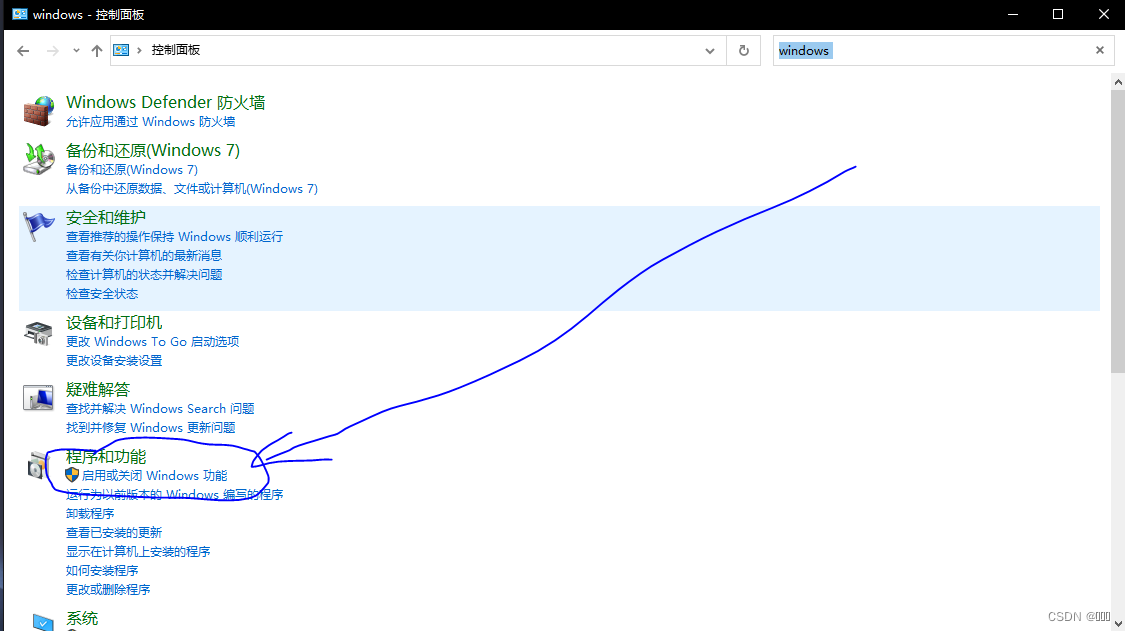
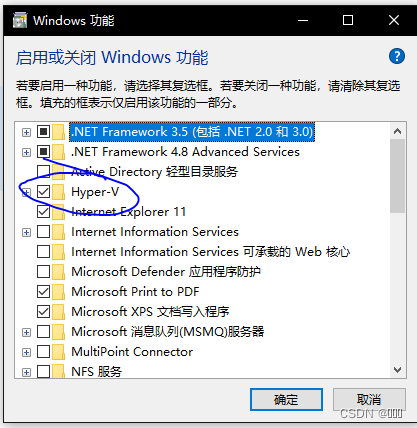
鸿蒙DevEco 本地模拟器不支持的CPU解决方法 问题描述解决方法 问题描述 打开本地模拟器点击按钮之后弹窗提示不支持的CPU 解决方法 打开控制面板 搜索Windows 找到程序和功能里的启动或关闭Windows功能 把Hyper-V勾选并重新启动即可 (如果没有这一项或者无法打开,要在主板BIOS中找到CPU的虚拟化选项,各品牌主板的方式不同,可以自行百度) 























 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






