






Tacotron详解
概述
Tacotron模型是首个真正意义上的端到端TTS深度神经网络模型。与传统语音合成相比,它没有复杂的语音学和声学特征模块,而是仅用<文本序列,语音声谱>配对数据集对神经网络进行训练,因此简化了很多流程。然后Tacotron使用Griffin-Lim算法对网络预测的幅度谱进行相位估计,再接一个短时傅里叶(Short-Time Fourier Transform,STFT)逆变换,实现端到端语音合成的功能。Tacotron的总体架构如下图:
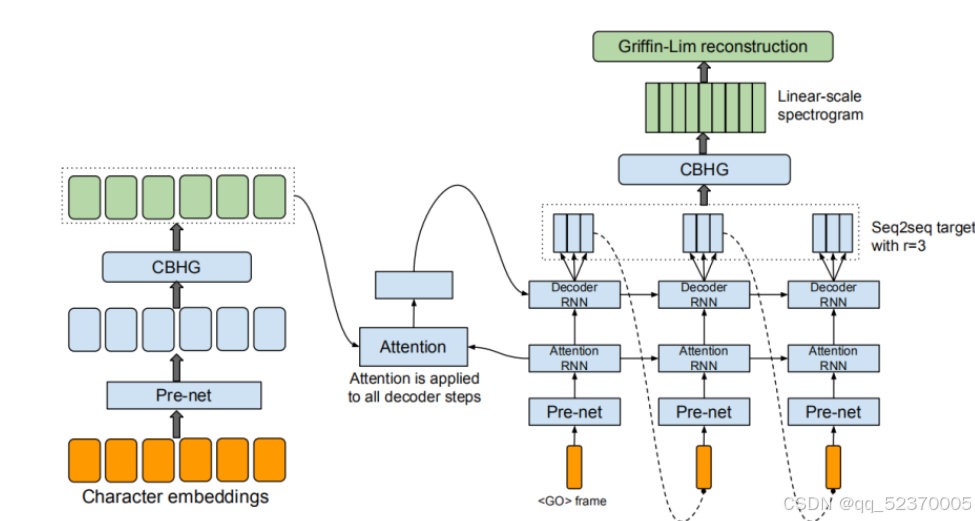
如上图所示,Tacotron是一个带有注意力机制(Attention Mechanism)的序列到序列(Sequence-To-Sequence,Seq2Seq)生成模型,包括一个编码器模块和一个带有基于内容注意力的解码器模块,以及后处理网络。编码器负责将输入文本序列的每个字符映射到离散的One-Hot编码向量,再编码到低维连续的嵌入形式(Embedding),用于提取文本的鲁棒序列表示。解码器负责将文本嵌入(Text Embedding)解码成语音帧,在Tacotron中使用梅尔刻度声谱作为预测输出;其中基于内容的注意力模块用于学习如何对齐文本序列和语音帧,序列中的每个字符编码通常对应多个语音帧并且相邻的语音帧一般也具有相关性。后处理网络用于将该Seq2Seq模型输出的声谱转换为目标音频的波形,在Tacotron中先将预测频谱的振幅提高(谐波增强),再使用Griffin-Lim算法估计相位从而合成波形。除此之外,Tacotron独到地描述了一个称为CBHG的模块,它由一维卷积滤波器(1D-Convolution Bank)、高速公路网络(Highway Network)、双向门控递归单元(Bidirectional GRU)和循环神经网络(Recurrent Neural Network,RNN)组成,被用于从序列中提取高层次特征。
左边的红框标记的是encoder模块,右边下半部分的红框是decoder模块,连接encoder模块和decoder模块的就是attention machanism,最后右边的上半部分是模型的post-processing net(后处理网络模块)。
3.1 encoder模块
encoder模块主要是为了得到输入文本的一个很好的表示,encode的输入是将文本转换为one-hot向量,然后经过一个pre-net的网络结构,接着讲pre-net网络的输出输入到CBHG模块中,最后从CBHG中输出的就是输入的text的一个健壮的表示序列。
下面分别对pre-net和CBHG的结构进行介绍。
3.1.1 pre-net结构
pre-net是一个3层的网络结构,其主要功能是对输入进行一系列的非线性的变换,这样有助于模型收敛和泛化。
它有两个隐藏层,层与层之间的连接均是全连接;第一层的隐藏单元数目与输入单元数目一致,第二层的隐藏单元数目为第一层的一半;两个隐藏层采用的激活函数均为ReLu,并保持0.5的dropout来提高泛化能力。
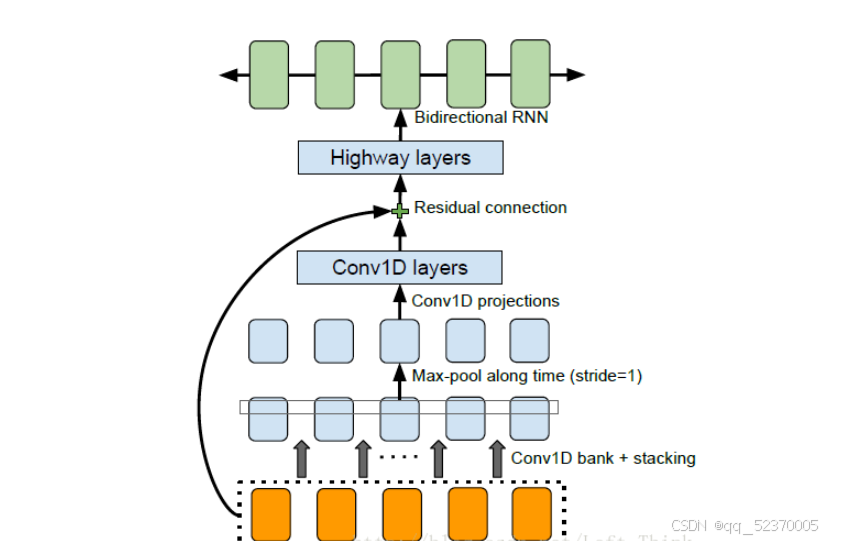
输入序列首先会经过一个卷积层,注意这个卷积层,它有K个大小不同的1维的filter,其中filter的大小为1,2,3…K。这些大小不同的卷积核提取了长度不同的上下文信息。然后,将经过不同大小的k个卷积核的输出堆积在一起(注意:在做卷积时,运用了padding,因此这k个卷积核输出的大小均是相同的)。下一层为最大池化层,stride为1,width为2。
经过池化之后,会再经过两层一维的卷积层。第一个卷积层的filter大小为3,stride为1,采用的激活函数为ReLu;第二个卷积层的filter大小为3,stride为1,没有采用激活函数(在这两个一维的卷积层之间都会进行batch normalization)。
经过卷积层之后,会进行一个residual connection。也就是把卷积层输出的和embeding之后的序列相加起来。然后输入到highway layers,highway nets的每一层结构为:把输入同时放入到两个一层的全连接网络中,这两个网络的激活函数分别采用了ReLu和sigmoid函数,假定输入为input,ReLu的输出为output1,sigmoid的输出为output2,那么highway layer的输出为:,文章中使用了4层highway layer。
decoder模块主要分为三部分:pre-net、Attention-RNN、Decoder-RNN。
pre-net的结构与encoder中的pre-net相同,主要是对输入做一些非线性变换。
Attention-RNN的结构为一层包含256个GRU的RNN,它将pre-net的输出和attention的输出作为输入,经过GRU单元后输出到decoder-RNN中。
decode-RNN为两层residual GRU,它的输出为输入与经过GRU单元输出之和。每层同样包含了256个GRU单元。第一步decoder的输入为0矩阵,之后都会把第t步的输出作为第t+1步的输入。
注意:由于每个字符在发音的时候,可能对应了多个帧,因此每个GRU单元输出为多个帧的音频文件,paper上说在decoder的每一步时,不仅仅预测1帧的数据,而是预测多个费重叠的帧。
这样的好处有:减少了训练模型的大小;减少了训练的时间;可以提高收敛的速度。

















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









