 端到端语音合成模型TACOTRON详解
端到端语音合成模型TACOTRON详解




 本文介绍了TACOTRON,一个2017年的端到端文本到语音合成模型,旨在简化传统多步骤的语音合成系统。TACOTRON直接从文本字符生成语音,通过CBHG编码器提取文本信息,并使用内容基注意解码器生成声音。相较于多步骤模型,端到端模型更健壮,减少错误积累。实验结果显示,TACOTRON在性能上优于参数化方法。
本文介绍了TACOTRON,一个2017年的端到端文本到语音合成模型,旨在简化传统多步骤的语音合成系统。TACOTRON直接从文本字符生成语音,通过CBHG编码器提取文本信息,并使用内容基注意解码器生成声音。相较于多步骤模型,端到端模型更健壮,减少错误积累。实验结果显示,TACOTRON在性能上优于参数化方法。
1 简介
本文根据2017年《TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS》翻译总结的。如题所述,是一个端到端的语音合成模型。
一个文本到语音的合成系统通常包括多个步骤,包括文本分析、声学模型、声音合成模块等。建立这些单元通常需要广泛的专业领域知识,可能包含脆弱的设计选择。本文,我们呈现了一个端到端的生成模型TACOTRON,直接从文本字符生成语音。给定<text,audio(声音)>,模型可以直接完全训练。
另外,一个单独的端到端模型会比多步骤模型更加健壮,多步骤模型的每个单元错误可能复合。
2 相关工作
WaveNet 是一个非常好的语音合成模型,但它比较慢,因为其样本水平的自回归特性。同时其再TTS前,需要语言特征的条件,所以不太是端到端的。
3 模型结构
如下图,由左边部分的encoder、中间部分的decoder、后处理网络和波形生成构成。
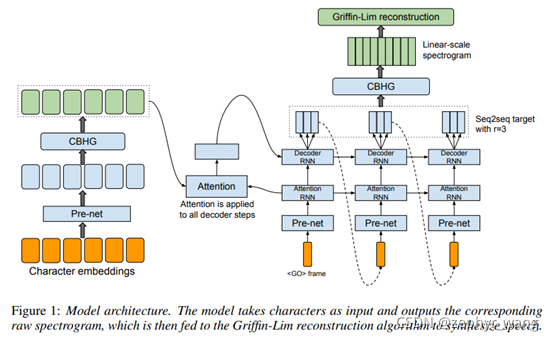
3.1 CBHG
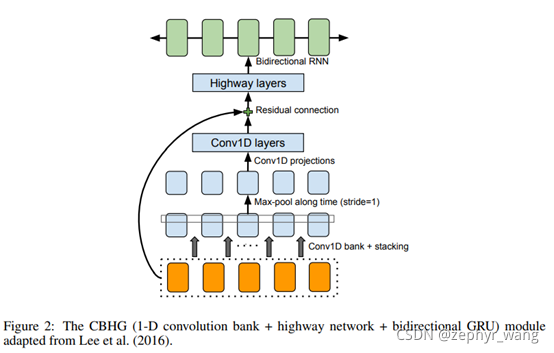
CBHG是从文本序列中提取表达信息,灵感来源于机器翻译。如上图,包括一组(bank)1-D卷积过滤器、highway layers、和bidirectional gated recurrent unit (GRU) (Chung et al., 2014) recurrent neural net (RNN)。highway layers提高高级别的特征。GRU RNN从两个方向(向前与向后)提取序列特征。
3.2 Encoder
Encoder是用来提取健壮的连续的文本表达。Encoder的输入是一个字符序列,其中每个字符用一个one-hot编码表达,然后embed到一个连续向量。然后应用一组非线性转换(我们陈为pre-net)到每个embedding。我们采用带有dropout的 bottleneck layer作为pre-net,这有助于收敛和提高泛化。CBHG将pre-net的输出转换为最终的encoder输出。
我们发现CBHG-based encoder 不仅减少了过拟合,而且比标准的多层RNN encoder产生较少的发音错误。
3.3 Decoder
我们使用content-based tanh attention decoder。使用了一系列带有垂直残差连接的GRU,有助于收敛。在每一个decoder步骤,预测多个、非重叠的输出frame。第一个decoder步骤是基于 frame.
3.4 POST-PROCESSING NET AND WAVEFORM SYNTHESIS
post-processing net将seq2seq的输出转换为可以合成声音波形的spectrogram。使用CBHG作为post-processing net。
我们采用Griffin-Lim算法将spectrogram合成声音波形。
4 实验结果
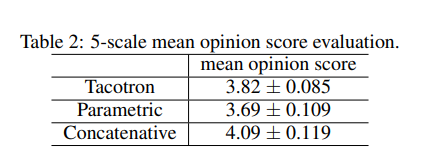
可以看到tacotron比parametric的方法表现较好。Tacotron是端到端的方法。


















 2272
2272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









