







概述
如果之前没有接触过时序差分算法,那第一次看到会非常奇怪。实际上,时序差分算法就是随机近似理论 的一个特殊情况。
因此本节介绍随机近似理论与梯度下降以更好的帮助理解后面的时序差分算法。
这节课的作用:


本节课大纲如下:

Motivating examples
先回顾一下 mean estimation ,就是多次采样求平均值以近似期望嘛,这是蒙特卡洛算法的核心思想:

那为什么总数反复提到这个 mean estimation,就是因为 RL 当中有非常多的 expectation,后面就会知道除了 state value 这些定义之外,还有很多类似的我们都得使用数据去进行估计。
那么如何计算平均值呢?除了上图中也就是我们之前所介绍的相加除以 n 的方法,这种方法有缺陷,它的问题是如果我有很多这样的数据因为这些是采样得到的,那我就要等很久,等完了之后把所有的数据全收集到一起再求平均。
实际上我们还有另外一种方法,它克服了需要等的问题:

这第二种方式被称为增量式的或者说是迭代式的方法,基本的思路就是来几个我就先计算几个,这样的效率会更高。
那第二种方法到底是如何做的?推导过程如下:

首先针对 k 个,就是 x1 一直到 xk,针对这几个我求一个平均,在上图中使用 w(k+1) 来代替这个平均,它就是 1/k 它们的和。
这个 w(k+1) 也可以写成 wk,之所以写成 w(k+1) 之后我们看到它就会明白形式上相对来说会更简洁一点。
那么 wk 我们就知道是啥啦:
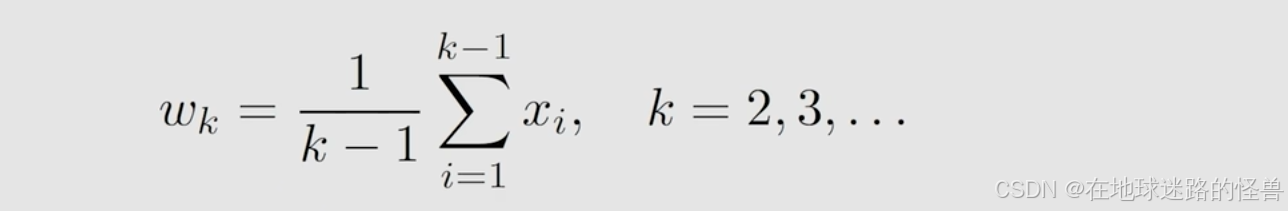
而接下来要做的事情就是建立起来 w(k+1) 和 wk 它们之间有什么样的关系。
实际上 w(k+1) 能够通过 wk 来表示出来:
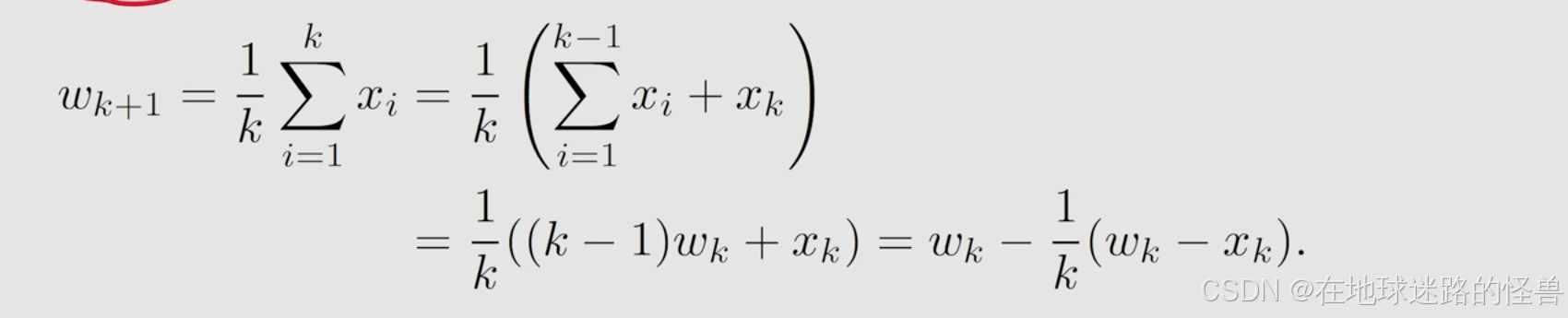
可以看到前 k 个 xi 要求和,那我们把这个和分成两部分,第一个是前 k-1 个 xi ,第二个是第 k 个 xi,也就是 xk。
而 前 k-1 个 xi求和 这个是与 wk 的表达式是有关系的,因此最后是能够化出上图中的式子,也就建立起了 w(k+1) 和 wk 之间的数学关系:
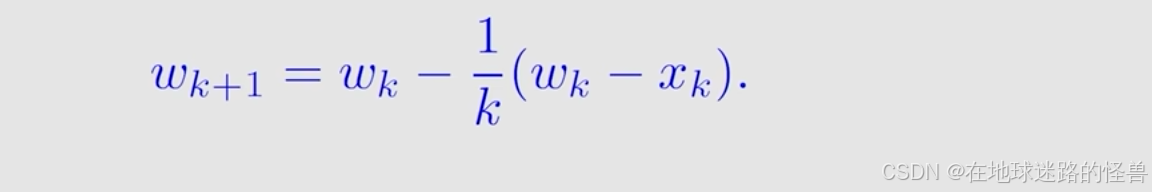
而推导完的最后的式子就是一个迭代式的算法,比如说在上个时刻我已经计算出 wk 了,那么这个时刻我就得到一个新的采样 xk,那我就直接通过这个式子我就可以得到新的 wk+1 。
这样就不需要像之前一样把前面所有的 xi 全部加起来然后再求平均,也就克服了之前那种计算方式的缺陷。
但是这样的做法究竟可不可行?我们可以推导一下:

很明显最后的结果是符合 mean estimation 的定义的,因此是可行的。
关于这个算法的一些需要清楚的点:

另外这个算法还可以进行进一步的推广:

刚才我们说的系数实际上是 1/k,现在我们可以把这个系数替换成一个 αk,αk 就是一个正数。
如果是 1/k 其实在之前我们说过我们有一系列的式子我们可以知道 w1、w2、w3 这样一直迭代下去,它真的就能显式地写出来,它们确实就是平均数,但是如果 αk 不是 1/k,那这时候它就写不成那种形式了,那这时候 wk 还能否逐渐逼近 E[x] 呢?
实际上,当这个 αk 满足一些条件的时候,它虽然不是 1/k 的形式,但它依然可以让 wk 逐渐逼近期望 E[X],后面会再详述。
综上所述可以看出,这个算法实际上就是一种特殊的随机近似算法,其也是一种特殊的随机梯度下降的算法。
Robbins-Monro algorithm
Robbins-Monro algorithm,这是随机近似理论当中一个非常经典的算法。
前面我们反复提到随机近似 stochastic approximation ,那么这个究竟是什么呢?
首先这个简称 SA,它是代表了一大类的算法并非指某一特定的算法,什么类型的算法呢?
就是 stochastic iterative algorithm ,随机迭代算法。
所谓随机的算法就是这里边会涉及到对随机变量的采样,而 SA 特指的这些算法是要进行方程的求解或者优化问题。
当然有很多算法可以进行方程的求解还有求解优化问题,比如说 gradient descent 这种梯度下降或者梯度上升的这种方法。
但 SA 这种算法的优势在于它不需要知道这个方程或者目标函数的表达式,那自然也就不知道它的导数或者梯度的这种表达式。
在不知道这些内容的情况下 SA 一样可以进行求解,但是到底怎么解呢?后面会详述,接下来介绍 随机近似 这个领域最经典最具有开创性工作的一个算法,也就是下图中的 Robbins-Monro 算法,另外我们常用的 stochastic gradient descent 随机梯度下降方法就是 RM 算法的一种特殊情况。
上文 Motivating example 一节中所提到的例子实际上也是一种特殊的 RM 算法,后面我们就会明白的。

那么接下来我们就来看看问题究竟是什么问题,算法究竟是怎么个算法:

这里的问题就是我们要求解这样一个方程:g(w) = 0。
w 就我们的未知量,g 则是一个函数,简单起见我们就都考虑是标量的情况,w 和 g 全都是标量。
虽然这个问题看似很简单,但是它非常有用,因为它广泛的存在,一个比较典型的例子就是做优化。比如要去优化一个目标函数 J(w),怎么去优化?一般而言都是求解像下面这样的方程:
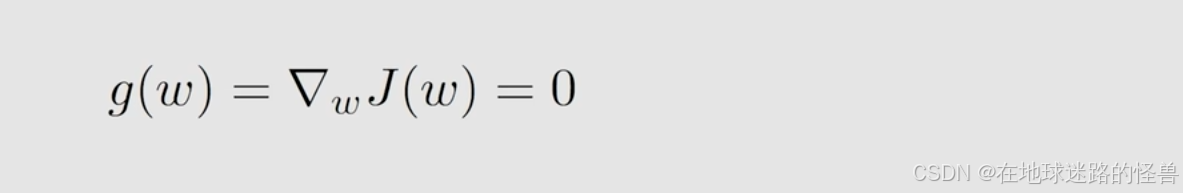
就是 J(w) 的梯度等于 0 ,梯度等于 0 是 J(w) 达到最大或者最小的一个必要条件。它并不是充分条件,但是在很多情况下,我们能够找到局部的极值或者说 J(w) 当它只有一个极值的时候,那么这个就变成了一个充分必要条件。
总而言之,这种优化问题也可以写成 g(w) = 0 的这种形式,这个时候 g(w) 指的就是梯度。
另外我们也可能会面临比如 g(w) = c 这样的函数,右边是一个常数,那么这时候我们就可以把 c 移过来左边就变成了一个新的 g(w) 。
让这个新的 g(w) = 0 仍然可以化成我们想要的形式。
那我们怎么样来求解这样一个 g(w) = 0 呢?接下来来研究这个问题:

有两种情况,第一种情况是 g(w) 的表达式是知道的,那这个时候求解方法就很多了。如果 g 是一种特殊的函数,可能甚至对那种特殊的函数都有相应的算法。而我们这里要考虑的情况是这个 g 函数的表达式我根本就不知道要如何求解。
如果 g(w) 的表达式都不知道是什么,那到底该怎么进行求解?
这很像我们学深度学习时候的神经网络的概念,只给输入然后就能得到输出,却不知道中间过程,而这可以通过 Robbins-Monro 算法来解决,接下来我们正式的介绍 RM 算法。
Algorithm description

RM算法首先是一个迭代式的算法,首先要明确我们的目标是求解 g(w)=0,然后这里面假设最优解是 w*,这个迭代式的算法是 我对 w* 第 k 次的估计是 wk,然后第 k+1 次估计是 w(k+1),w(k+1) 等于 wk 减去后面那个式子。
后面这个式子又进一步分为两个部分,第一个是 ak,ak 是一个系数,第二个是 g~(wk, ηk),其是一个函数,该函数表达式也很简单,就是 g(wk) 加上一个 ηk,ηk 是一个噪音。所以 g~ 是 g 的一个观测,但是是带有噪音的这样一个观测。
在这个算法当中我们实际上是将函数 g(w) 给作为了一个黑盒,我们不知道其表达式是什么,因此该算法依赖的是数据。
相当于有一个黑盒 g(w),我们输入 w,然后其会有一个 y 输出,但是这个 y 不能直接测量还需要加上一个噪音,噪音我们也不知道但是我们此时就能得到一个测量值 g~,输入一个 w 就能得到一个 g~:

因此这样反复输入输出之后,我们会得到一个 wk 的序列和一个 g~k 的序列,RM 算法就是通过这样一种方式来进行求解的。
Convergence analysis
分析其为什么可以找到解。为了分析 RM 算法它的收敛性,我们给出两部分解释。第一部分是再给一个例子,通过该例子来分析它为什么是收敛的,有一个直观上的理解。第二部分则是给一个严格的数学结论。

首先第一部分,来看一个例子:


下面是数学上的严格证明:

这个定理主要就说了这么一件事:对于 RM 算法,如果上述三条条件都满足了,那么 wk 就会收敛到 w*,w* 就是 g(w) = 0 的这样一个解。
然后从上图还可以看到,这里收敛被称为 “wk converges with probability 1(w.p.1)” ,这种收敛在我们平常学习强化学习或者是看强化学习的论文的时候,凡是涉及到证明的或多或少都会有这种 with probability 1 . 为什么呢?因为这里的 wk 它不是一个普通的数,它是一个涉及到随机变量的采样的这样一个数,所以它的收敛不是常规意义上的收敛,而是概率意义上的收敛。
主要需要满足上面三个条件:
1、对于 g(w) 它的梯度有要求
2、对于系数 αk 有要求
3、对于 η 这个测量误差有要求
下面是分析这三个条件的过程:





Application to mean estimation
回忆之前我们最开始所提出的 mean estimation 的算法,当时这个 αk 我们给的是 1/k。
如果这个 αk 是等于 1/k 的话,我们是能够显式地一步一步把它写出来的,就是这个 wk+1 确实是 k 个 xi 的平均值。
但如果不是的话,实际上我们就无法推导出这个结论,但是我们是否能够证明 wk + 1 最后仍然能够收敛到 E[x] 呢?
这就是我们之前所遗留的问题,但是经过上一小节的收敛分析,我们可以证明这样一个算法实际上它就是一个特殊的 RM 算法,那自然它的收敛性就能够得到了。

下面来看一下,为什么其是一个 RM 算法:

考虑对于这样一个式子:
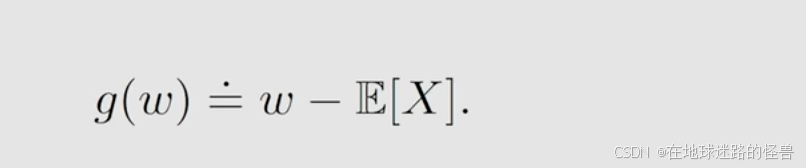
E[x] 是一个随机变量的 expectation 是一个常数,所以上式是一个很简单的 w 减去一个常数这样一个函数。如果我们能够求解 g(w) = 0,那么我自然就能够得到 w* = E[X] ,那么 x 的 expectation 就求出来了。
而 expectation 显然我们是不知道的,我们知道的是我们可以对 X 进行采样,所以我们可以得到测量值
g~ ,即 g~=w - x :
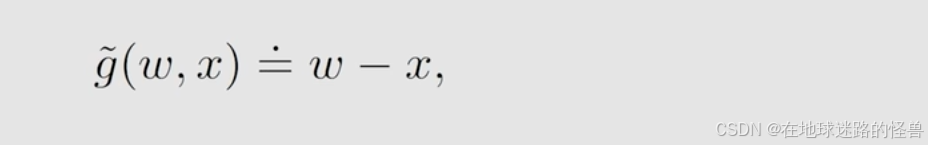
x 是对 X 的一个采样,g~ 还可以进一步写成如下形式:
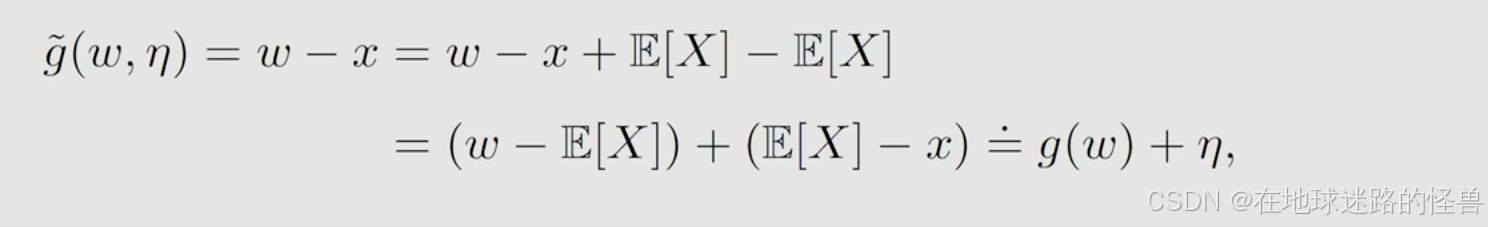
也就是 g~ 可以进一步写成 g(w) 再加上一个误差 error 就是 η 。
因此相对应的 RM 算法如下:
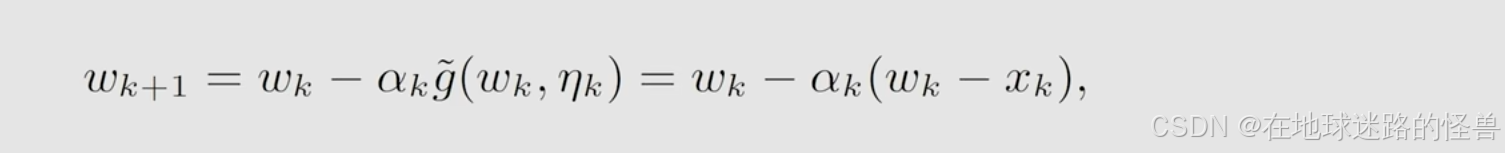
所以现在我们就知道 mean estimation 的算法实际上就是一个特殊的 RM 算法。
Stochastic gradient descent
随机梯度下降实际上也是 RM 算法的一个特殊情况,而 mean estimation 的算法也是 随机梯度下降 的一个特殊情况。因此这三部分实际上关系非常密切。
那么 SGD 算法究竟是什么:

其要解决的其实就是一个优化问题,假设要优化的函数是 J(w) :
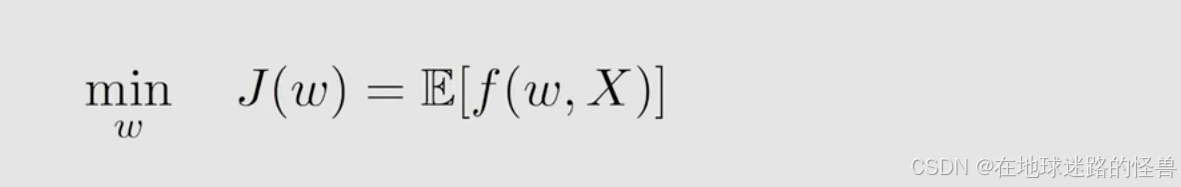
目标函数 J 是关于 w 的这样一个函数,w 可以是一个参数或者是一个变量,总而言之我要优化这个 w 让这个目标函数达到最小。这个目标函数是含有 expectation 和随机变量的这样一个目标函数,具体来说就是这个函数 f 它的 expectation ,而 f 呢又是 w 和 X 的函数,这里边 w 我们知道了,就是目标函数 J 中的 w,而 X 则是一个随机变量,这个随机变量的概率分布已经给定了(当然我们是不知道的),而这个 expectation 实际上就是对这个 X 进行求的。
总而言之,我们的目标就是要找到最优的 w 使得目标函数的值能够达到最小。
对于求解这样一个问题实际上有很多方法,下面是三种方法,三者层层递进:

首先是上图中的梯度下降算法,因为我们的目标是要去最小化一个目标函数,所以我们要用梯度下降,如果你的目标是要最大化一个目标函数你就要用梯度上升。那么梯度下降算法是什么呢?
就是我假设我的最优的解 w* ,然后我在第 k 次我对 w* 有一个估计,然而这个 wk 可能是不准的但是我会在 w(k+1) 的时候去改进这样一个 wk,怎么改进呢?先要明白上图表达式中的下图这个部分是什么:
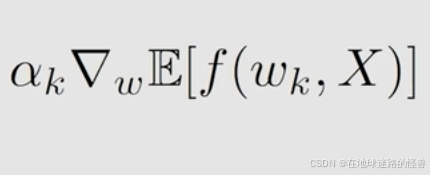
上图中,E[f(wk, X)] 就是我们的目标函数 J(w) ,我对这个 J(w) 求前面这个倒三角符号,其代表梯度,就是我沿着梯度的方向去进行下降,那我自然就可以更好地去最小化这一个 目标函数。上图中的 αk 就被称为步长,它是用来控制我在这个梯度方向下降得是快还是慢。这就是梯度下降算法。
虽然这个算法很简单但是问题也很明显,就是说我要对它的梯度求一个 expectation 我不知道该怎么办,第一种方法是知道模型那可以通过模型求出来,第二种方法则是没有模型,那用数据怎么来求?
因此我们来看第二种方法,用数据怎么进行梯度下降的求解,也就是 批量梯度下降:

思路很简单,我们刚才不是要求 expectation 吗?没有模型可以使用数据,也就是说我对里边的这样一个随机变量进行采样,我采很多很多次,然后最后进行求平均,我们就用这个平均值来认为是 expectation 。(这个不就是我们之前学习蒙特卡洛算法的一个基本思想吗?)然后我们就把这些数据所得到的平均值放到里边,这就是 BGD 这样一个算法的思路。
思想很简单,但还是有问题,就是在每一次去更新这个 wk 的时候其都要采样 n 次或者是很多次,这个在实际当中可能还是不行的。
那么就来到了第三种方法,随机梯度下降:

从上图不难看出,SGD 的算法非常简洁。注意一下表达式中与之前的细微差别,就是之前算法中梯度里边的 f(wk, X) 被换成了 f(wk, xk) ,就是有随机变量 X 变成了一个 X 的采样 xk,我们将三个算法放在上图中这样一起比较,可能会更好理解:
首先,相比于 GD,在 GD 当中它用的是真实的梯度,但是因为不知道所以我们就使用了一个随机梯度来进行代替。之所以被称为随机梯度下降的原因就是因为这里面是有一个随机量的采样 xk 在里边的。
另一方面和 BGD 进行比较的话,实际上就是把 batch gradient descent 中的这个 n 给设置成了 1 就得到了 SGD 。
本来使用很多数据来进行估计,现在使用 SGD 也就是使用一个数据来估计的话那么问题肯定就是结果是不太精确的,那么究竟 SGD 不精确到什么程度或者说它会不会带来很大的问题以及最后这个 SGD 能不能解决这个最优化问题,之后会详细分析。
Examples and application
介绍几个例子演示如何使用 SGD 的算法:

下面是对上面三个问题的回答:
首先是对于 Excise1 的证明:
要让 J 达到最小值,实际上它有一个必要条件,就是对 J(w) 求梯度它应该等于 0,因此有如下推导:

w 因为本身不是一个随机变量,因此它的 expectation 就是它自己,所以有上图最后一行的转化成立。
下图是第二个和第三个 Excise 的答案:

GD 的解决方法比较简单,图中也比较清楚。而 SGD 的算法其实很简单,直接去掉 GD 中的 expectation 然后使用 wk - xk 来代替这样一个 expectation 即可。
最后这个式子的形式相信应该很眼熟,w(k+1) = wk - αk(wk-xk) 这个算法实际上就是我们在最开始介绍的 mean estimation 的问题,也就是我有一个 X 我要求它的 E[X] 我怎么求呢?
解决方法是我有一组的这样一个数也就是采样得到的 xi,然后我把这个 xi 一个一个放到这个算法里边,我就可以最后能够得到它的平均值,进而近似得到 expectation,这是一开始我们所介绍的。那个时候我们最开始 αk 是等于 1/k 我们就能知道这个 wk 确实是非常精确的前 k 个 xi 的平均值,后来我们又提到了这个 αk 不是1/k 的时候怎么办呢?
其实现在我们知道了,这时候也是可以解决的,因为这个算法实际上是一个特殊的 SGD 算法。
它的问题的描述是不一样的,之前是描述求 E[X] ,而现在呢它描述成一个优化问题,它们是殊途同归的。
Convergence analysis
下面来分析一下 SGD 为什么是有效的,也就是为什么是收敛的:

RM 算法我们之前已经了解了,其实它的想法也是比较简单,我们通过证明 SGD 是一个 RM 算法然后 RM 算法在满足一定条件下是能够收敛的,我们就能知道 SGD 在满足什么样的条件下它也是能够收敛的,这样的思路是非常简洁的(直接证明 SGD 的收敛性太复杂):



Convergence pattern
继续分析,分析它在收敛过程当中的一些非常有意思的行为:





A deterministic formulation



BGD, MBGD, and SGD


下面使用一些例子来例证刚刚的这三种算法:



Summary

从上图以及之前的学习内容可以总结如下:
我们首先是介绍了 mean estimation 这样一个问题,什么问题?就是我要用一组数来求它的 expectation。在之前其实我们就简单地把这一组数求平均,然后就可以来近似估计它的 expectation,但现在我们就知道了我们其实可以用迭代的方式(就是上图第一条表达式)进行计算,也就是当得到一个采样就计算一次,这样就不需要等到所有的采样全部拿到了我们再计算,会更加地高效。
然后介绍了非常经典的 SA 领域当中的 RM 的算法,这个算法解决了什么问题呢?就是我有一个方程 g(w) = 0,我要求解它的最优解 w*,但是我不知道 g(w) 的表达式,我知道的是什么呢?我知道给我一个 w,我能测出来它的输出,而且这个输出是有噪音或者是有误差的,这个输出用 g~ 来表示,所以这个 RM 算法就是我怎么样用这样的含有噪音的测量来估计这个 w*。
最后介绍了 SGD 这样的算法,求解了什么问题呢?就是我有一个目标函数,长 J(w) = E[f(wk, xk)] 这个样子,然后我可以知道它的梯度的一个采样,然后我们就可以用这个 stochastic 的 gradient,然后用这个算法(上图第三条表达式)让最后这个 wk 趋于最优值 w*。


















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











