







 本文介绍了如何使用链表数据结构解决两个链表的第一个公共节点问题,提供了使用哈希表、栈和双指针的不同解法,并探讨了它们的时间和空间复杂度。此外,还讨论了判断回文链表的算法,提到了栈和数组的应用。
本文介绍了如何使用链表数据结构解决两个链表的第一个公共节点问题,提供了使用哈希表、栈和双指针的不同解法,并探讨了它们的时间和空间复杂度。此外,还讨论了判断回文链表的算法,提到了栈和数组的应用。
上篇我们了解了一些关于链表这个数据结构的概念和基础操作,如单向和双向链表的遍历、插入和删除,本章我们来一起把它们运用到算法实战中,感受下链表的独特魅力!
本节后续:
话不多说,直接开干!

两个链表的第一个公共节点
题目链接:
剑指 Offer 52. 两个链表的第一个公共节点 - 力扣(Leetcode)
面试题 02.07. 链表相交 - 力扣(Leetcode)
题目信息:(这里我只给出了部分题目,具体的示例和注意可以参考上面的链接!)
输入两个链表,找出它们的第一个公共节点。
结果:在节点 c1 开始相交。
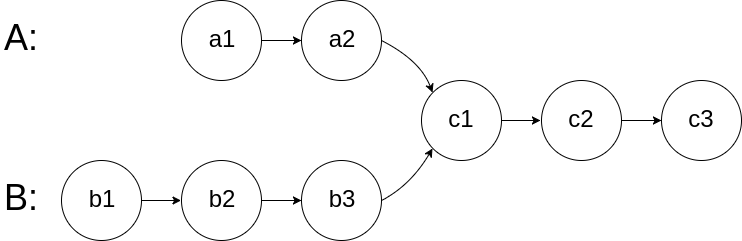
你第一眼看到题目能够理解或知道如何解决该问题吗?
相信大部分佬们应该都知道多种解法吧(doge头保命),那么接下来我就针对像我一样的小白,来讲解一下该如何 KO 这道或这类题目

如果我们看不懂或不知道该如何解决这道题,我们可以参考以下思路进行思考:
仔细阅读题目描述:确保理解题目的要求和限制条件。了解题目要求是找到两个链表的第一个公共节点。
理清问题:考虑两个链表可能的情况,包括两个链表没有公共节点、有一个公共节点、有多个公共节点等情况。思考问题的一般情况和边界情况。
分析和设计解决方案:思考如何解决问题。可以考虑使用辅助数据结构(如栈、哈希、数组和集合等)、指针操作、遍历等方法。尝试将问题拆分为更小的子问题,并设计解决方案。
思考示例:以具体示例或特殊情况进行思考,可以帮助更好地理解问题和解决方案。考虑两个简单的链表,例如链表 A 和链表 B,手动模拟解决过程,思考它们的交叉点在哪里。
编写代码实现解决方案:根据设计的解决方案,编写代码实现算法。在实现过程中,可以使用适当的变量、指针、循环等。
测试和验证:编写测试用例,包括正常情况和边界情况,验证代码的正确性和健壮性。确保代码能够正确地找到两个链表的第一个公共节点。
分析复杂度:评估解决方案的时间复杂度和空间复杂度。思考是否有更优的解决方案。
思考扩展和优化:考虑是否存在其他方法来解决问题,或者是否可以对现有解决方案进行优化。思考其他可能的情况,例如链表很长、链表中有环等。
学习和总结:总结问题的解决方法和思考过程,学习并理解更多相关的数据结构和算法知识。
学习算法最重要的是解题思路,这种方法不行可以换另一种方法,想着想着我们可能就绕不出来了(doge)
针对本题的几种不同解法
一种常用的辅助数据结构是哈希表(HashMap 或 HashSet)。我们可以遍历链表 A,并将链表 A 的每个节点都存储在哈希表中。然后,再遍历链表 B 的节点,对于每个节点,我们可以检查其是否在哈希表中出现过。如果找到第一个出现的节点,就是两个链表的第一个公共节点。
具体代码如下:
class ListNode {
int val;
ListNode next;
public ListNode(int val) {
this.val = val;
this.next = null;
}
}
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
Set<ListNode> set = new HashSet<>();
// 遍历链表 A,将节点存储在哈希表中
while (headA != null) {
set.add(headA);
headA = headA.next;
}
// 遍历链表 B,查找第一个出现在哈希表中的节点
while (headB != null) {
if (set.contains(headB)) {
return headB;
}
headB = headB.next;
}
return null;
}
}
通过使用哈希表,我们可以在时间复杂度为 O(m+n) 的情况下解决问题,其中 m 和 n 分别是链表 A 和链表 B 的长度。需要注意的是,使用哈希表会占用额外的空间。
使用哈希表是一种常见的解决方法,适用于链表长度不太大的情况。如果链表长度很大,或者空间复杂度有限的情况下,可能需要考虑其他的解决方案。
(通过哈希+链表的方式虽然可以成功的解决问题,但在面试中却不是一个优秀的选择【即不是最优解】。因为本方法需要消耗额外的空间,哈希冲突可能导致性能下降,需要遍历整个链表构建哈希表等)<艹,想了那么久想出来的办法,时间复杂度2个O(n)还不行吗?蓄意轰拳doge>
虽然对于本题来说,栈并没有什么特殊的优势,但多了解一种解法,总归是由收获的,具体的思路如下:
- 分别遍历链表 A 和链表 B,并将它们的节点依次入栈。
- 从栈顶开始比较两个栈中的节点,直到找到第一个不相同的节点为止。这个节点之前的节点就是两个链表的第一个公共节点。
代码如下:
import java.util.Stack;
class ListNode {
int val;
ListNode next;
public ListNode(int val) {
this.val = val;
this.next = null;
}
}
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
Stack<ListNode> stackA = new Stack<>();
Stack<ListNode> stackB = new Stack<>();
// 将链表 A 的节点入栈
while (headA != null) {
stackA.push(headA);
headA = headA.next;
}
// 将链表 B 的节点入栈
while (headB != null) {
stackB.push(headB);
headB = headB.next;
}
ListNode commonNode = null;
// 从栈顶开始比较两个栈中的节点
while (!stackA.isEmpty() && !stackB.isEmpty()) {
ListNode nodeA = stackA.pop();
ListNode nodeB = stackB.pop();
if (nodeA == nodeB) {
// 当节点相同时,更新公共节点
commonNode = nodeA;
} else {
// 当节点不相同时,结束比较
break;
}
}
return commonNode;
}
}
通过使用栈,我们同样可以在时间复杂度为 O(m+n) 的情况下解决问题,其中 m 和 n 分别是链表 A 和链表 B 的长度,但使用栈也会占用额外的空间。
使用栈是一种有效的解决方法,适用于链表长度不太大的情况。如果链表长度很大,或者空间复杂度有限的情况下,可能需要考虑其他的解决方案。对于本题而言,使用栈的代价要比哈希大一点,时间栈反而消耗的长,空间也消耗的大,当然能想出来用栈来解题就已经很优秀了~![]()
相信对于本题或本类题型来说面试官想要看到的解法应该是使用双指针法吧,那接下来我们就来用用,看看它到底是个啥。
使用双指针也有不同的具体实现,我们先来了解一种,具体过程如下:
- 定义两个指针 pA 和 pB 分别指向链表 A 和链表 B 的头节点。
- 同时遍历两个链表,每次将指针 pA 和 pB 向后移动一个节点,直到其中一个指针到达链表的末尾(即指针指向 null)。
- 当指针 pA 到达链表 A 的末尾时,将其重新指向链表 B 的头节点,继续遍历。
- 当指针 pB 到达链表 B 的末尾时,将其重新指向链表 A 的头节点,继续遍历。
- 当两个指针 pA 和 pB 相等时,即找到了第一个公共节点。如果没有公共节点,则最终会同时到达链表的末尾,此时两个指针都指向 null,退出循环。
这个方法本质上说是把两个字符串拼接到一起了,接下来来解释一下:
假设链表 A 的长度为 a,链表 B 的长度为 b,它们的公共部分的长度为 c。当我们同时遍历链表 A 和链表 B 时,指针 pA 和指针 pB 在两个链表上的移动速度是相同的,且从头节点到尾节点的距离是不同的。
- 当指针 pA 遍历完链表 A 后,将指针 pA 重新指向链表 B 的头节点。同样地,当指针 pB 遍历完链表 B 后,将指针 pB 重新指向链表 A 的头节点。
- 这样,指针 pA 和指针 pB 都“补偿”了它们在第一个链表上遍历过的距离。
- 在第二次遍历中,指针 pA 和指针 pB 会在公共部分的起始节点相遇,或者同时到达链表的末尾(null)。
如果链表 A 和链表 B 存在公共节点,那么在第二次遍历中,指针 pA 和指针 pB 会在公共节点相遇,此时相遇的节点就是第一个公共节点。
如果链表 A 和链表 B 不存在公共节点,那么在第二次遍历中,指针 pA 和指针 pB 会同时到达链表的末尾,即指针都指向 null。
因此,通过使用双指针的方法,在两个指针相遇时,即可判断是否存在公共节点,并返回第一个公共节点。
具体的代码如下:
class ListNode {
int val;
ListNode next;
public ListNode(int val) {
this.val = val;
this.next = null;
}
}
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode pA = headA;
ListNode pB = headB;
while (pA != pB) {
pA = (pA == null) ? headB : pA.next;
pB = (pB == null) ? headA : pB.next;
}
return pA;
}
}
好了,今天的习就先学到这里了,后序会陆续补充一些高频的链表算法题和解题思路及具体代码!

补充来了!!!!
本题同样还有一种使用双指针的解法,可以理解为差值双指针,具体执行流程如下:
- 遍历两个链表,得到它们的长度。
- 让长链表的指针先移动两链表长度的差值个节点,使得两个链表剩余的长度相等。
- 同时遍历两个链表,找到第一个相同的节点,即为它们的第一个公共节点。
话不多说,代码如下:
class ListNode {
int val;
ListNode next;
public ListNode(int val) {
this.val = val;
this.next = null;
}
}
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
// 遍历两个链表,得到它们的长度
int lenA = getLength(headA);
int lenB = getLength(headB);
// 让长链表的指针先移动两链表长度的差值个节点
if (lenA > lenB) {
headA = movePointer(headA, lenA - lenB);
} else {
headB = movePointer(headB, lenB - lenA);
}
// 同时遍历两个链表,找到第一个相同的节点
while (headA != null && headB != null) {
if (headA == headB) {
return headA;
}
headA = headA.next;
headB = headB.next;
}
return null;
}
// 获取链表的长度
private int getLength(ListNode head) {
int len = 0;
while (head != null) {
len++;
head = head.next;
}
return len;
}
// 移动指针,使得剩余长度相等
private ListNode movePointer(ListNode head, int steps) {
while (steps > 0) {
head = head.next;
steps--;
}
return head;
}
}
【俺能想到的方法就这么多了, 部分还是请教了“我们村里的村民”,如果大家也想进入我们村学习算法有一个良好的学习氛围,可以联系俺。
判断一个链表是否为回文链表
题目链接:
题目信息:
请判断一个链表是否为回文链表。
示例 1:
- 输入: 1->2
- 输出: false
示例 2:
- 输入: 1->2->2->1
- 输出: true
说实话,看到这道题我最先想到的是使用数组或者是栈来解决,不知道各位大gei们有什么更简单的方法,我就按我的思路来讲一下这道题吧!
先说使用栈来解答的思路:
一种步骤是:
- 创建一个栈。
- 遍历链表,将链表的每个节点的值依次入栈。
- 再次遍历链表,将链表的每个节点的值与栈顶元素进行比较。
- 如果值不相等,说明链表不是回文链表,返回 false。
- 如果值相等,继续比较下一个节点。
- 如果遍历完链表后都没有出现值不相等的情况,说明链表是回文链表,返回 true。
时间复杂度为 O(n),其中 n 是链表的长度。使用了一个栈来存储节点的值,因此空间复杂度为 O(n)
另一种步骤是:
- 遍历链表,将链表的每个节点的值依次插入双端队列的尾部。
- 然后,通过不断地从双端队列的头部和尾部取出元素进行比较,如果不相等,说明链表不是回文链表,返回 false。
- 最后,如果双端队列中还剩下一个元素或为空,则说明链表是回文链表,返回 true。
时间复杂度为 O(n),其中 n 是链表的长度。使用了一个双端队列来存储节点的值,因此空间复杂度为 O(n)
还一种步骤是:
- 先遍历第一遍,得到总长度。之后一边遍历链表,一边压栈。
- 到达链表长度一半后就不再压栈,而是一边出栈,一边遍历,一边比较,只要有一个不相等,就不是回文链表。这样可以节省一半的空间。
具体的代码就不全部展示了,只给出前两种的示例:
// 第一种方法
import java.util.Stack;
class ListNode {
int val;
ListNode next;
public ListNode(int val) {
this.val = val;
this.next = null;
}
}
public class Solution {
public boolean isPalindrome(ListNode head) {
if (head == null || head.next == null) {
return true; // 空链表或只有一个节点的链表都视为回文链表
}
Stack<Integer> stack = new Stack<>();
ListNode curr = head;
while (curr != null) {
stack.push(curr.val);
curr = curr.next;
}
curr = head;
while (curr != null) {
if (curr.val != stack.pop()) {
return false;
}
curr = curr.next;
}
return true;
}
}
// 第二种方法
import java.util.Deque;
import java.util.LinkedList;
class ListNode {
int val;
ListNode next;
public ListNode(int val) {
this.val = val;
this.next = null;
}
}
public class Solution {
public boolean isPalindrome(ListNode head) {
if (head == null || head.next == null) {
return true; // 空链表或只有一个节点的链表都视为回文链表
}
Deque<Integer> deque = new LinkedList<>();
ListNode curr = head;
while (curr != null) {
deque.offerLast(curr.val);
curr = curr.next;
}
while (deque.size() > 1) {
if (!deque.pollFirst().equals(deque.pollLast())) {
return false;
}
}
return true;
}
}
使用数组就是把链表装成数组,然后再判断,可以直接利用一层for循环判断,也可使用双指针法判断,这里我就用前者。(数组的资源消耗比栈要小很多)
具体代码如下:
class Solution {
public boolean isPalindrome(ListNode head) {
int len = 0;
// 统计链表长度
ListNode cur = head;
while (cur != null) {
len++;
cur = cur.next;
}
cur = head;
int[] res = new int[len];
// 将元素加到数组之中
for (int i = 0; i < res.length; i++){
res[i] = cur.val;
cur = cur.next;
}
// 比较回文
for (int i = 0, j = len - 1; i < j; i++, j--){
if (res[i] != res[j]){
return false;
}
}
return true;
}
}其他的解法等俺再学习学习!



















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











