



正则化可以理解为规则化,规则就等同于一种限制。在损失函数中加入正则化项可以限制他们的拟合能力,正则化就是为了防止过拟合,那么什么是过拟合?
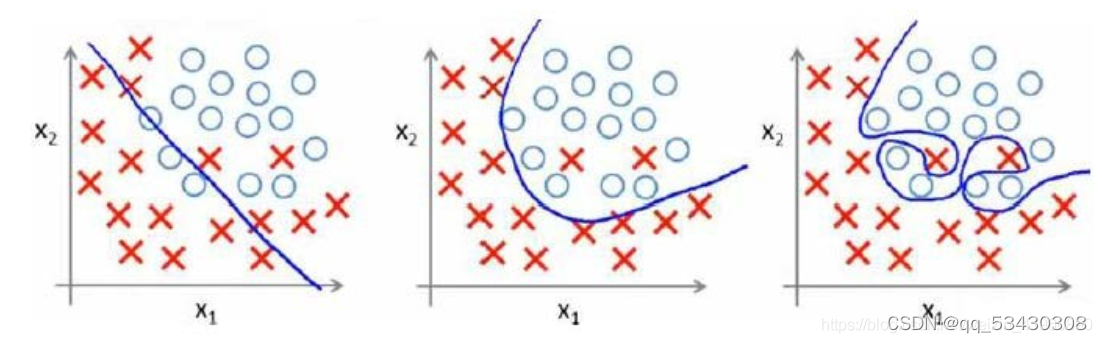
图1
假如我们要构建的模型是能够区分图中的红色与蓝色部分,看图1的三种模型对训练集的拟合状态:
第1种模型:欠拟合(underfitting),此模型不能很好的区分图中的红色与蓝色部分。
第2种模型:拟合状态刚好,虽然有个别红色部分未被区分但考虑到实际测试集中会有噪声的存在,其拟合程度就刚刚好。
第3种模型:过拟合(overfitting),此种模型对于训练集的拟合程度非常高,导致其泛化能力("泛化"指的是一个假设模型能够应用到新样本的能力)较低。而且实际测试集中会有噪声的存在,在后续的测试集中得到的准确率也不高,这也会令模型的复杂度提高,让计算复杂,并不能起到理想的作用。
我们就可以使用正则化来解决过拟合,他的大致工作原理如下:
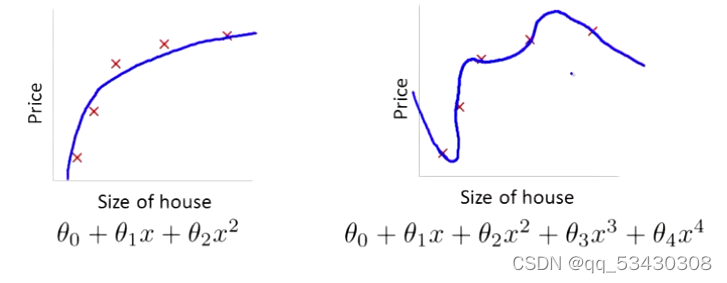
我们的目的是拟合图中的数据,对于第一幅图我们使用一个2次函数来拟合数据,这样看起来效果还不错,当我们使用一个高次函数来拟合数据时,像第二幅图,这样对于这个数据拟合的效果更加好,但这并不是我们想要的模型,因为它过度拟合了数据,我们可以想到这是由于高次项的出现,所以我们要对高次项的系数予以惩罚。
我们在损失函数的后面加上 1000 乘以 θ3 的平方,再加上 1000 乘以 θ4 的平方,这里的1000只是一个随机值。即
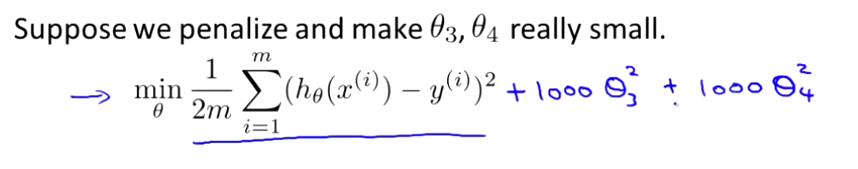
现在我们如果要求损失函数的最小值,就得让3和
4的值非常小,因为损失函数中加入了有关他们的两项,如果
3和
4的值非常大的话,损失函数的值也会变得非常大,所以
3和
4的值趋近于0.
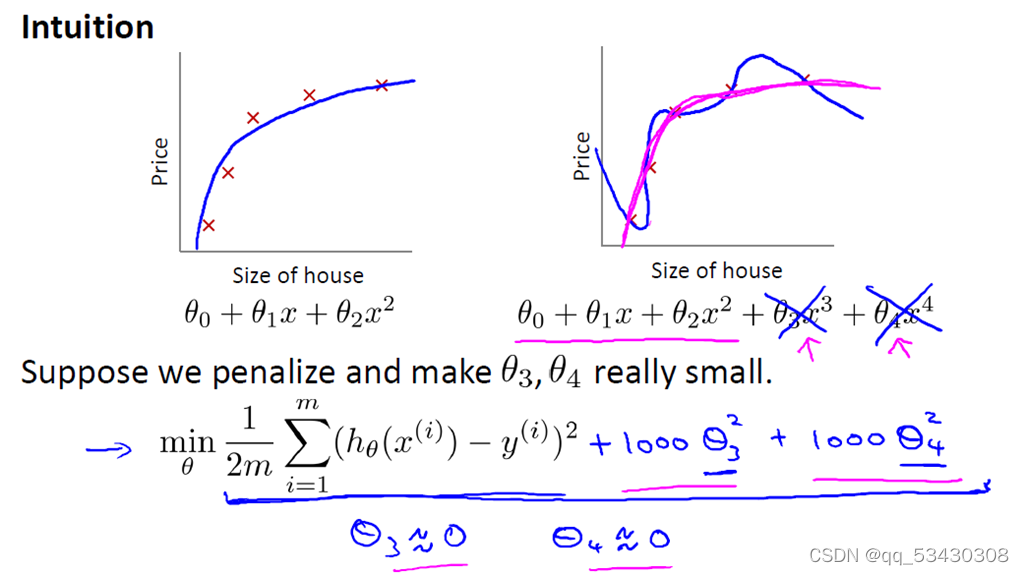
也即拟合函数中的 3和
4两项的值近似为0,所以拟合函数就趋近与2次函数,这样以来,拟合函数的拟合程度就刚刚好了。
这里我们只是有目的的对 3和
4两项进行了惩罚,那如果不知道拟合函数中哪些系数是高次项系数哪?
我们就要对所有项的系数都进行惩罚了,也即我们在损失函数中加入一项(正则化项):
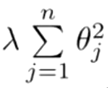
这里并没有惩罚 0,这只会造成很小的差异。 对所有项的系数都进行惩罚相比之下还是对于高次项的惩罚程度更大。
其中叫做正则化参数,
越大则惩罚力度也越大,但
并不是越大越好当
太大时就会造成拟合函数中的参数太小以至于拟合函数就等于
0变成一条直线,造成欠拟合。
此外正则化还分为L1正则和L2正则,又叫L1范数和L2范数,其定义如下:
其他有关的细节不再赘述。
 https://www.cnblogs.com/jianxinzhou/p/4083921.html
https://www.cnblogs.com/jianxinzhou/p/4083921.html
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









