某个字符串
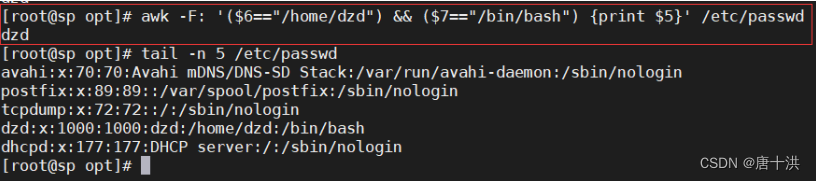
- $n!="字符串" 代表第n个字段不为某个字符串
- $NF:最后一个字段
- $n(</>/=):用于对比数值
- awk的三元表达式
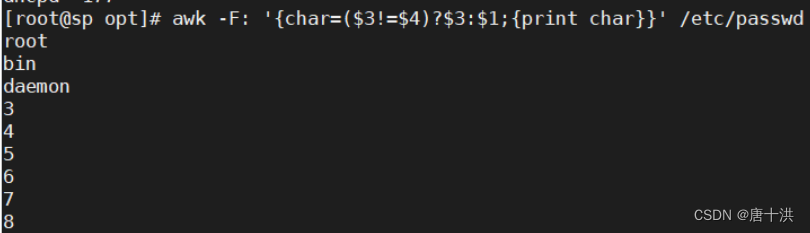
- awk与数组

- 正常示例
配合使用的其他功能
sort
- 作用:按照行对文件内容进行排序,也可以根据不同的数据类型进行排序
- 用法:
- sort 选项 参数
- cat 文件 | sort 选项
- 选项:
- -f:把大写字母放前面,默认会把小写字母排前面
- -b:忽略每行前面的空格
- -n:按照数字进行排序
- -r:反向排序
- -u:相同的数据只显示1行,也就是去重
- -o:将排序后的文件内容转存到指定文件
- 因为sort会默认排序,所以如果想用sort进行操作但又不想改变原文件内容的顺序,可以用 cat -n 文件 | sort -n 选项,cat -n表示显示行号,这样sort排序的时候就会按照第一个数字也就是行号排了,也就是不会改变顺序
uniq
- 作用:按行进行处理,去重复行(只有连续出现的相同的行才是重复行)
- 格式:
- uniq 选项 参数
- cat 文件 | uniq 选项
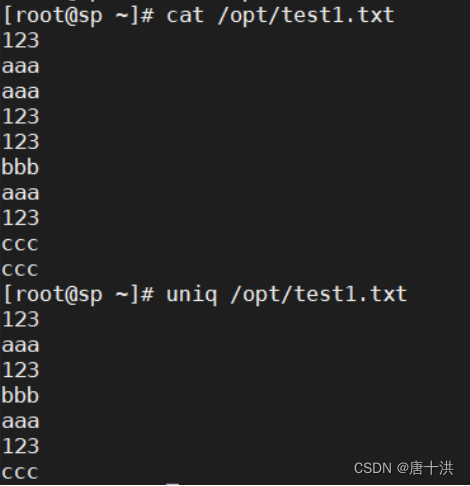
- 选项:
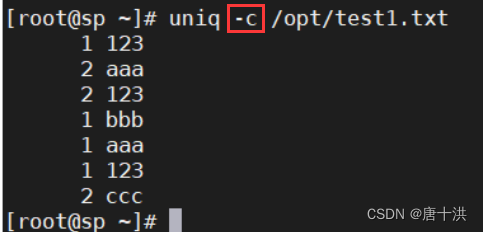
- -c:统计连续重复出现的行的次数,并且合并重复行,并展示
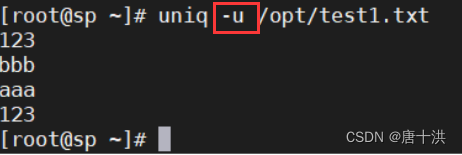
- -u:仅显示出现一次的行
- -d:仅显示重复出现的行

- -c:统计连续重复出现的行的次数,并且合并重复行,并展示
tr
- 作用:字符替换、压缩、删除
- 格式:
- tr 选项 参数
- cat 文件 | tr 选项
- 选项:
- -c:保留字符集1的字符,然后其他字符用字符集2进行替换

回车可能也被替换成a了,验证一下
- -d:删除字符集

- -s:把重复出现的字符串压缩为一个字符串
- -t:默认,可以不加,作用是把字符集2替换成字符集1

- -c:保留字符集1的字符,然后其他字符用字符集2进行替换
cut 快速裁剪
- 作用:对字段进行截取和裁剪
- 格式:
- cut 选项 参数
- cat 文件 | cut 选项
- 选项:
- -d:指定裁剪的分隔符(默认的分隔符是tab的空格)
- -f:按行取列,根据第几个字段进行截取
- -b:以字节为单位进行截取(不常用)
- -c:以字符为单位进行截取(不常用)
- --complement:排除所指定的字段,相当于取反

- --output-delimiter:更改输出结果的默认分隔符

- 举例:以冒号(:)为分隔符截取/etc/passwd文件中的第1到3个字段(1-3列)
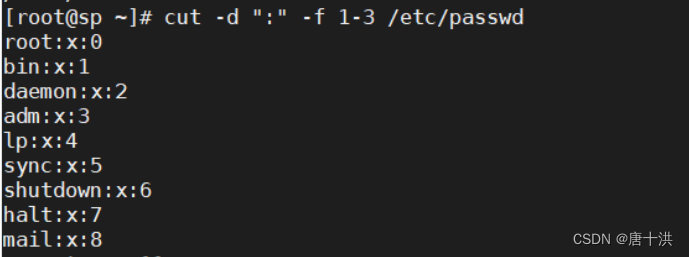
split
-
作用:把大文件拆分成若干小文件
-
-l:指定行数进行拆分(这是L的小写)
-
-b:指定大小进行拆分
正则表达式
- 正则表达式是由一类特殊字符以及文本字符所编写的模式,其中有些字符不表示字符字面的含义。而表示控制或者通配的功能,用来处理文本内容当中的字符
- Linux中的通配符:通配符用来匹配文件名或者目录名
- 常见的通配符
- []:范围匹配,注意字母的范围是:a A b B…..z Z
- ?:匹配任意一个字符
- *:匹配任意一个或多个字符
- 常见的通配符
- 正则表达式:
- 元字符:
- .:匹配任意单个字符,也可以是一个汉字
- \:转义符,比如”.“指任意单个字符,但是”.“就是指一个”.“
- ():分组
- []:匹配指定范围内的单个字符,注意这里的字母范围就是正常的范围,比如[a-d]就是a,b,c,d
- [[:blank:]]:匹配空格和制表符
- [^字符]:表示取反,除了这个 ^在[]外表示以…为开头
- 表示次数:*:匹配前面的字符任意次,0次也可以
- 重点解释一下,比如说

我们可以看到,*之前的字符就是匹配的目标 go*gle 表示g 和 gle之间可以有任意个o,再看第二条命令,g*gle表示gle之前可以有任意个g,但是google的gle之前是o,这就不能找到google,反而是找到了gle
- 重点解释一下,比如说
- .*:匹配前面的字符任意次,至少1次
这就是.*和*的区别:
- \?:匹配前面的字符1次或0次
- +:匹配前面出现的字符最少1次,最多无限次
- {n}:表示前面的字符只能出现n次,包括前面的字符
- {m,n}:表示前面的字符最少出现m次,最多出现n次
- {,n}:表示前面的字符最多出现n次,0次也算
- {m,}:表示前面的字符最少出现m次
- 测试题:提取出ifconfig ens33中的IP地址,子网掩码,广播地址
答:ifconfig ens33 | grep "[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}"
- 位置锚定
- ^:行首锚定,以什么为开头
- $:行尾锚定,以什么为结尾
- ^$:匹配空行
- ^root$:精准匹配某一行的内容
- \<或者\b:词首锚定,用于单词模式匹配单词的左侧(连续的字母,数字,_,都算单词内部)
- >或者\b:词尾锚定,用于单词模式匹配单词的右侧
- \broot\b:匹配一个精准单词,而不是匹配行
- 分组和逻辑或
- 分组:\(\)

- 逻辑或:\|
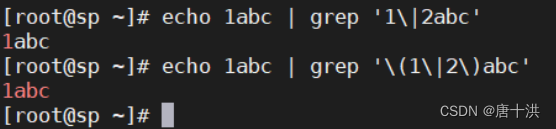
- 分组:\(\)
- 扩展正则表达式
- 就是把 \ 全部取消,比如:\(\) 变成了 (),\| 变成了 |
- 怎么使用:
- grep -E
- sed -r
- egrep
- 元字符:

















 1396
1396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









